Command Palette
Search for a command to run...
공진화 정책 압축
공진화 정책 압축
Naibin Gu Chenxu Yang Qingyi Si Chuanyu Qin Dingyu Yao Peng Fu Zheng Lin Weiping Wang Nan Duan Jiaqi Wang
초록
RLVR(Reinforcement Learning with Verifiable Rewards)와 OPD(Off-policy Distillation)는 사후 훈련(post-training)의 표준 패러다임으로 자리 잡았다. 본 논문은 여러 전문가(expert)의 능력을 단일 모델로 통합하는 두 가지 패러다임을 통합적으로 분석하며, 각기 다른 방식으로 능력 손실(capability loss)이 발생함을 규명한다. 혼합된 RLVR(Mixed RLVR)은 상호 능력 간 분산 비용(inter-capability divergence cost)으로 인해 성능 저하가 발생하며, 전문가를 먼저 훈련한 후 OPD를 수행하는 파이프라인 방식은 분산은 피할 수 있으나 교사와 학생 간 행동 패턴의 큰 괴로 인해 교사의 능력을 충분히 흡수하지 못하는 한계가 있다.이에 본 연구는 공동 진화 정책 증류(Co-Evolving Policy Distillation, CoPD)를 제안한다. CoPD는 전문가들의 병렬 훈련을 장려하고, 기존과 달리 전문가 훈련이 완전히 완료된 후가 아닌 ongoing RLVR 훈련 단계 매번 OPD를 적용한다. 이 과정에서 전문가들은 상호 교사의 역할을 수행(즉, OPD를 양방향으로 작용하도록 함)하며 공동으로 진화한다. 이를 통해 전문가 간 행동 패턴의 일관성을 유지하면서도 충분한 보완적 지식(complementary knowledge)을 지속적으로 확보할 수 있다.실험 결과, CoPD는 텍스트, 이미지, 비디오 추론 능력을 모두 통합하는 all-in-one 통합을 달성하였으며, 혼합 RLVR이나 MOPD와 같은 강력한 기준 모델(stong baselines)을 크게 상회하고, 심지어 도메인 특화 전문가(domain-specific experts)보다도 우수한 성능을 보였다. CoPD가 제안하는 모델 병렬 훈련 패턴은 새로운 훈련 스케일링 훈련 패러다임에 영감을 줄 것으로 기대된다.
One-sentence Summary
The authors propose Co-Evolving Policy Distillation (CoPD), a post-training framework that parallelizes expert training while integrating bidirectional policy distillation into ongoing reinforcement learning to resolve inter-capability divergence and behavioral pattern gaps, ultimately achieving comprehensive text, image, and video reasoning that surpasses both established baselines and domain-specific experts, thereby suggesting a novel training scaling paradigm.
Key Contributions
- Co-Evolving Policy Distillation (CoPD) is introduced as a unified post-training framework that consolidates multiple expert capabilities into a single model by interleaving RLVR with mutual policy distillation.
- The training procedure executes bidirectional distillation during parallel expert optimization, enabling models to serve as mutual teachers that align behavioral patterns while preserving complementary knowledge.
- Empirical evaluations across text, image, and video reasoning tasks demonstrate that CoPD successfully integrates multimodal capabilities, significantly outperforming mixed RLVR and MOPD baselines while surpassing domain-specific expert models.
Introduction
Reinforcement learning with verifiable rewards and OPD have become standard post-training paradigms for consolidating specialized model capabilities into unified architectures. This approach matters because it enables efficient scaling of complex reasoning tasks across text, vision, and video domains. However, prior methods face inherent limitations: mixed reinforcement learning incurs inter-capability divergence costs, while sequential OPD pipelines suffer from large behavioral pattern gaps that prevent students from fully absorbing teacher expertise. The authors propose Co-Evolving Policy Distillation to overcome these bottlenecks by running parallel expert training and injecting distillation directly into each branch’s ongoing reinforcement learning loop. By treating expert models as mutual teachers during active optimization, the framework aligns behavioral patterns and preserves complementary knowledge throughout training. This co-evolutionary strategy successfully merges multimodal reasoning capabilities into a single model that outperforms both conventional baselines and standalone domain experts.
Dataset

- Dataset composition and sources: The provided excerpt does not list concrete datasets or external repositories. The authors use two abstract capability datasets, D1 and D2, to represent distinct optimization targets for a unified policy.
- Key details for each subset: No specific sizes, filtering rules, or source metadata are provided. The text treats D1 and D2 as theoretical constructs to analyze how separate capabilities interact during joint training.
- How the paper uses the data: The authors use D1 and D2 to compare three training paradigms. They evaluate mixed-data RLVR by jointly optimizing on the union of both datasets to measure gradient conflict, assess a static OPD pipeline by training experts in isolation and distilling them via on-policy trajectories, and introduce CoPD to alternate capability-specific RLVR with cross-branch mutual OPD. The datasets function as the total optimization signal X(D1,D2) that each paradigm attempts to convert into actual capability gains.
- Processing details: The excerpt does not describe data cropping, metadata construction, or preprocessing steps. The focus remains on mathematical modeling of gradient dynamics, teacher-student behavioral overlap, and utility functions rather than empirical data preparation.
Method
The authors propose Co-Evolving Policy Distillation (CoPD), a framework designed to enable multiple expert branches to co-evolve, thereby allowing each branch to explore its own capability while continuously transferring knowledge across domains. The core idea is to interleave branch-specific reinforcement learning with on-policy distillation (OPD) throughout training, ensuring that knowledge transfer remains effective by maintaining behavioral proximity between branches. The framework begins with a single base model, πθ, from which multiple parallel learning branches, πθj and πθk, are initialized with identical parameters, each associated with a distinct capability dataset, Dj and Dk. Training proceeds in alternating cycles, each composed of two phases: a branch-specific RLVR phase and a mutual OPD phase.
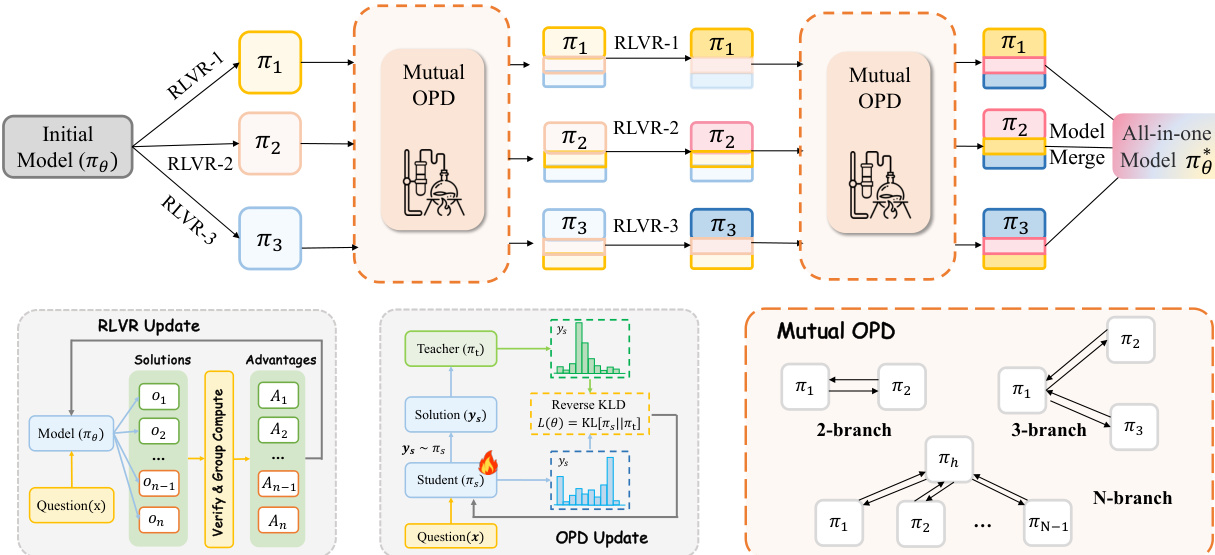
As shown in the figure below, the framework diagram illustrates the overall process. The initial model πθ is split into multiple branches, each undergoing RLVR on its own dataset. After a series of RLVR updates, the branches enter a mutual OPD phase, where they exchange knowledge. This alternating process continues for N cycles. The final step involves merging the co-evolved branches into a unified model, πθ∗, which benefits from the combined knowledge of all branches. The framework is scalable to more than two branches by adopting a hub-and-spoke topology, where a central hub branch exchanges knowledge with multiple spoke branches, as depicted in the figure.
During the branch-specific RLVR phase, each branch independently performs Group Relative Policy Optimization (GRPO) on its own capability data to deepen expertise. The RLVR objective for branch k is defined as:
LRLVR(k)(θk)=Ex∼Dk[G1i=1∑G∣yi∣1t=1∑∣yi∣min(ρi,t(k)A^iRL,clip(ρi,t(k),1−ϵ,1+ϵ)A^iRL)]where A^iRL and ρi,t(k) follow the standard GRPO formulation. This phase gradually drives the branches toward differentiated capability frontiers, creating a knowledge gap that can be exploited for cross-capability transfer.
In the mutual OPD phase, each branch generates on-policy rollouts on the other branch's data and receives token-level supervision. This allows for the transfer of newly acquired knowledge across capabilities. The process is symmetric, so both branches alternate between the roles of teacher and student at every step, continuously exchanging knowledge. The teacher signal for branch k receiving supervision from branch j is defined as:
δi,t(k←j)=logπθj(yi,t(k)∣x′,yi,<t(k))−logπθk(yi,t(k)∣x′,yi,<t(k))The token-level advantage for the cross-branch update is A^i,t(k)=βkδi,t(k←j), where βk balances the relative contribution of cross-branch distillation. Crucially, branch-specific RLVR does not pause during mutual OPD; instead, the two objectives are interleaved to update the model.

The alternating training procedure is summarized in Algorithm 1. Each cycle n consists of two phases: Phase I, where each branch performs SRL steps of GRPO on its own capability data, and Phase II, where each branch performs SOPD steps of mutual distillation. The hyperparameters SRL and SOPD determine the rhythm between the two phases. Larger SRL allows branches to accumulate more differentiated capability-specific discoveries during Phase I, providing richer signals for subsequent distillation. Larger SOPD leads to more thorough knowledge transfer during Phase II. Because all branches start from the same base model and remain tightly coupled through continuous mutual distillation, their parameters do not diverge drastically. The authors exploit this by applying simple parameter merging across branches to obtain the final unified model.
Experiment
A pilot study validates that distillation effectiveness scales with teacher-student behavioral overlap, while standard independent training systematically pushes experts into a low-overlap regime that severely hinders knowledge transfer. To resolve this limitation, CoPD is evaluated across text, image, and video reasoning benchmarks against static and mixed baselines. The experiments demonstrate that concurrent mutual distillation successfully maintains optimal behavioral alignment throughout training, enabling simultaneous capability enhancement across all domains without the interference or incomplete transfer characteristic of static pipelines. Further analysis confirms that alternating specialized exploration with continuous consolidation is essential for sustaining high overlap and maximizing overall model performance.
{"summary": "The authors present a method called CoPD that improves performance in multi-modal reasoning by co-evolving text and image branches through alternating exploration and mutual distillation. Results show that CoPD achieves the best overall performance across benchmarks, outperforming both single-expert and static distillation approaches, and maintains high behavioral overlap between branches throughout training. The method effectively balances specialization and consolidation, avoiding the capability divergence seen in other methods.", "highlights": ["CoPD achieves the highest overall performance across image and text reasoning benchmarks compared to all baselines.", "CoPD maintains high behavioral overlap between branches during training, unlike static methods that exhibit increasing divergence.", "The method's effectiveness is attributed to alternating exploration and mutual distillation, which balances specialization and consolidation."]
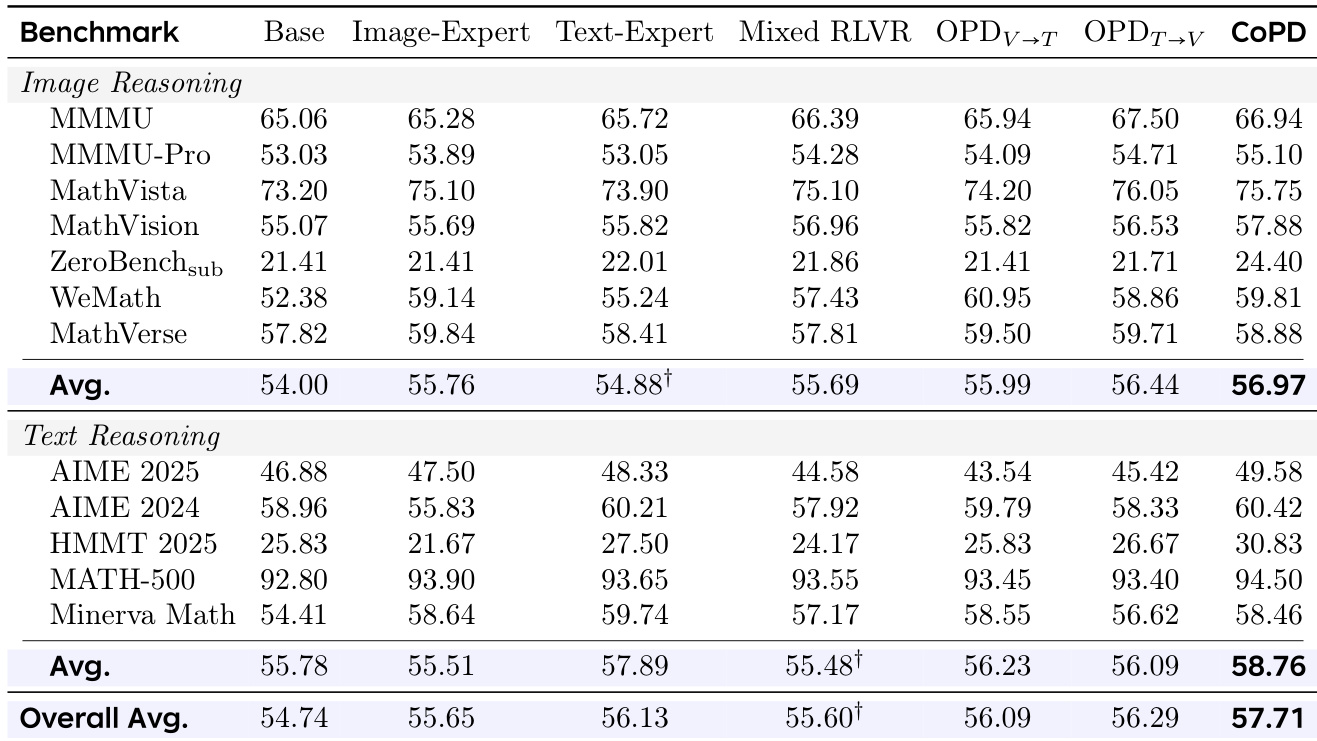
The authors compare CoPD against baselines in multi-domain reasoning tasks, showing that CoPD achieves superior performance by maintaining behavioral consistency between branches during training. Results demonstrate that CoPD outperforms static distillation and single-branch methods, with mutual OPD and merging contributing to balanced capability consolidation. The method sustains high overlap and low divergence between branches throughout training, avoiding the performance degradation seen in isolated expert training. CoPD achieves the best overall performance across image and text reasoning benchmarks compared to baselines. Mutual OPD and merging are essential for maintaining behavioral consistency and achieving balanced capability consolidation. CoPD sustains high branch overlap and low divergence during training, unlike static methods that experience significant divergence.

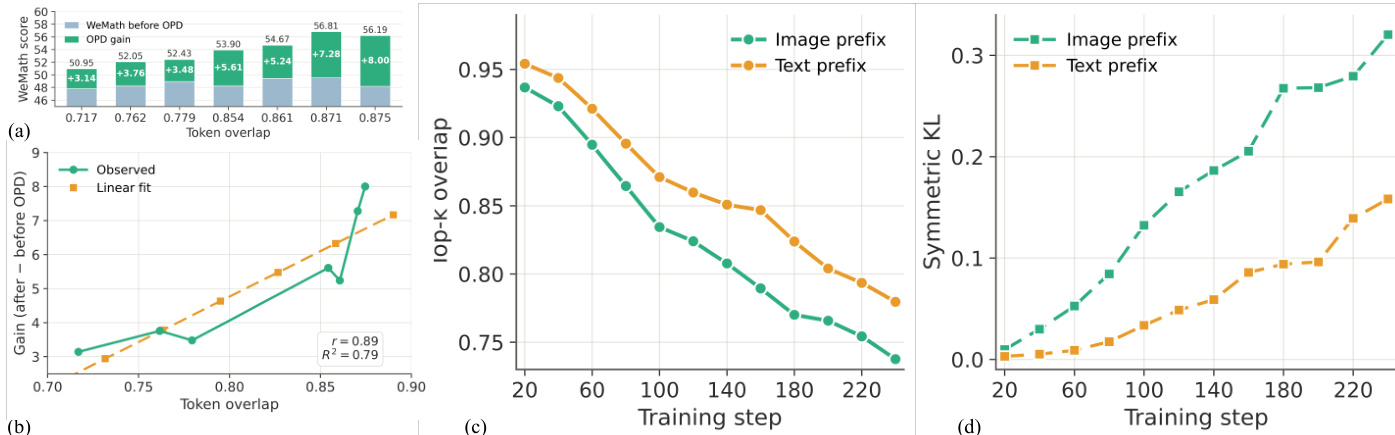
The authors conduct experiments to analyze the relationship between teacher-student behavioral overlap and distillation effectiveness, showing that higher overlap correlates with greater gains from distillation. They demonstrate that standard training methods lead to increasing divergence between experts and a shared base, resulting in low distillation efficiency, while their proposed method maintains optimal overlap and enables effective knowledge transfer through continuous co-evolution. Distillation gain increases with higher behavioral overlap between teacher and student. Standard training causes increasing divergence between experts and the base model, reducing distillation effectiveness. The proposed method maintains high behavioral overlap and enables effective mutual distillation through continuous co-evolution.
The authors conduct experiments to evaluate the effectiveness of their CoPD method in consolidating capabilities across multiple reasoning domains. Results show that CoPD outperforms baselines, including static distillation and mixed training, by maintaining a balance between specialization and alignment during training. The method achieves superior performance in image, text, and video reasoning without sacrificing individual domain capabilities. The ablation study confirms that mutual distillation and merging are critical for the overall improvement. CoPD achieves the best overall performance across image, text, and video reasoning benchmarks compared to all baselines. The method maintains high behavioral overlap between branches during training, preventing the drift observed in static pipelines. Mutual distillation and merging are essential components for achieving balanced and consolidated capabilities in CoPD.
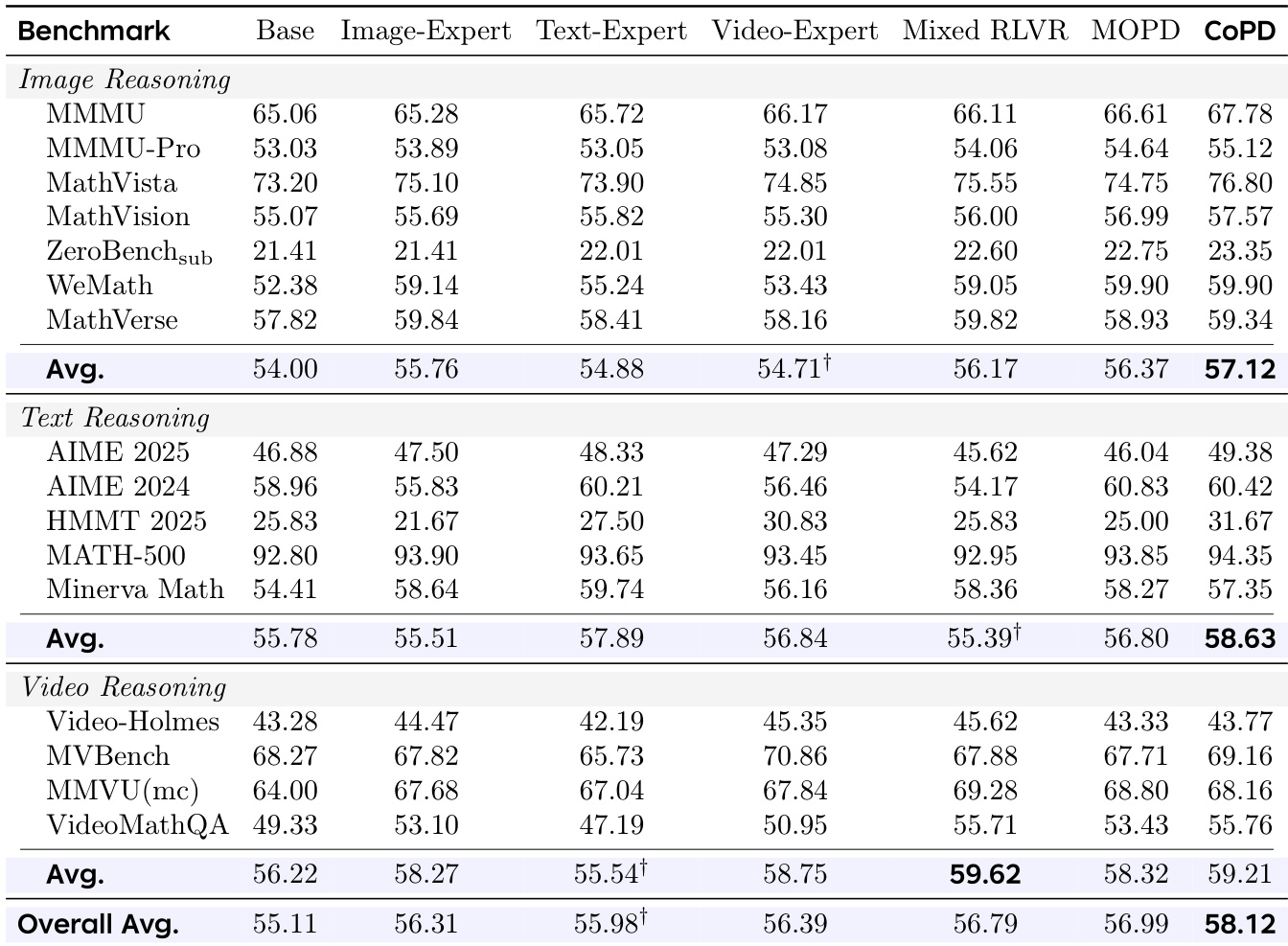
The authors conduct experiments to evaluate a co-evolutionary distillation method, showing that maintaining behavioral overlap between teacher and student models during training improves knowledge transfer. Results demonstrate that the proposed method outperforms baselines by sustaining higher overlap and lower divergence between branches throughout training, leading to better overall performance on image and text reasoning tasks. The proposed method maintains high behavioral overlap between branches during training, contrasting with baselines where overlap decreases over time. The method achieves superior performance on both image and text reasoning by balancing specialization and consolidation through alternating training phases. Results show that mutual distillation in both directions is necessary for optimal performance, with co-evolution improving capabilities beyond what single-branch models achieve.
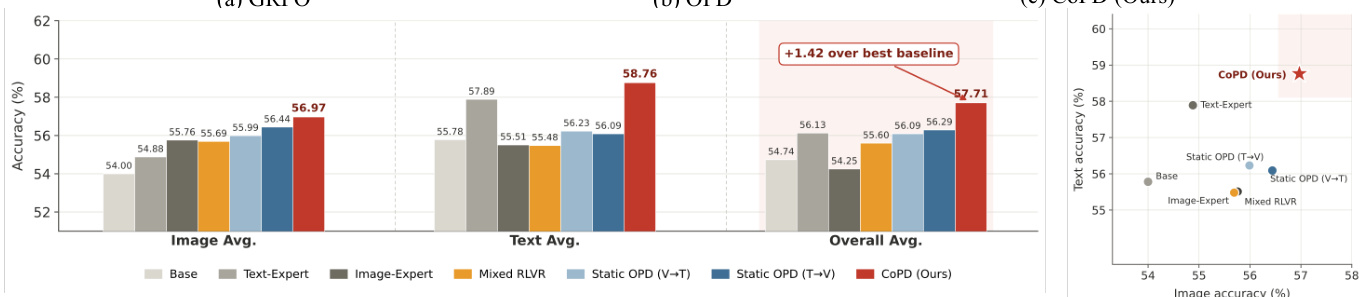
The experiments compare CoPD against static and single-branch baselines across multiple reasoning benchmarks to validate the impact of continuous co-evolution on knowledge transfer. Initial evaluations confirm that the method maintains high behavioral overlap between branches, effectively preventing the capability divergence typical of isolated training pipelines. Subsequent analyses demonstrate that alternating exploration with mutual distillation successfully balances specialization and consolidation, directly correlating with improved distillation efficiency. Overall, the results establish that synchronized multi-modal development consistently outperforms conventional approaches by enabling robust and stable knowledge sharing.