Command Palette
Search for a command to run...
Diffusion Templates: 제어 가능한 diffusion을 위한 통합된 플러그인 프레임워크
Diffusion Templates: 제어 가능한 diffusion을 위한 통합된 플러그인 프레임워크
Zhongjie Duan Hong Zhang Yingda Chen
초록
제어 가능한 확산(diffusion) 방식은 확산 모델의 실용성을 크게 확장했으나, 이러한 방식들은 일반적으로 분리된 백본(backbone) 특화 시스템으로 개발되어 호환되지 않는 학습 파이프라인, 파라미터 형식 및 런타임 훅(runtime hooks)을 특징으로 한다. 이로 인해 태스크 간 인프라 재사용, 백본 간 능력 이전, 단일 생성 파이프라인 내 다중 제어의 조합이 어려워진다. 본 논문에서는 기본 모델 추론(inference)과 제어 가능성 주입을 분리하는 통합형 오픈 플러그인 프레임워크인 ‘Diffusion Templates’를 제시한다. 이 프레임워크는 세 가지 구성 요소로 조직된다. 첫째, 임의의 태스크별 입력을 중간 능력 표현(intermediate capability representation)으로 매핑하는 템플릿 모델입니다. 둘째, 능력 주입을 위한 표준화된 인터페이스 역할을 하는 템플릿 캐시(Template cache)입니다. 셋째, 하나 이상의 템플릿 캐시를 기본 확산 런타임에 로드, 병합 및 주입하는 템플릿 파이프라인입니다. 이 인터페이스는 특정 제어 아키텍처에 묶이지 않고 시스템 레벨에서 정의되므로, KV-Cache와 LoRA와 같은 이질적인 능력 운반체(capability carriers)를 동일한 추상화 레이어에서 지원할 수 있다. 이러한 설계를 바탕으로 구조적 제어, 밝기 조절, 색상 조정, 이미지 편집, 슈퍼Resolution, 선명도 향상, 미적 정렬, 콘텐츠 참조, 지역적 인페인팅(local inpainting), 나이 제어 등을 포괄하는 다양한 모델 집합(Zoo)을 구축했다. 이러한 사례 연구들은 Diffusion Templates가 빠른 진화를 거듭하는 확산 백본에 걸쳐 모듈성, 조합성(composability), 실용적인 확장성을 유지하면서 광범위한 제어 가능한 생성 태스크를 통합할 수 있음을 보여준다. 코드, 모델, 데이터셋을 포함한 모든 리소스는 오픈소스로 공개될 예정이다.
One-sentence Summary
The authors present Diffusion Templates, a unified plugin framework that decouples base-model inference from controllable capability injection by standardizing heterogeneous carriers like LoRA and KV-Cache through a systems-level interface, unifying diverse generation tasks such as structural control, editing, and super-resolution while preserving modularity and composability across evolving diffusion backbones.
Key Contributions
- The paper introduces Diffusion Templates, a unified plugin framework that decouples base-model inference from controllable capability injection. The architecture coordinates three components: template models that map task-specific inputs to intermediate representations, a standardized template cache for capability injection, and a template pipeline that loads and merges multiple caches into the base diffusion runtime.
- By establishing a systems-level interface for capability injection, the framework enables heterogeneous control carriers such as KV-Cache and LoRA to operate under a single abstraction. This design removes architecture-specific adaptations and supports cross-backbone composability across rapidly evolving diffusion foundations.
- The framework consolidates over ten distinct generation tasks into a single model zoo, covering structural control, image editing, super-resolution, and aesthetic alignment. All associated code, models, and datasets are publicly released to enable modular deployment across diverse diffusion architectures.
Introduction
Diffusion models have established themselves as the foundation for high-quality visual generation, yet practical applications demand precise control over structure, style, and content. This requirement has spurred the development of numerous control techniques, including parameter-efficient adaptations like LoRA and conditional modules such as ControlNet, which are essential for advanced image synthesis and editing tasks. However, these methods are typically deployed as isolated, backbone-specific systems with incompatible training pipelines, parameter formats, and runtime hooks. This fragmentation creates a systems bottleneck that hinders infrastructure reuse, capability transfer across backbones, and the composition of multiple controls, often necessitating complex handcrafted engineering to resolve conflicts in conditioning pathways. The authors leverage a plugin-based abstraction to introduce Diffusion Templates, a unified framework that decouples base-model inference from capability injection via a standardized interface comprising Template models, a Template cache, and a Template pipeline. By treating heterogeneous capability carriers like KV-Cache and LoRA as pluggable modules, the framework allows task-specific inputs to be converted into intermediate representations that can be loaded, merged, and injected independently, enabling modular composition without modifying the underlying diffusion architecture.
Method
The Diffusion Templates framework presents a unified plugin architecture for controllable diffusion generation, decoupling base-model inference from control-capability injection. The framework operates through three core components: the Template cache, Template model, and Template pipeline. The Template cache serves as a standardized interface for representing model capabilities, constrained to a subset of input arguments accepted by the diffusion pipeline of base models. This design aligns with existing engineering abstractions of diffusion frameworks, enabling new capabilities to be integrated by extending pipeline arguments rather than rewriting denoising internals, while providing a stable contract between plugins and base pipelines. Among candidate interfaces, KV-Cache is the most practical and recommended type due to its strong representational capacity, direct influence on generation behavior, and natural support for sequence-level concatenation, which is critical when multiple templates are active. However, the framework does not restrict the cache format, allowing alternative representations such as lightweight parameterizations like LoRA to be supported.
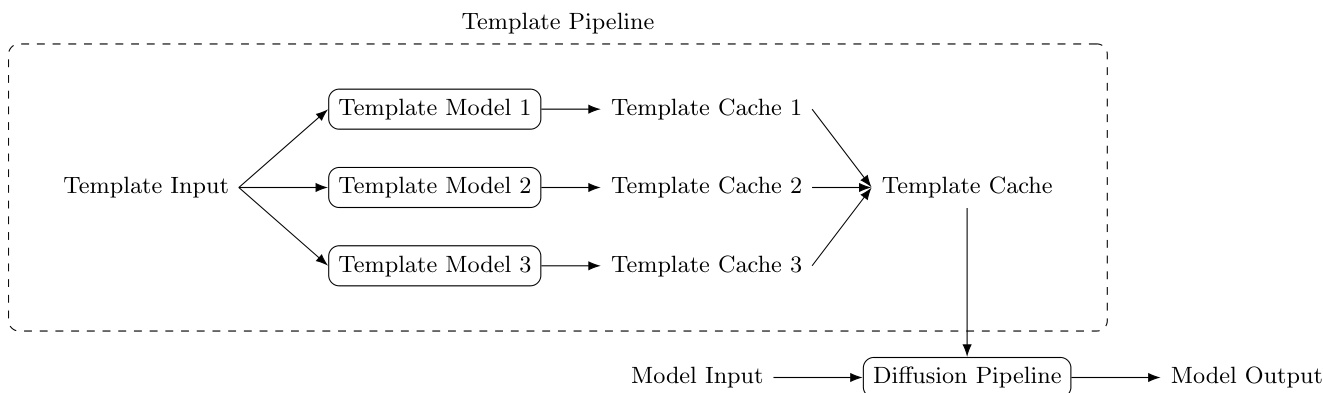
A Template model is any model that maps arbitrary input to the standardized Template cache format. Its architecture is unrestricted, and it can be packaged as a local directory or hosted in remote model hubs. Each Template model exposes two interfaces: processInputs for no-gradient preprocessing and feature preparation, and forward for gradient-related computation that produces Template cache outputs. This interface split maintains model flexibility while ensuring framework-level compatibility, allowing heterogeneous architectures to run under a unified runtime.

The Template pipeline orchestrates the loading, execution, and composition of multiple Template models. During inference, given one or more enabled Template models, the process proceeds in three steps: first, each Template model processes its input to produce a Template cache; second, caches are merged according to their type—direct concatenation is used for KV-Cache; third, the merged cache is passed into the base diffusion pipeline alongside normal generation arguments. Because KV-Cache supports concatenation, multiple Template models can operate jointly without altering the base denoising logic. Template models execute outside the iterative denoising process, so runtime overhead remains low, and inference remains efficient. In practice, template inference can be scheduled in a round-robin manner with lazy loading to reduce peak memory usage when many templates are configured.
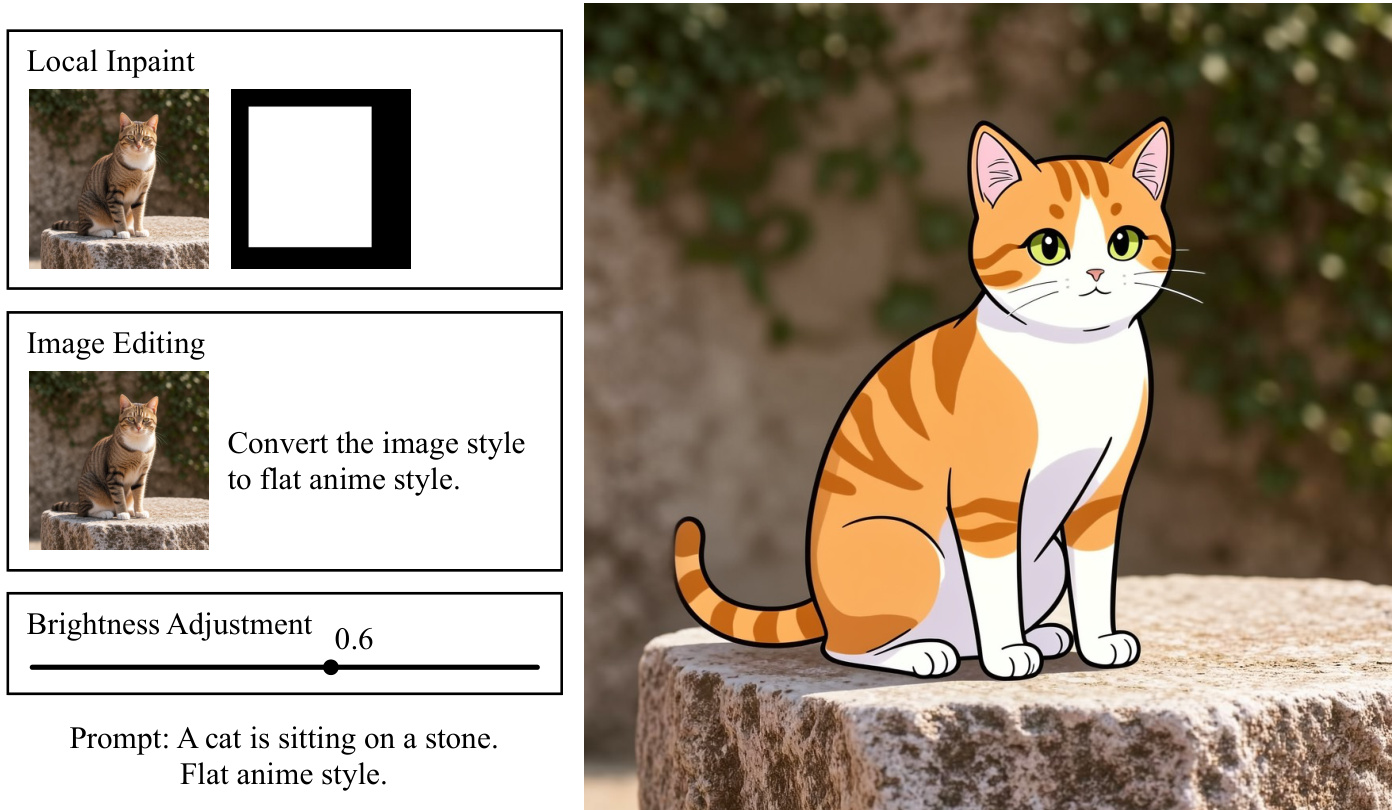
Template models are trained using a standard paradigm similar to ControlNet and LoRA, where trainable side branches are attached to the pretrained base model, with all base-model parameters frozen. Optimization targets the new branches using the original pretraining loss of the base model, preserving the learning objective while transferring task-specific capabilities into the Template pathway. Training is organized into two stages: Stage I executes input processing in a no-gradient pipeline to produce reusable intermediate features that can be aggressively cached; Stage II restricts optimization to the gradient-relevant forward path under training objectives defined on the Template cache. This separation reduces redundant computation and improves training efficiency. The training framework is built on DiffSynth-Studio, which supports the standardized processInputs and forward interfaces. Template models can be trained for diverse tasks, including structural control, brightness and color adjustment, image editing, super-resolution, and local inpainting, each with distinct architectural designs tailored to the control task. For instance, structural control models use an architecture similar to ControlNet but communicate control signals through KV-Cache instead of residual branches, while brightness and color adjustment models follow a lightweight design with positional encoding and fully connected layers. Image editing and super-resolution models use architectures similar to the structural-control model, transferring editing and upscaling capabilities into the Template pathway. Local inpainting models provide soft control and are combined with pipeline-level hard constraints to enforce content preservation outside masked regions. Multiple Template models can be fused effectively within a single generation pipeline, with fusion strategies depending on the cache format: KV-Cache models are fused by concatenating caches along the sequence dimension, while LoRA-based models are fused by concatenating parameters along the rank dimension. When different models emit caches in heterogeneous formats, their modules can be enabled simultaneously without conversion, enabling on-demand loading and supporting the fusion of an arbitrary number of capabilities without significant GPU memory growth.
Experiment
By training diverse Template models on a base diffusion architecture with standardized generation parameters, the experiments validate the framework's expressiveness and extensibility across multiple control domains. Sharpness control demonstrates reliable adjustment of perceptual detail through edge density proxies, while aesthetic alignment successfully translates discrete human preference data into continuous conditioning that enhances composition and generalizes beyond training ranges. Additionally, age control confirms the method's capacity for semantically rich, continuous manipulation of portrait features while preserving identity and quality. Collectively, these results establish Template models as a flexible mechanism for both low-level visual tuning and high-level subjective alignment.