Command Palette
Search for a command to run...
ReVSI: VLM 3D 추론에 대한 정확한 평가를 위한 시각적 공간 지능 평가 재구축
ReVSI: VLM 3D 추론에 대한 정확한 평가를 위한 시각적 공간 지능 평가 재구축
Yiming Zhang Jiacheng Chen Jiaqi Tan Yongsen Mao Wenhu Chen Angel X. Chang
초록
현재의 공간 지능(Spatial Intelligence) 평가는 최신 비전-라nguage 모델(VLM) 환경하에서 체계적으로 타당성을 상실할 수 있다. 첫째, 다수의 벤치마크는 전통적인 3D 인식(3D perception)을 위해 원래 기획된 점 클라우드 기반 3D 주석(Annotation)으로부터 질문-정답(QA) 쌍을 도출한다. 이러한 주석이 비디오 기반 평가를 위한 정답(Ground Truth)으로 간주될 때, 재구성 및 주석 생성 과정에서 발생하는 아티팩트(Artifact)로 인해 비디오에서 명확하게 보이는 객체를 누락하거나, 객체의 신원을 잘못 식별하거나, 치수(Size) 등 기하학적 요소에 의존하는 정답이 왜곡되어 부정확하거나 모호한 QA 쌍이 생성될 수 있다. 둘째, 평가들은 종종 전장면(Full-scene) 접근을 가정하는 반면, 많은 VLM들은 희소하게 샘플링된 프레임(예: 16~64개)에서만 작동하므로, 실제 모델 입력 환경에서는 많은 질문이 사실상 답변 불가능하게 된다.저자들은 각 QA 쌍이 모델의 실제 입력 환경에서 답변 가능하고 정확함을 보장하는 벤치마크 및 프로토콜인 'ReVSI'를 도입함으로써 평가의 타당성을 제고했다. 이를 위해 저자들은 5개 데이터셋의 381개 씬(장면) 전반에 걸쳐 객체 및 기하학적 구조에 대한 주석을 재작성하여 데이터의 품질을 향상시켰으며, 전문적인 3D 주석 도구를 활용하여 엄격한 편향 완화(Bias mitigation)와 인간의 검증을 통해 모든 QA 쌍을 재생성했다. 또한, 저자들은 다양한 프레임 예산(16/32/64/all)과 세분화된 객체 가시성 Metadata를 제공함으로써 평가의 통제 가능성(Controllability)을 높였으며, 이를 통해 통제된 진단 분석이 가능하도록 했다. ReVSI에서의 일반 및 도메인 특화 VLM에 대한 평가는 기존 벤치마크에 가려졌던 체계적인 실패 모드(Systematic failure modes)들을 드러내었으며, 이는 공간 지능에 대해보다 신뢰할 수 있고 진단적인 평가를 가능하게 한다.
One-sentence Summary
The authors introduce ReVSI, a benchmark and protocol ensuring valid visual spatial intelligence evaluation for vision-language models by re-annotating objects and geometry across 381 scenes from five datasets and generating human-verified question-answer pairs answerable under sparse frame inputs, revealing systematic failure modes and enabling reliable diagnostic assessment of 3D reasoning capabilities.
Key Contributions
- The paper introduces ReVSI, a benchmark and protocol ensuring question-answer pairs are valid under the actual sparse frame inputs of vision-language models. The dataset construction re-annotates objects and geometry across 381 scenes from 5 datasets to eliminate artifacts found in prior 3D perception annotations.
- Evaluation controllability is improved by offering benchmark variants across multiple frame budgets and fine-grained object visibility metadata for diagnostic analysis. These features enable evidence-absent controls that test whether models rely on visual information or non-visual priors.
- Empirical evaluations on ReVSI reveal systematic failure modes in general and domain-specific models that are obscured by existing benchmarks. Results indicate that scaling post-training data does not consistently improve performance and that some models fail to ground answers in visual evidence.
Introduction
Vision-language models require robust spatial reasoning capabilities to operate effectively in 3D environments such as robotics or medical imaging. Current evaluation standards like VSI-Bench often rely on repurposed 3D annotations that drift from actual video evidence and assume full scene observability despite sparse input frames. The authors address these validity gaps by introducing ReVSI, a rebuilt benchmark that ensures strict consistency between model inputs and ground truth annotations through professional re-annotation and frame-aware protocols. This rigorous framework exposes significant performance discrepancies in prior evaluations and enables diagnostic testing to distinguish genuine spatial reasoning from predictions based on non-visual priors.
Dataset
-
Dataset Composition and Sources
- The authors construct ReVSI using 381 scenes derived from five public datasets: ScanNetv2, ScanNet++, ARKitScenes, 3RScan, and MultiScan.
- The benchmark focuses on indoor 3D environments to test visual-spatial intelligence in vision-language models.
- Object labeling adopts an open-vocabulary setting with over 500 unique categories, expanding significantly beyond the closed set used in prior work.
-
Key Details for Each Subset
- Data is organized into frame-budget variants including 16, 32, 64, and all-frame settings to simulate different sampling rates.
- Specific tasks include object counting, size estimation, absolute and relative distance, relative direction, room size estimation, and route planning.
- The Object Appearance Order task is excluded to focus on spatial rather than temporal reasoning.
- Ambiguous object categories such as shoes are filtered out to prevent ill-posed queries.
-
Usage in the Paper
- The dataset serves as an evaluation benchmark rather than a training set to diagnose spatial reasoning failures in general and domain-specific models.
- Evaluation protocols enforce question answerability and ground-truth correctness under each specific frame sampling configuration.
- The authors use the data to conduct controlled diagnostic analyses by comparing performance across different visibility levels and frame budgets.
-
Processing and Metadata Construction
- All 3D bounding boxes are re-annotated using a gravity-aligned oriented bounding box algorithm followed by manual refinement.
- Room boundaries are manually annotated as polygons from orthogonal top-down views to ensure accurate area estimation.
- Object visibility is determined by checking if pixel coverage exceeds 5 percent in the most prominent frame, with manual verification for edge cases.
- The team generates dummy videos for stress testing, including Query-Dropped, First-Frame Repeated, and Black frame variants under the 16-frame setting.
- For object naming verification, annotators crop tight image regions containing the object and use GPT-5.2 as an auxiliary check before finalizing human labels.
- Question templates are refined to reduce bias, such as adding cumulative counting queries and removing short-range distance questions under 1 meter.
Experiment
The study evaluates multiple vision-language models using the ReVSI benchmark, which enforces frame-budget-aware protocols and visibility-consistent questions to address validity issues in existing benchmarks. Results indicate that ReVSI reveals significant discrepancies in model rankings by penalizing hallucinations that were previously masked in VSI-Bench, showing that proprietary models consistently outperform open-source counterparts on grounded spatial reasoning. Furthermore, diagnostic tests on dummy videos demonstrate that specialized fine-tuned models often fail catastrophically when visual evidence is absent, suggesting that supervision fidelity rather than training data quantity is the primary bottleneck for robust 3D intelligence.
The the the table evaluates the spatial reasoning capabilities of various proprietary and open-source vision-language models on the ReVSI benchmark across numerical and multiple-choice tasks. Results show that proprietary models generally achieve higher overall performance scores compared to the open-source models listed. Furthermore, within open-source families, larger model sizes tend to yield better results than their smaller counterparts. Proprietary models consistently outperform open-source models across most spatial reasoning categories. Larger model variants within the same family, such as the 32B and 38B versions, demonstrate improved accuracy over smaller 8B versions. Room size estimation appears to be a more challenging task for most models compared to object size estimation.
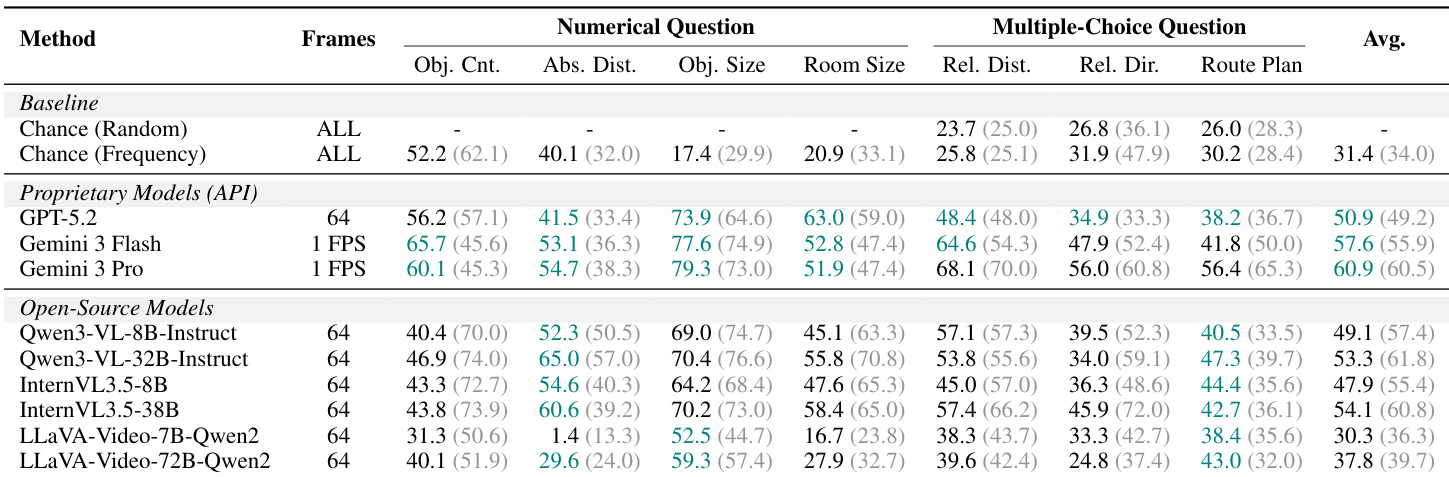
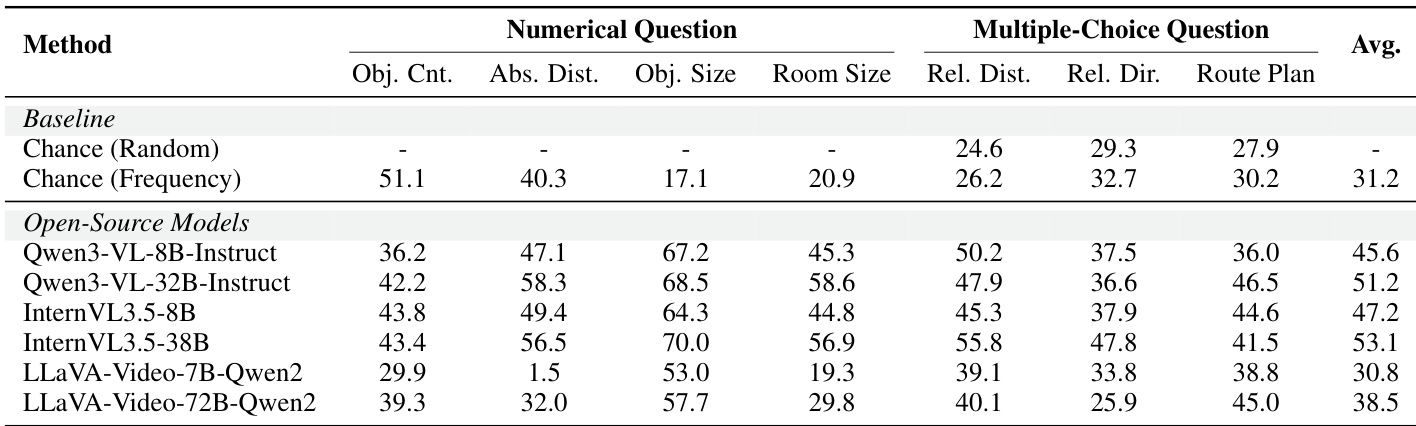
The the the table presents evaluations of open-source video-language models on numerical and multiple-choice spatial reasoning tasks. Results indicate that larger model variants generally achieve higher average scores compared to smaller versions and chance baselines. Performance is consistently highest on object size estimation tasks relative to counting and distance estimation. Increasing model size within the Qwen and InternVL families consistently leads to higher average scores. Object size estimation yields substantially higher performance compared to object counting and absolute distance estimation. The smallest model variant performs below the frequency-based chance baseline, while larger models exceed it.
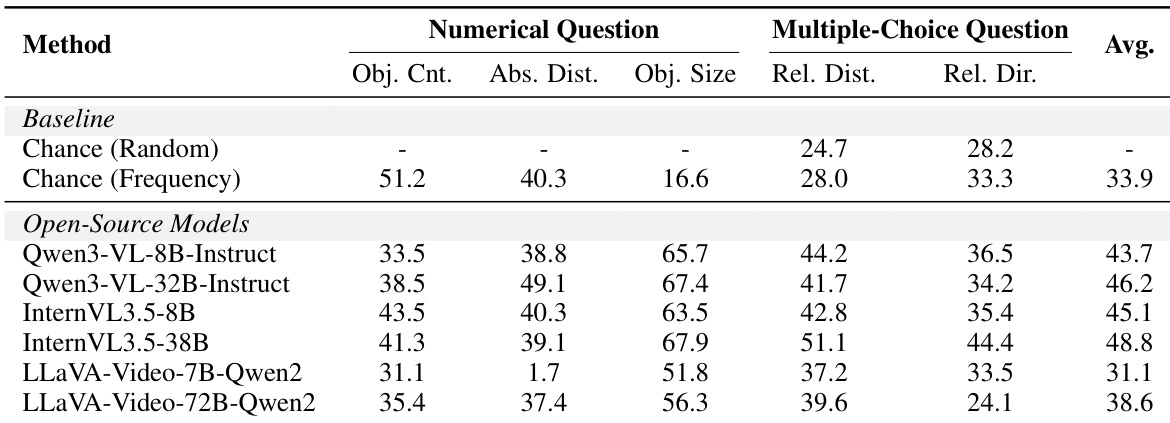
The evaluation results on the ReVSI benchmark reveal that proprietary models consistently outperform open-source counterparts across various spatial reasoning tasks. Unlike previous benchmarks, specialized fine-tuned models do not exhibit substantial performance gains and often underperform compared to their base versions. Additionally, the data highlights performance asymmetries where models handle single object counting and closest distance estimation more effectively than multiple object scenarios or farthest distance queries. Proprietary models consistently achieve higher scores than open-source models across object counting and spatial estimation tasks. Fine-tuned specialized models show limited improvement over base models and occasionally suffer performance degradation. Performance varies significantly by task complexity, with models handling single object queries better than multiple object queries.
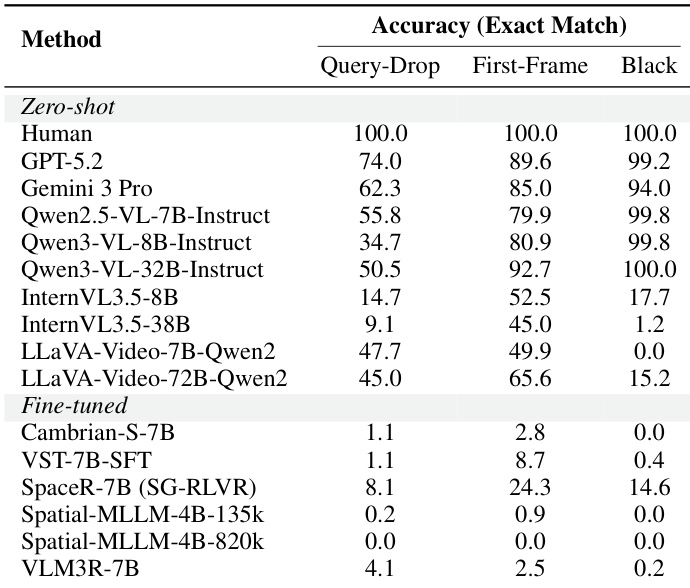
The authors evaluate model robustness against hallucination using dummy video inputs where the queried objects are absent. Results indicate that while human evaluators and proprietary models reliably identify the absence of objects, specialized fine-tuned models frequently fail by predicting non-zero counts. This suggests that fine-tuning on existing benchmarks may lead to overfitting and a disregard for actual visual evidence. Specialized fine-tuned models exhibit near-zero performance on black video inputs, revealing a tendency to hallucinate objects that are not present. Proprietary models consistently outperform open-source counterparts on tasks requiring the detection of missing objects. Performance varies significantly among zero-shot open-source models, with some achieving perfect accuracy on dummy inputs while others fail completely.
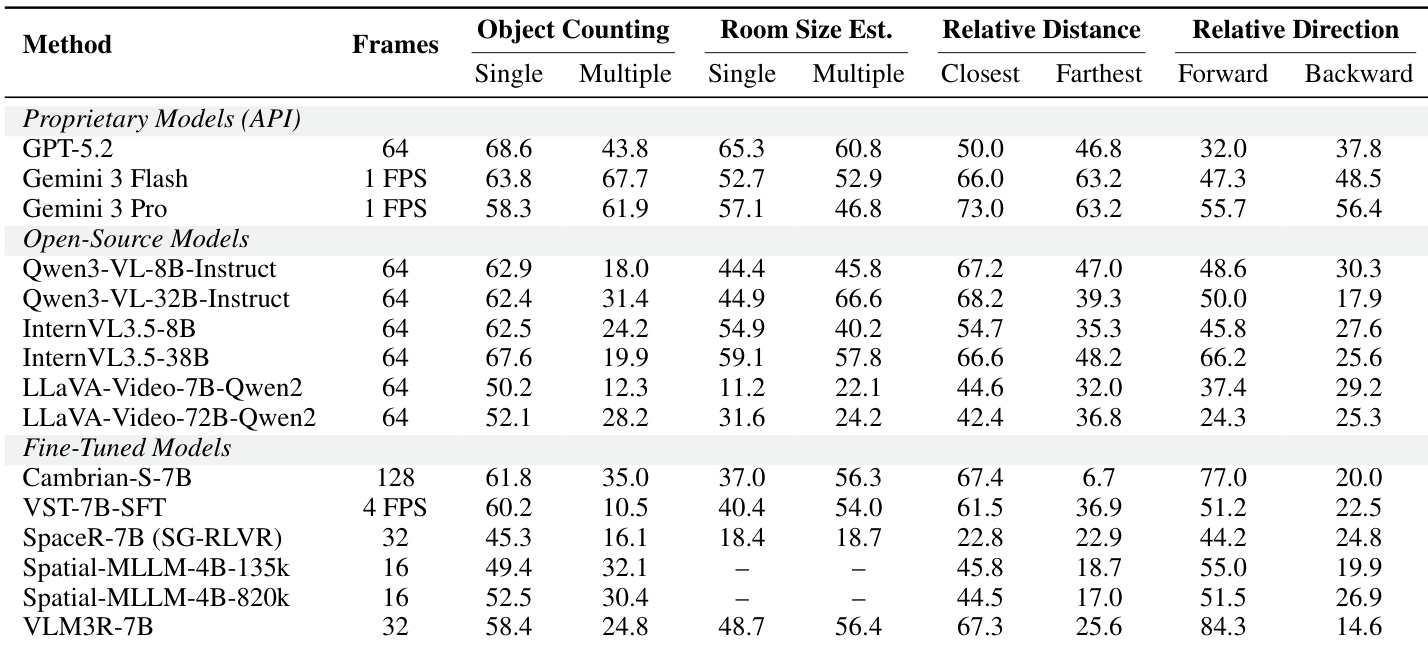
The authors evaluate representative open-source vision-language models on numerical and multiple-choice spatial reasoning tasks using the ReVSI benchmark. The results show a clear trend where larger model variants, such as the 32B versions of Qwen and InternVL, outperform their smaller 8B counterparts across most metrics. While object size estimation is handled relatively well by the top models, absolute distance estimation presents a larger performance gap between different architectures. Larger model scales generally yield superior performance on both numerical and multiple-choice spatial reasoning benchmarks. Object size estimation tasks are solved with higher accuracy compared to absolute distance estimation tasks across the evaluated models. The Qwen3-VL and InternVL3.5 families demonstrate stronger overall spatial reasoning capabilities than the LLaVA-Video variants in this comparison.
This evaluation assesses spatial reasoning and hallucination robustness across proprietary, open-source, and fine-tuned vision-language models on the ReVSI benchmark. Proprietary models consistently outperform open-source alternatives, and larger parameter variants generally achieve higher accuracy than smaller versions across image and video tasks. Conversely, specialized fine-tuned models often underperform base versions and hallucinate absent objects, while tasks involving distance estimation and multiple objects remain more difficult than object size estimation.