Command Palette
Search for a command to run...
RADIO-ViPE: 동적 환경에서 오픈 어휘 Semantic SLAM을 위한 온라인 조밀 다중 모달 융합
RADIO-ViPE: 동적 환경에서 오픈 어휘 Semantic SLAM을 위한 온라인 조밀 다중 모달 융합
Zaid Nasser Mikhail Iumanov Tianhao Li Maxim Popov Jaafar Mahmoud Sergey Kolyubin
초록
우리는 RADIO-ViPE(Reduce All Domains Into One -- Video Pose Engine)라는 온라인 의미론적 SLAM 시스템을 제시합니다. 이 시스템은 동적 환경에서 임의의 자연어 쿼리를 국소화된 3D 영역 및 개체와 연결하여, 기하학적 정보를 인지하는 오픈 보캐불러리 기반 지상화(open-vocabulary grounding)를 가능하게 합니다. 기존 접근법들이 보정된 posed RGB-D 입력 데이터를 필요로 하는 것과 달리, RADIO-ViPE는 사전 카메라 내부 파라미터(intrinsics), 심도 센서 또는 초기 자세(posse) 설정 없이도 원시 단안 RGB 비디오 스트림에서 직접 동작합니다. 본 시스템은 RADIO와 같은 집합적 기반 모델(agglomerative foundation models)에서 유도된 비전과 언어를 아우르는 다중 모드 임베딩을 장면의 기하학적 정보와 긴밀하게 결합합니다. 이러한 결합은 초기화, 최적화 및 팩터 그래프 연결 단계에서 이루어지며, 이를 통해 다양한 모드 간의 맵 일관성을 향상시킵니다. 최적화 과정은 적응형 강건 커널(adaptive robust kernels) 내에 포장되어, 능동적으로 움직이는 객체와 에이전트에 의해 이동된 장면 요소(예: 자기중심적 세션 동안 재배치된 가구) 모두를 처리할 수 있도록 설계되었습니다. 실험 결과, RADIO-ViPE는 보정된 데이터와 정적 장면 가정에 의존하는 오프라인 오픈 보캐불러리 방법들과 경쟁력 있는 성능을 유지하면서도, 동적 TUM-RGBD 벤치마크에서 최상단(state-of-the-art) 결과를 달성했습니다. RADIO-ViPE는 자율 로봇 및 제약 없는 실외 비디오 스트림에 대해 강건한 오픈 보캐불러리 기반 의미론적 지상화를 가능하게 함으로써, 실제 세계 배포에서 중요한 격차를 해소합니다. 프로젝트 페이지: https://be2rlab.github.io/radio_vipe
One-sentence Summary
RADIO-ViPE is an online semantic SLAM system that tightly couples vision-language embeddings from foundation models with geometric scene information using adaptive robust kernels, enabling open-vocabulary grounding in dynamic environments from raw monocular video without calibrated intrinsics while achieving state-of-the-art results on the dynamic TUM-RGBD benchmark.
Key Contributions
- This work presents RADIO-ViPE, an online semantic SLAM system that enables geometry-aware open-vocabulary grounding by associating natural language queries with localized 3D regions in dynamic environments.
- The framework processes raw monocular RGB video without calibrated intrinsics, depth sensors, or pose initialization, and tightly couples vision-language embeddings with geometric data using adaptive robust kernels to handle moving objects and scene rearrangements.
- Experiments on the dynamic TUM-RGBD benchmark demonstrate state-of-the-art performance while maintaining competitive results against offline open-vocabulary methods that rely on calibrated data and static scene assumptions.
Introduction
General-purpose robots need to ground free-form language queries onto 3D geometric maps to perform flexible, language-driven tasks in unstructured environments. Existing solutions exhibit critical trade-offs: geometric SLAM pipelines lack semantic awareness or rely on closed object taxonomies, while offline open-vocabulary methods ignore real-time odometry and assume static scenes. Real-time open-vocabulary SLAM systems often fail to handle dynamic disturbances, and many approaches require calibrated inputs or depth sensors, restricting deployment to controlled settings. The authors introduce RADIO-ViPE, an online semantic SLAM system that ingests raw, uncalibrated monocular RGB video to produce geometry-aware open-vocabulary maps without depth priors or pose initialization. They leverage agglomerative foundation models to tightly couple vision-language embeddings with geometric constraints within a dense bundle adjustment framework. The system employs a temporally consistent adaptive robust kernel that jointly optimizes reprojection errors and semantic discrepancies to filter out moving agents and quasi-static scene changes. This unified approach enables robust, real-time language grounding in dynamic environments, advancing the deployment of autonomous robotics in unconstrained scenarios.
Method
RADIO-ViPE is a unified, online semantic SLAM system designed to operate from uncalibrated monocular RGB video streams, integrating camera pose optimization, depth estimation, and dense high-level visual embeddings within a sliding window factor graph framework. The overall pipeline, illustrated in the system overview diagram, operates at approximately 8–10 FPS and leverages adaptive kernels to enhance robustness in dynamic environments. The system begins with camera initialization, where intrinsics are bootstrapped from uniformly sampled frames using GeoCalib, requiring no calibration targets or known camera models, and are subsequently co-optimized during bundle adjustment. Keyframe selection is driven by relative motion estimated via weighted dense optical flow, with frames exceeding a motion threshold designated as keyframes and added to the factor graph G=(V,E), where V represents keyframes and E denotes pairwise connections.
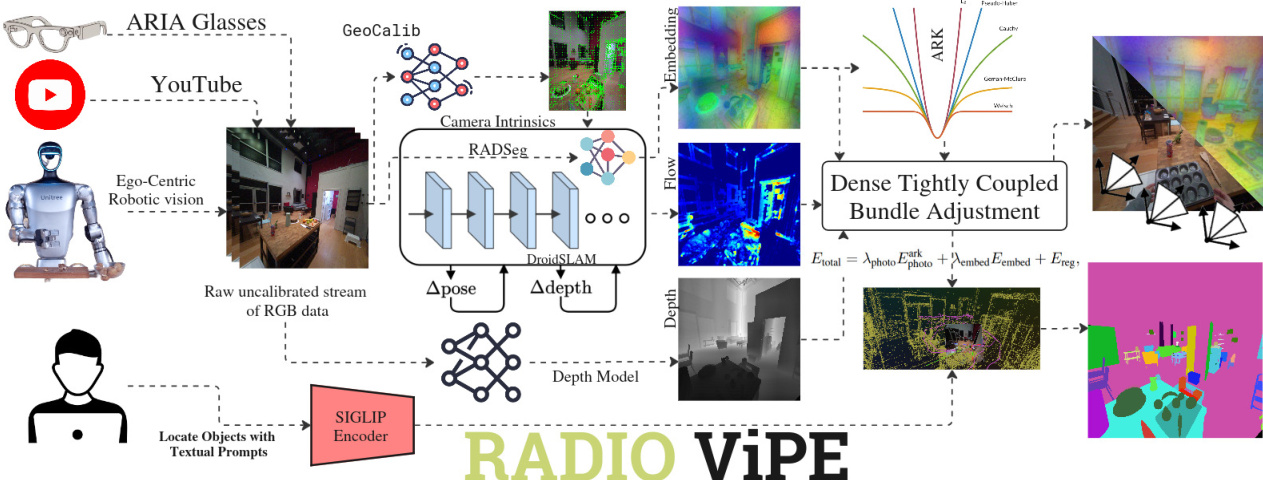
Dense multi-modal embeddings are extracted per keyframe using RADSeg, a model that generates language-aligned features within the SigLIP embedding space. These embeddings are upsampled via bilinear interpolation to a resolution of (H/8,W/8) and compressed to D=256 dimensions using Principal Component Analysis (PCA), ensuring scalability and efficient memory management. This PCA compression is applied directly to the encoder feature space, preserving structural integrity crucial for spatial reasoning. The PCA components are computed during the initialization phase of bundle adjustment, once a sufficient buffer of keyframes is collected, to ensure a robust and representative mapping.
Metric depth maps are estimated per keyframe using monocular foundation depth models, converted to inverse depth (disparity) for numerical stability, and downsampled by a factor of 8 to match the resolution of the optical flow. To improve the robustness of optical flow priors in textureless regions, a semantic correspondence term derived from dense RADIO features is introduced. For each pixel u in frame i, cosine similarities between the PCA-compressed Radio embedding Zi(u)∈RK and embeddings of pixels in the target frame are computed, yielding a dense semantic flow field Ωsem(u). This semantic prior is fused with the photometric flow prior via per-pixel confidence-based blending:
Ωprior(u):=βΩprior(u)+(1−β)Ωsem(u).The blending weight β balances the photometric flow confidence against the peak semantic similarity score. The blended initialization replaces Ωprior when constructing the correlation volume for the photometric flow term, leaving the flow network architecture unchanged.
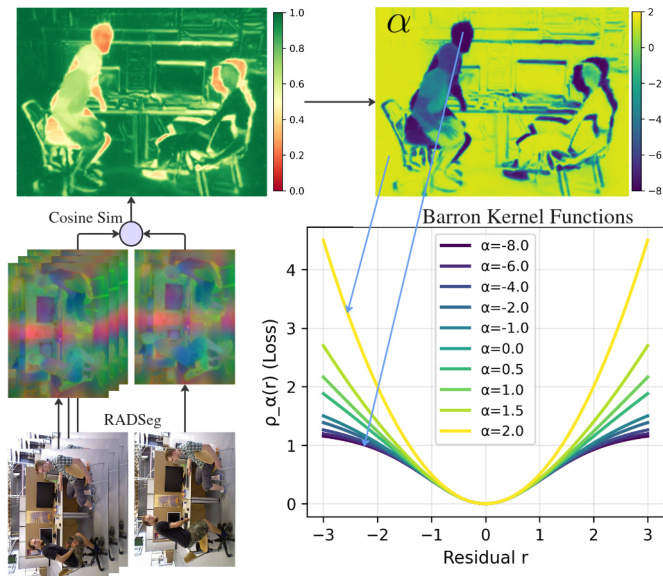
Bundle adjustment refines camera intrinsics, poses, and 3D scene structure by minimizing a vision-language-geometric energy function. The factor graph connectivity is augmented beyond geometric proximity using embedding-based co-visibility: a global descriptor per keyframe is obtained by mean-pooling its RADSeg embeddings and ℓ2-normalizing the result. Incoming keyframes are matched against non-recent keyframes (excluding the most recent τ frames) via a single cosine-similarity query; pairs exceeding a threshold η are linked by bidirectional edges. The optimization includes a dense photometric flow term, enforcing geometric consistency via optical flow constraints. For each edge (i,j), pixels u in frame i are projected into frame j as:
μij=Πj(TjTi−1∘Πi−1(u, di(u))),where Πq and Πq−1 denote projection and unprojection functions under intrinsics Kq. An optical flow network predicts a residual dense flow field Ωij∈RH×W×2 and per-pixel confidence weights w(u), with the prior flow estimate Ωijprior=μij−u initializing a correlation volume. The photometric term is:
Ephoto=u∑w(u)⋅Ωijprior−Ωij(u)2.A novel embedding similarity term is introduced to enforce cross-view feature alignment under geometric constraints. For each edge (i,j), source pixel u∈Ii is projected into the target frame to locate its corresponding pixel v=Pi,j(u)∈Ij, and the target embedding is recovered via bilinear interpolation. After ℓ2-normalizing both embeddings, the cosine similarity is computed:
csij(u)=∣∣Zi(u)∣∣⋅ ∣∣Z^j(Pi,i(u))∣∣Zi(u)⊤Z^j(Pi,j(u)),and the embedding residual is cast in photometric form:
rembed(u)=λembed2(1−csij(u)),with λembed=2. The full embedding similarity term is:
Eembed=u∑w(u)⋅rembed2(u).Non-keyframe pose estimation is achieved by connecting each non-keyframe to its two nearest keyframes via unidirectional edges, with poses recovered through photometric alignment, bypassing per-frame depth estimation and enabling parallel estimation. Open-vocabulary grounding is realized by decoding the compressed Radio features of 3D points and projecting them into SigLip latent space for matching with text queries. The system's design enables real-time performance and robustness in dynamic environments, as demonstrated in the final visualization.
Experiment
The proposed pipeline is evaluated on the TUM-RGBD dataset to assess robustness in dynamic environments and on the Replica dataset to validate real-time open-vocabulary semantic segmentation. Experiments demonstrate that the embedding error term and adaptive robust kernel effectively compensate for motion-induced tracking errors, outperforming existing dynamic SLAM methods while requiring substantially fewer computational resources. Additionally, the system successfully constructs semantically aware maps without relying on calibrated poses, depth inputs, or point clouds, maintaining accuracy levels comparable to methods that utilize ground-truth geometric supervision. Overall, the approach proves highly efficient and robust for simultaneous localization and semantic mapping, though it currently shows limitations when segmenting structural elements in complex backgrounds.
The authors evaluate their method, RADIO-ViPE, on SLAM performance using the TUM-RGBD dataset, comparing it against several existing approaches. Results show that RADIO-ViPE achieves competitive or superior performance across multiple metrics, particularly in terms of average trajectory accuracy, and outperforms other methods in specific configurations. RADIO-ViPE achieves top performance in average trajectory accuracy compared to other methods on the TUM-RGBD dataset. The method performs competitively across various configurations, with notable results in both dynamic and static scenarios. RADIO-ViPE outperforms several existing SLAM approaches, including ViPE and DGS-SLAM, in key metrics such as average trajectory accuracy.
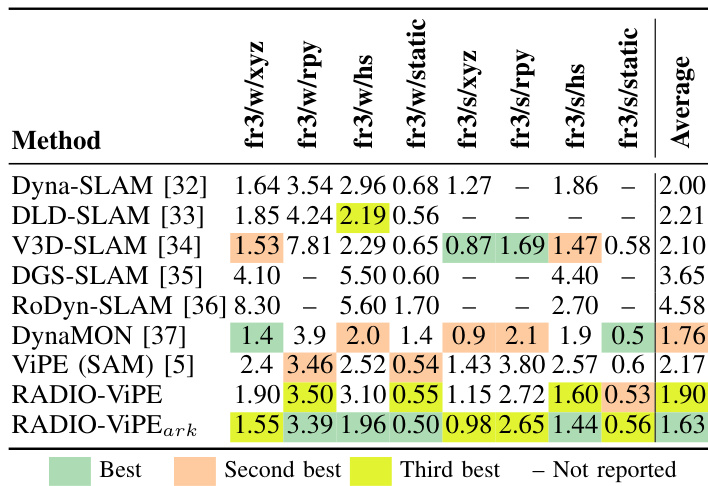
The authors evaluate RADIO-ViPE on semantic segmentation and SLAM tasks, comparing it against existing methods on Replica and TUM-RGBD datasets. The results show that RADIO-ViPE achieves competitive performance in both tasks, particularly in semantic segmentation where it ranks among the top methods without requiring geometric supervision such as depth, pose, or calibration inputs. RADIO-ViPE achieves top-3 performance in semantic segmentation on Replica without relying on ground-truth depth, pose, or calibration inputs. RADIO-ViPE outperforms existing dynamic SLAM methods in terms of average ATE on TUM-RGBD sequences. Unlike other methods, RADIO-ViPE operates online and supports open-vocabulary segmentation without requiring known camera parameters or pre-defined classes.
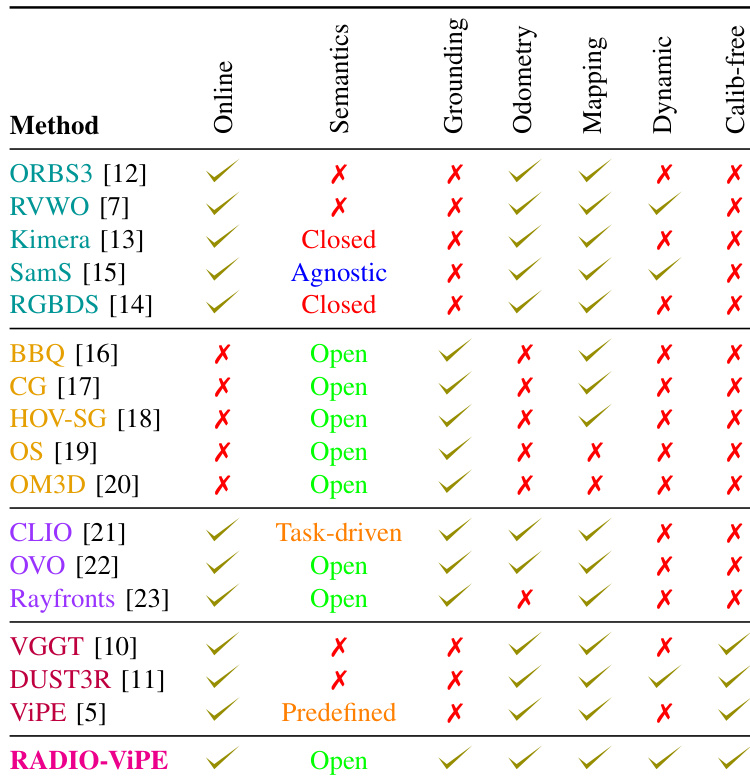
The authors evaluate their proposed method, RADIO-ViPE, on semantic segmentation and SLAM tasks, comparing it against several baseline approaches. Results show that RADIO-ViPE achieves competitive performance with existing methods, particularly in terms of accuracy and real-time operation, while operating without the need for calibration, depth, or pose inputs. The method maintains high accuracy even when removing ground-truth depth, pose, and calibration, indicating strong robustness and effectiveness in real-world settings. RADIO-ViPE achieves top-3 performance on semantic segmentation benchmarks without requiring known camera parameters, poses, or depth inputs. The method maintains high accuracy with minimal degradation when removing ground-truth depth, pose, and calibration, demonstrating robustness. RADIO-ViPE supports online inference and operates without calibration, depth, or pose inputs, unlike most compared approaches.
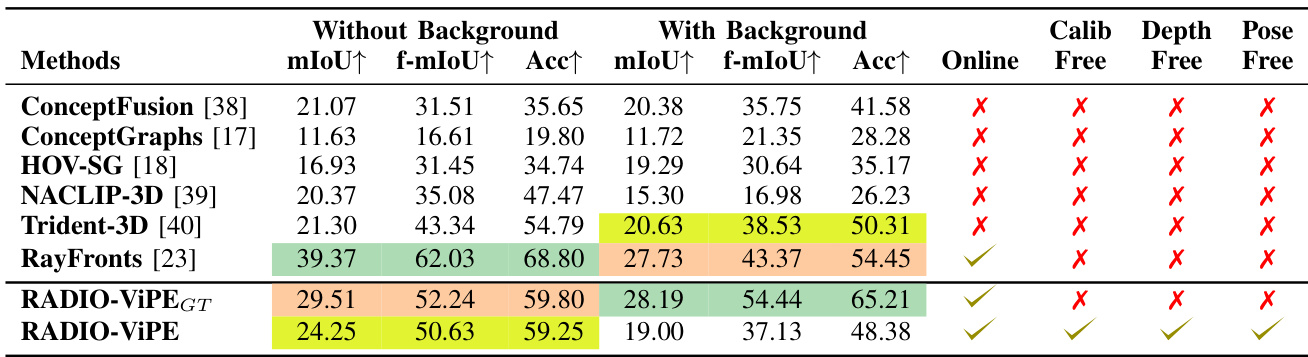
The authors evaluate RADIO-ViPE on the TUM-RGBD and Replica datasets to assess its simultaneous localization and mapping capabilities alongside semantic segmentation, benchmarking the approach against several established baselines. These experiments validate that the method maintains robust and competitive accuracy across both static and dynamic environments while operating entirely without ground-truth depth, camera pose, or intrinsic calibration inputs. The results demonstrate that RADIO-ViPE delivers reliable real-time performance and open-vocabulary segmentation, establishing it as a practical, calibration-free framework that removes the dependency on explicit geometric supervision or predefined object categories.