Command Palette
Search for a command to run...
신시대의 시각적 생성: 원자적 매핑에서 에이전트 세계 모델링으로의 진화
신시대의 시각적 생성: 원자적 매핑에서 에이전트 세계 모델링으로의 진화
초록
최근 시각 생성 모델은 사진과 같은 현실감, 타이포그래피, 지시사항 준수, 대화형 편집 분야에서 괄목할만한 진전을 이루었으나, 여전히 공간 추론, 지속적 상태 유지, 장기간 일관성, 인과적 이해 분야에서는 어려움을 겪고 있습니다. 본고에서는 해당 분야가 외형적 합성에 머무르는 것을 넘어, 구조, 역학, 도메인 지식, 인과 관계에 근거한 타당한 시각적 생성을 지향하는 지능형 시각 생성(Intelligent Visual Generation)으로 나아가야 한다고 주장합니다. 이러한 패러다임 전환을 체계화하기 위해 본고에서는 능동적 렌더링에서 상호작용형 에이전트 및 환경 인지형 생성자로 나아가는 다섯 단계의 분류 체계를 제안합니다. 해당 단계는 다음과 같습니다: 원자적 생성(Atomic Generation), 조건부 생성(Conditional Generation), 문맥 내 생성(In-Context Generation), 에이전트 생성(Agentic Generation), 월드 모델링 생성(World-Modeling Generation). 또한 흐름 일치(Flow Matching), 통합 이해-생성 모델, 개선된 시각 표현, 사후 학습(Post-training), 보상 모델링(Reward Modeling), 데이터 큐레이션, 합성 데이터 증류(Synthetic Data Distillation), 샘플링 가속화 등 주요 기술적 동력을 분석합니다. 더 나아가 기존 평가가 지각적 품질을 지나치게 강조함으로써 구조적, 시간적, 인과적 오류를 간과하고 있어 진전을 과대평가하고 있음을 보여줍니다. 벤치마크 검토, 현장 기반 스트레스 테스트, 전문가 제약 사례 연구를 결합한 본 로드맵은 차세대 지능형 시각 생성 시스템을 이해하고, 평가하며, 발전시키기 위한 능력 중심의 관점을 제시합니다.
One-sentence Summary
This roadmap outlines a research agenda for intelligent visual generation by introducing a five-level taxonomy ranging from Atomic Generation to World-Modeling Generation, analyzing technical drivers including diffusion-to-flow matching and preference-based post-training, and critiquing existing benchmarks through in-the-wild stress tests and expert-constrained visual case studies to prioritize structural and causal coherence over appearance synthesis.
Key Contributions
- This work introduces a five-level taxonomy spanning Atomic Generation to World-Modeling Generation to organize progress from passive rendering to interactive, world-aware systems. The framework clarifies capability improvements by nesting prior competencies and defining qualitatively new skills at each stage of the hierarchy.
- The study pairs benchmark reviews with in-the-wild stress tests and expert-constrained visual case studies to map specific failure modes to taxonomy levels. Results across spatial puzzles and physical reasoning demonstrate that current models remain fragile when correctness depends on exact structure or causal grounding.
- The paper outlines a research agenda for controllable and physically grounded systems by analyzing drivers such as diffusion-to-flow matching and synthetic data distillation. This roadmap provides a common language for understanding the trajectory from powerful generators to genuinely grounded visual intelligence.
Introduction
Recent visual generation models have achieved high photorealism and instruction following yet they continue to struggle with spatial reasoning, persistent state, and causal understanding. This limitation is critical because advancing toward intelligent visual generation requires systems grounded in structure and dynamics rather than simple appearance synthesis. To address this, the authors formalize the field's evolution through a five-level taxonomy ranging from atomic rendering to world-modeling generation. They leverage this framework to analyze technical drivers such as flow matching and unified architectures while introducing stress tests to expose failures in physical reasoning and long-horizon consistency.
Dataset

-
Dataset Composition and Sources
- The authors describe a shift from passive web scraping to active data engineering, combining real images, synthetic generation, and community content.
- Primary sources include large-scale web corpora like LAION-5B and COYO-700M, alongside specialized repositories such as MS COCO and Flickr.
- Editing datasets leverage user-generated content from Reddit (r/PhotoshopRequest) and temporal sequences from video corpora like InternVid.
- Structured data is derived from 3D assets (Objaverse) and code-executed graphics to ensure precise geometric and typographic ground truth.
-
Key Details for Each Subset
- Industrial pre-training pools often start with billions of images, such as HunyuanImage 3.0 (10B+ raw) or FireRed-Image-Edit (1.6B raw), before aggressive filtering.
- Retention rates vary significantly, with FireRed-Image-Edit keeping roughly 6% of raw samples and HunyuanImage 3.0 retaining under 45%.
- Synthetic subsets range from 91K frontier-quality samples (ShareGPT-4o-Image) to 6M filtered images (FLUX-Reason-6M).
- Community-sourced editing pairs include 48K requests from REALEdit and 83K from PSR, providing natural instruction distributions.
-
Model Training and Data Usage
- Data is utilized across a staged curriculum spanning pre-training, continued training, and supervised fine-tuning (SFT).
- Caption mixing strategies adjust over time, such as FireRed-Image-Edit shifting from 55% original/40% structured/5% instructive captions in pre-training to 10/45/45 during SFT.
- LongCat-Image employs multi-granularity captioning where photographic-level descriptions are sampled at 0.65 probability to prioritize world-knowledge density.
- Z-Image utilizes a five-type caption mix including long, medium, short, tags, and simulated user prompts to balance detail with inference behavior.
-
Processing and Metadata Construction
- Pipelines employ waterfall filtering that progresses from physical checks (resolution, aspect ratio) to semantic gates (CLIP alignment, aesthetic scoring).
- AIGC contamination filtering is now a structural quality control step, with models like LongCat-Image purging synthetic data from pre-training to prevent premature convergence.
- Vision-language models (VLMs) like Qwen2.5-VL and GPT-4o handle re-captioning, often generating structured JSON metadata or OCR-aware descriptions.
- Spatial supervision is constructed by converting 3D scans and web videos into box-centric data, while synthetic data engines use frontier model distillation to create high-fidelity training signals.
Method
The authors structure modern frontier visual generation systems around a unified architecture where text-to-image synthesis and image editing are treated as two data flows through the same model. This pipeline collapses the distinction between generation and editing into a single architecture composed of an encoder or tokenizer, a condition module, a generative backbone, and a decoder.
The encoder serves as the entry point, mapping raw pixels into a compact representation space where generation becomes computationally tractable. Continuous latent spaces via Variational Autoencoders (VAE) are standard for diffusion models, reducing dimensionality by factors of 64x. Autoregressive systems utilize discrete tokenizers like Vector Quantization (VQ) to map image patches to codebook entries for next-token prediction.
The backbone performs the heavy computation. Diffusion-based systems increasingly adopt Diffusion Transformers (DiT) or Modality-aware DiT (MM-DiT) architectures, which replace convolutional U-Nets to achieve predictable scaling with compute. Autoregressive backbones employ decoder-only transformers trained on next-token prediction, treating images as sequences of tokens.
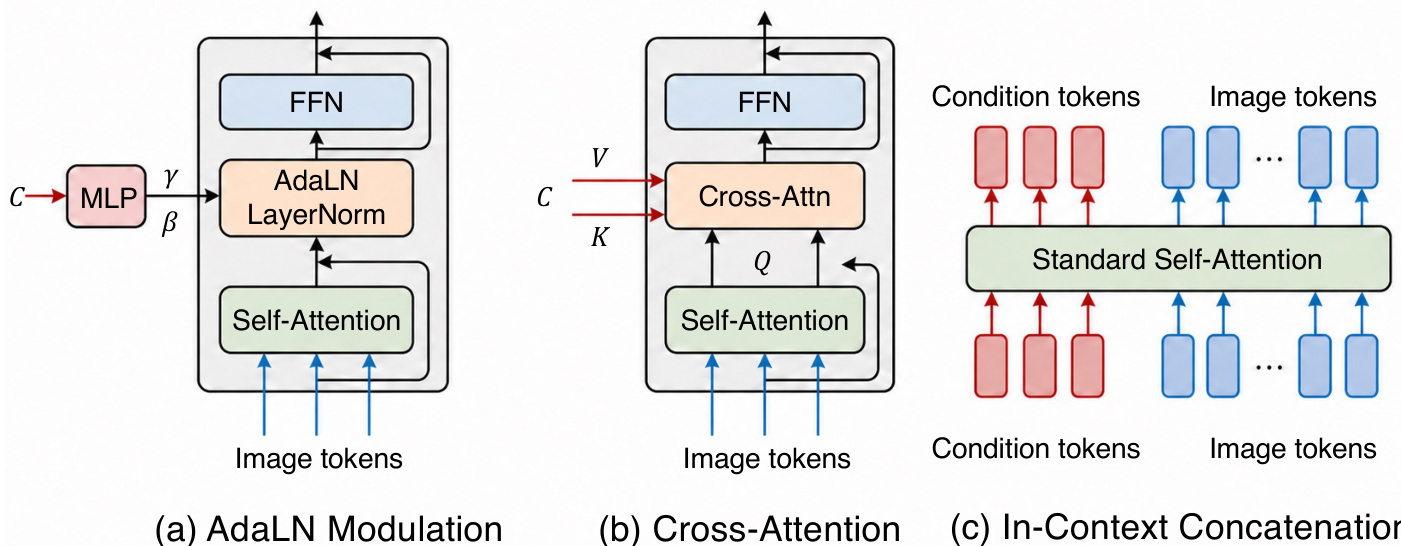
The condition module translates external control signals into features that steer the backbone. Modern injection mechanisms include Adaptive Layer Normalization (AdaLN) for global conditions, cross-attention for multimodal features, and in-context concatenation where condition tokens are prepended to the generation sequence.
Refer to the unified architecture diagram below for the data flow.
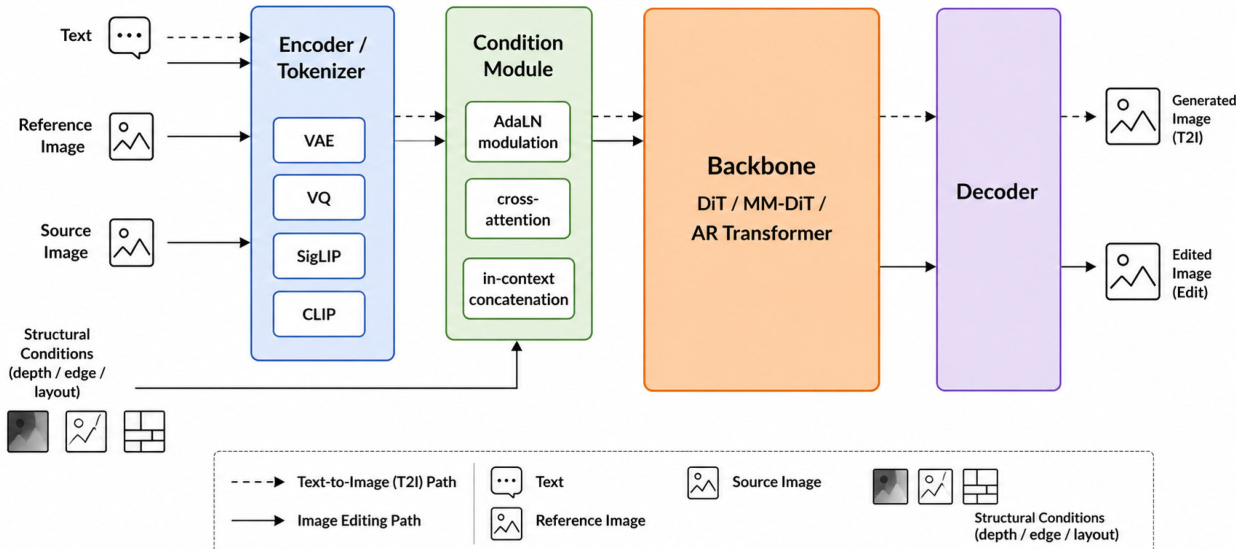
Condition injection routes vary by design. AdaLN modulates layer normalization parameters, cross-attention injects keys and values, and in-context concatenation processes condition and image tokens jointly via self-attention.
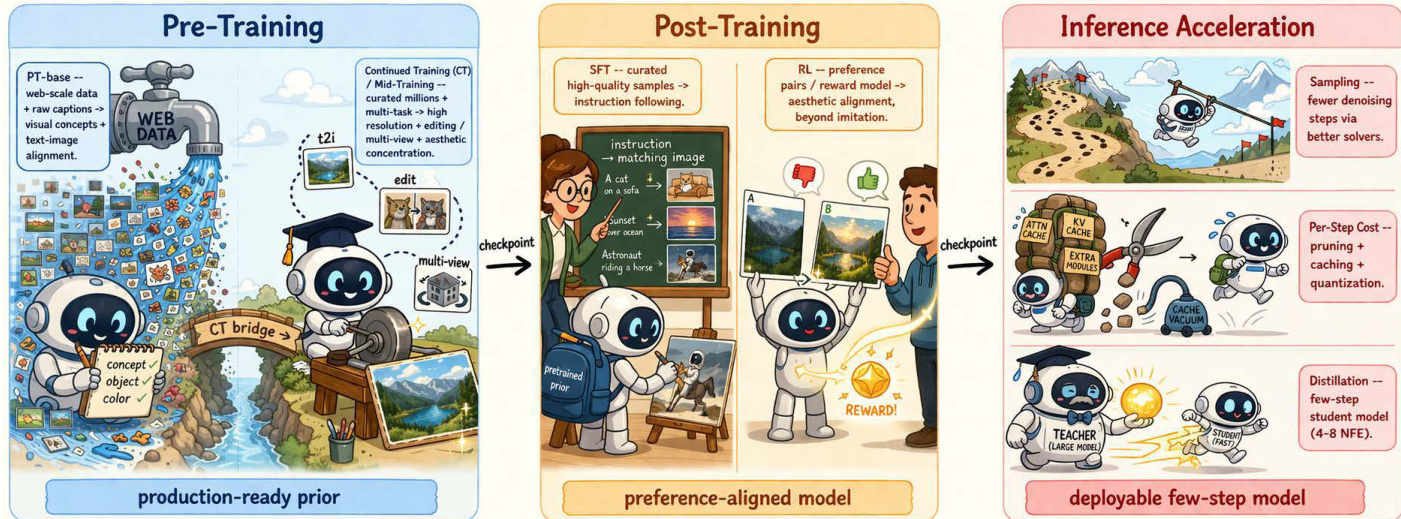
Training follows a multi-stage pipeline to establish capability and align with human intent. The process begins with pre-training on large-scale web data to learn broad visual priors. A continued-training stage then graduates the model to production resolutions and downstream tasks like editing. Post-training transforms the generator into a user-aligned system. Supervised Fine-Tuning (SFT) establishes baseline instruction following, while Reinforcement Learning (RL) optimizes for subjective preferences using reward models or direct preference optimization.
The RL objective can be formulated as maximizing expected reward while regularizing against the reference policy:
θmaxEx∼πθ[r(c,x)]−βDKL(πθ∣∣πref)Refer to the three-stage training pipeline overview below.
Inference acceleration is critical for deployment. Distillation techniques train student models to reproduce teacher quality in fewer steps. Strategies include trajectory matching, consistency models, and distribution matching.
Refer to the distillation families diagram.
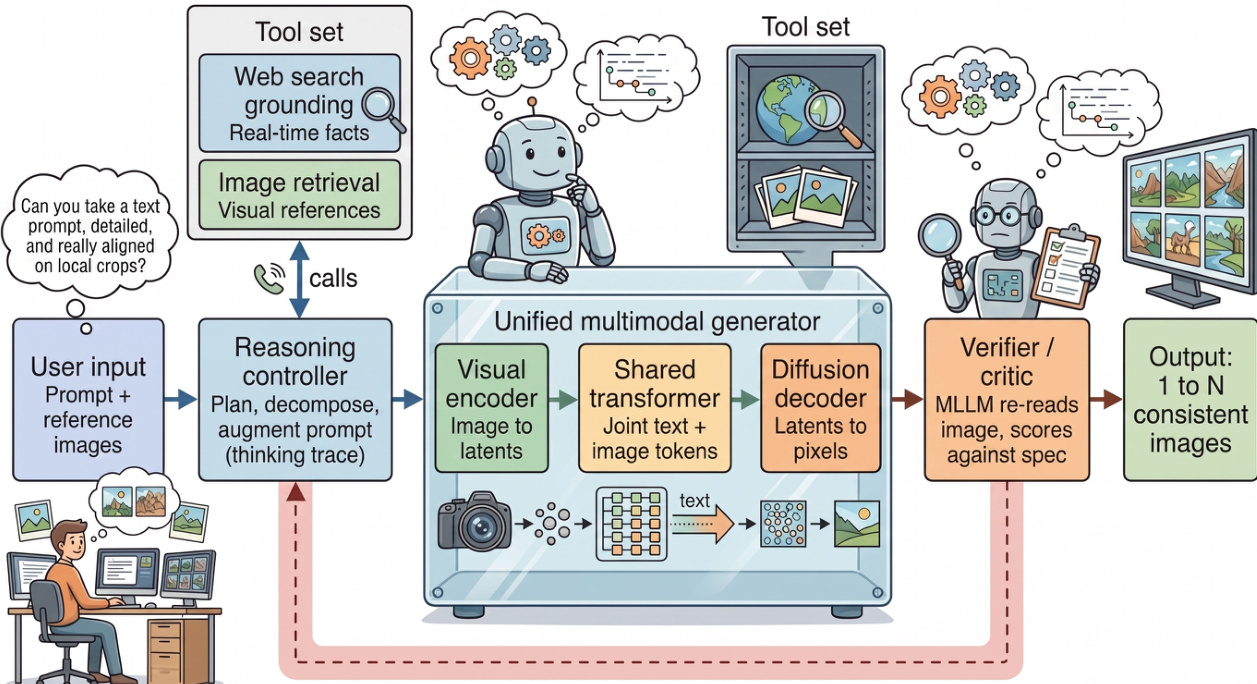
Beyond single-pass generation, advanced systems incorporate agent loops to handle complex, multi-turn tasks. These systems use a reasoning controller to plan, decompose, and verify tasks before rendering. A verifier or critic module scores outputs against specifications, triggering re-rendering if necessary. This architecture supports Level 4 Agentic Generation where the system manages control flow and tool use.
Refer to the speculative agent-loop architecture.
Experiment
This evaluation employs a five-level taxonomy to stress test models on spatial constraints, physical reasoning, and sequential editing. Findings reveal that while models excel at visual plausibility and proxy capabilities like text rendering, they often struggle to enforce strict geometric or causal logic. Furthermore, multi-turn editing demonstrates structural drift, and real-world applications show strong design synthesis alongside persistent limitations in fine-grained precision.