Command Palette
Search for a command to run...
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
Agentic World Modeling: Foundations, Capabilities, Laws, and Beyond
초록
AI 시스템이 단순히 텍스트를 생성하는 단계에서 지속적인 상호작용을 통해 목표를 달성하는 단계로 진화함에 따라, 환경의 역학(environment dynamics)을 모델링하는 능력이 핵심적인 병목 현상으로 떠오르고 있습니다. 객체를 조작하거나, 소프트웨어를 탐색하거나, 타인과 협력하거나, 혹은 실험을 설계하는 agents는 예측 가능한 환경 모델을 필요로 하지만, '월드 모델(world model)'이라는 용어는 연구 커뮤니티마다 서로 다른 의미로 사용되고 있습니다.본 논문에서는 두 개의 축을 기준으로 구성된 'Levels x Laws' 분류 체계(taxonomy)를 제안합니다. 첫 번째 축은 세 가지 역량 수준(capability levels)을 정의합니다. L1 Predictor는 단일 단계의 국소적 전이 연산자(one-step local transition operators)를 학습하며, L2 Simulator는 이를 도메인 법칙(domain laws)을 준수하는 다단계 액션 조건부 롤아웃(action-conditioned rollouts)으로 구성합니다. 마지막으로 L3 Evolver는 새로운 증거와 예측이 일치하지 않을 때 자신의 모델을 자율적으로 수정합니다. 두 번째 축은 네 가지 지배 법칙 체제(governing-law regimes)를 식별합니다: 물리적(physical), 디지털(digital), 사회적(social), 그리고 과학적(scientific) 체제입니다. 이러한 체제는 월드 모델이 반드시 충족해야 하는 제약 조건과 실패 가능성이 가장 높은 지점을 결정합니다.본 프레임워크를 활용하여, 우리는 모델 기반 강화 학습(model-based reinforcement learning), 비디오 생성, 웹 및 GUI agents, multi-agent 사회적 시뮬레이션, 그리고 AI 기반 과학적 발견에 이르는 400개 이상의 연구를 종합하고 100개 이상의 대표적인 시스템을 정리하였습니다. 또한, '레벨-체제(level-regime)' 쌍에 따른 방법론, 실패 모드(failure modes), 평가 관행을 분석하고, 의사결정 중심의 평가 원칙과 최소 재현 가능 평가 패키지(minimal reproducible evaluation package)를 제안하며, 아키텍처 가이드라인, 미해결 과제 및 거버넌스 과제를 제시합니다. 본 연구가 제시하는 로드맵은 이전에 분절되어 있던 연구 커뮤니티를 연결하며, 수동적인 차기 단계 예측을 넘어 agents가 작동하는 환경을 시뮬레이션하고 궁극적으로 재구성할 수 있는 월드 모델로 나아가는 경로를 제시합니다.
One-sentence Summary
By introducing a "levels × laws" taxonomy that categorizes capabilities into three levels and four governing-law regimes, this work synthesizes over 400 works and 100 representative systems to provide a comprehensive roadmap for developing agentic world models capable of simulating and reshaping their environments.
Key Contributions
- The paper introduces a "levels × laws" taxonomy that categorizes world models through three capability levels (Predictor, Simulator, and Evolver) and four governing-law regimes (physical, digital, social, and scientific).
- This work synthesizes over 400 research works and summarizes more than 100 representative systems across diverse domains such as model-based reinforcement learning, video generation, and AI-driven scientific discovery.
- The research proposes decision-centric evaluation principles and a minimal reproducible evaluation package to address the challenges of analyzing failure modes and evaluation practices across different level-regime pairs.
Introduction
As AI agents transition from simple text generation to complex goal achievement, the ability to model environment dynamics has become a critical bottleneck. While the term "world model" is widely used, research remains fragmented across disparate communities such as reinforcement learning, computer vision, and robotics, leading to inconsistent definitions and incomparable evaluation metrics. Existing surveys often fail to capture the progression of capabilities across different modalities, leaving a gap in how the paper understand the transition from mere prediction to true simulation.
The authors leverage a novel "levels × laws" taxonomy to unify these isolated fields. They propose a three-level capability hierarchy consisting of L1 Predictors (one-step local transitions), L2 Simulators (multi-step, action-conditioned rollouts), and L3 Evolvers (autonomous, evidence-driven model revision). This hierarchy is mapped against four governing-law regimes: physical, digital, social, and scientific worlds. By synthesizing over 400 works, the authors provide a decision-centric roadmap that connects diverse research domains and establishes a common language for building agents that can simulate and eventually reshape their environments.
Dataset
The authors utilize a diverse landscape of benchmarks to evaluate agent mastery across different governing-law regimes. The dataset composition is categorized into the following domains:
- Physical-World Domains: Includes Atari 100k for sample-efficient world-model learning, Meta-World for robotic manipulation, and CALVIN for language-conditioned long-horizon tasks. The authors also incorporate RoboCasa and RoboCasa365 for physical stability, BuilderBench for structural stability, and ManiSkill3 and RLbench for generalizable manipulation. Autonomous driving is represented by nuScenes, while 3D navigation and household activities are covered by the Habitat series, iGibson 2.0, and BEHAVIOR-1K. VBench is used to evaluate physical compliance in video generation.
- Digital-World Domains: Focuses on GUI grounding and software interaction through OSWorld, macOSWorld, SWE-bench, WebArena, and Mind2Web. Mobile operating system constraints are addressed using AppAgent and AndroidWorld. GameWorld is included for verifiable multimodal agent evaluation.
- Social-World Domains: Employs Theory of Mind benchmarks such as ToMi, BigToM, and OpenToM to assess psychological state inference. Social simulation and role-playing are covered by Sotopia and AgentBench, while strategic reasoning and deception are tested via game-based environments like Werewolf and Avalon.
- Scientific-World Domains: Uses ScienceWorld for elementary reasoning, DiscoveryBench for hypothesis verification, ChemCrow for chemical synthesis, and FutureX for evidence-based prediction.
- Open-World Environments: Combines multiple governing laws through procedurally generated worlds such as Minecraft, Crafter, and NetHack to test skill composition and long-horizon planning.
The authors use these benchmarks as anchor points to test specific boundary conditions. Evaluation protocols involve regime-specific constraint verification, degradation curves for long-horizon coherence, and counterfactual divergence testing to measure intervention sensitivity.
Method
The framework for agentic world modeling is structured around a three-level capability hierarchy—L1 Predictor, L2 Simulator, and L3 Evolver—organized along two orthogonal axes: capability level and governing-law regime. This hierarchy describes the progression of world-modeling capabilities from local prediction to evidence-driven revision, with each level serving distinct functions in an agent's decision-making process. The governing-law regimes—Physical, Digital, Social, and Scientific—define the constraints and invariants that transitions in a domain must satisfy, shaping the design and evaluation of world models within each context. The framework emphasizes that these levels are not static classifications but represent the capability an agent invokes at runtime based on task demands. A single deployed system can operate at different levels simultaneously, with L1 providing fast, reactive one-step predictions, L2 enabling multi-step simulations for planning and counterfactual reasoning, and L3 facilitating model revision when systematic failures occur. This runtime dispatch view clarifies that L3 is not a replacement for L1 or L2 but a governance layer that improves the stack when evidence demands it, operating as an adaptive system that treats its own model assets as objects of revision.
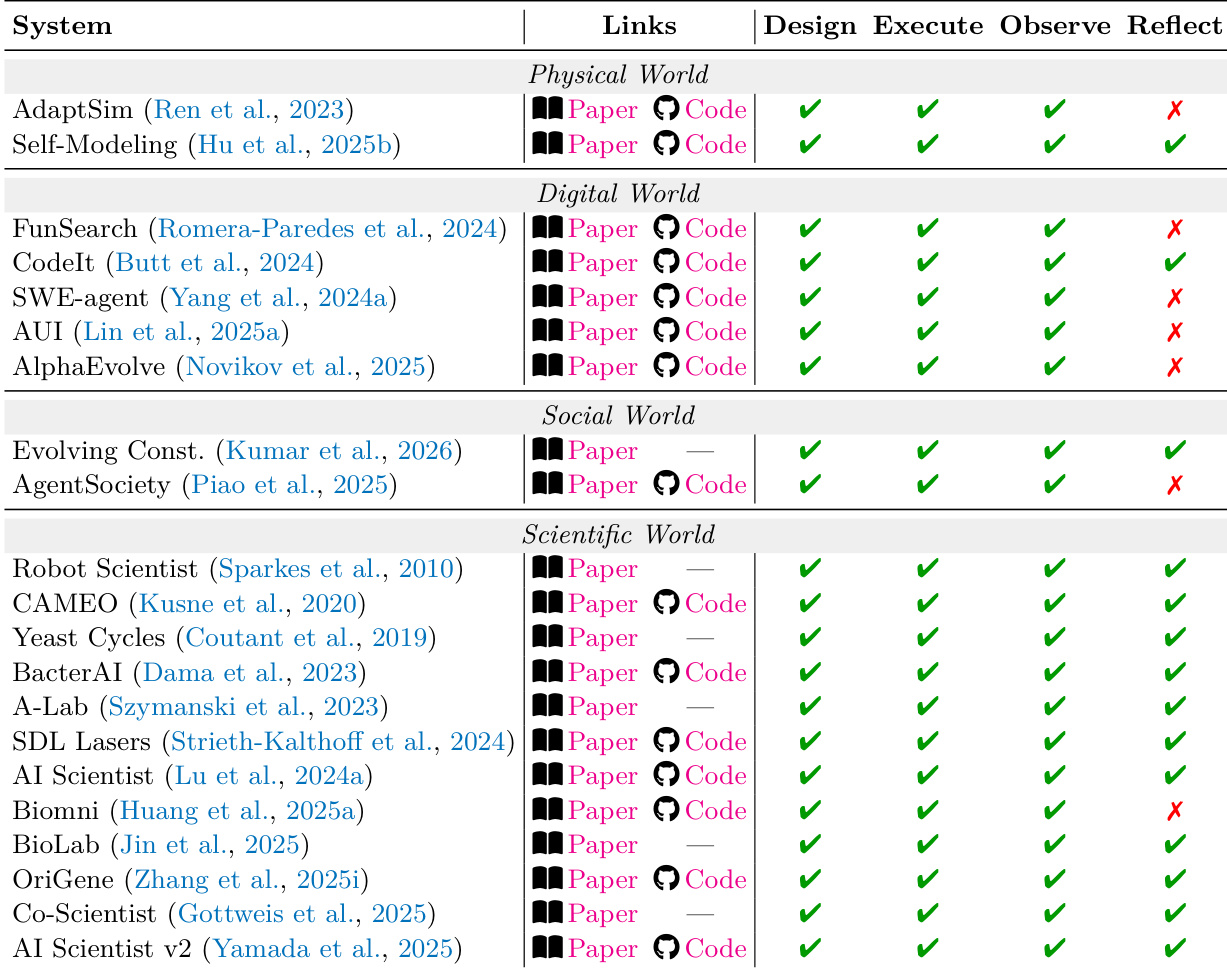
At the foundational level, the L1 Predictor focuses on local predictive operators that factorize into four components: state inference, forward dynamics, observation decoding, and inverse dynamics. These operators target one-step accuracy under the training distribution, with no guarantee of multi-step coherence. The core operator is forward dynamics, which models the transition from one latent state to the next given an action, while the others support inference and decoding. The L1 level is characterized by a Markovian property in the learned latent state, where the internal state zt is adequate for predicting the subsequent local step. This level is grounded in the POMDP formulation, where the agent maintains a belief over hidden states and crafts a policy to maximize cumulative reward. The L1 model is defined by its ability to sustain a meaningful internal state and use local predictive mechanisms to anticipate the next state, including potential observations or actions.
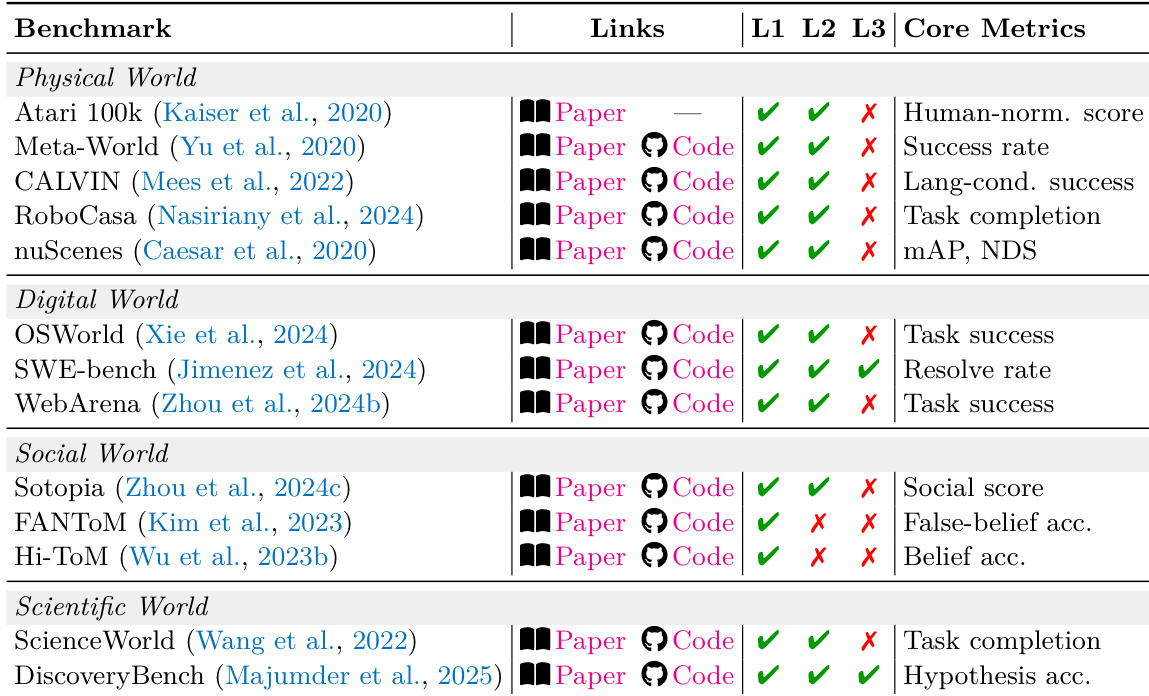
The L2 Simulator elevates the one-step predictive capability to decision-usable multi-step simulation. It answers the question: "if the agent executes a candidate action sequence under task constraints, what future trajectory is likely to unfold?" This level stitches per-edge L1 operators into a full trajectory, enabling the agent to roll out candidate plans and compare outcomes before committing to action. The L2 system supports trajectory-level queries of the form p^(τ∣z0,a1:H,c), where a1:H denotes an action sequence and c denotes optional constraints. Intervention-structured rollouts align with the interventional rung of Pearl's causal hierarchy, distinguishing L2 from L1 by coherent multi-step rollout under governing laws rather than one-step predictive quality alone. The L2 level is crucial for model-based planning, where synthetic training data generation relies on realistic state transitions to support policy improvement.

The L3 Evolver extends L2 from simulation within a fixed scaffold to evidence-driven model revision. It maintains an explicit update loop over model assets, where the system diagnoses failures, distills fixes into reusable assets, and validates updates before enabling them. The three boundary conditions marking the transition from L2 to L3 are: evidence-grounded diagnosis, persistent asset update, and governed validation. The key difference from L2 is that the model itself becomes an object of revision, not merely a fixed scaffold to be queried. The L3 system operates in a closed-loop design–execute–observe–reflect cycle, where new evidence is actively acquired to challenge and revise the model across iterations. This formulation closely mirrors the structure of scientific practice, where anomalies lead to model updates, ranging from incremental refinements to paradigm shifts. The L3 level is characterized by active trial-and-error, with the agent acting as a designer of experiments to generate data that maximizes information gain.

The architectural design of world models involves three primary building blocks: representation, dynamics, and control interface. Representation choices range from symbolic or programmatic states to latent continuous representations, each with distinct tradeoffs in interpretability, flexibility, and susceptibility to drift. Dynamics models include stochastic latent dynamics, deterministic value-aware dynamics, autoregressive token dynamics, and diffusion-based dynamics, each offering different balances of uncertainty modeling, multimodality, and action controllability. Control interfaces range from online MPC-style approaches to tree search and expansion, imagined-rollout policy optimization, and replayable-environment interfaces, each with different computational demands and error amplification characteristics. The governing-law regime determines which combinations are viable, with physical-world systems favoring latent or structured 3D representations paired with MPC or imagined-rollout policies, digital-world systems relying on symbolic or DOM-based states with replayable environments, social-world systems focusing on coherent agent identity and relational state maintenance, and scientific-world systems prioritizing evidence-chain validity and falsifiability. The implementation roadmap distills these design tradeoffs into a concise guide organized by capability level and governing-law regime, highlighting the representation format, dynamics model class, and primary engineering bottleneck for each cell.
Experiment
The evaluation categorizes L2 systems into four governing-law regimes to analyze how different constraints, such as physical laws or social norms, shape simulator requirements. The analysis reveals that long-term stability is driven more by the explicit modeling of these underlying constraints than by increasing perceptual fidelity. Furthermore, the findings suggest that real-world applications often span multiple regimes, necessitating a holistic approach to joint constraint satisfaction to prevent cascading failures across domains.
The the the table categorizes various L2 systems across different domains, highlighting their adherence to boundary conditions such as formalizability and observability in social and scientific worlds. It shows that systems often combine multiple constraint families, requiring joint satisfaction of constraints across regimes to ensure coherent performance. Systems across domains vary in their adherence to formalizability and observability constraints, with some excelling in one area but not the other. Many L2 systems integrate multiple constraint families, such as physical and social, requiring cross-regime coherence. The architecture of L2 systems often involves a combination of LLMs with reinforcement learning or simulation frameworks to handle complex constraint interactions.
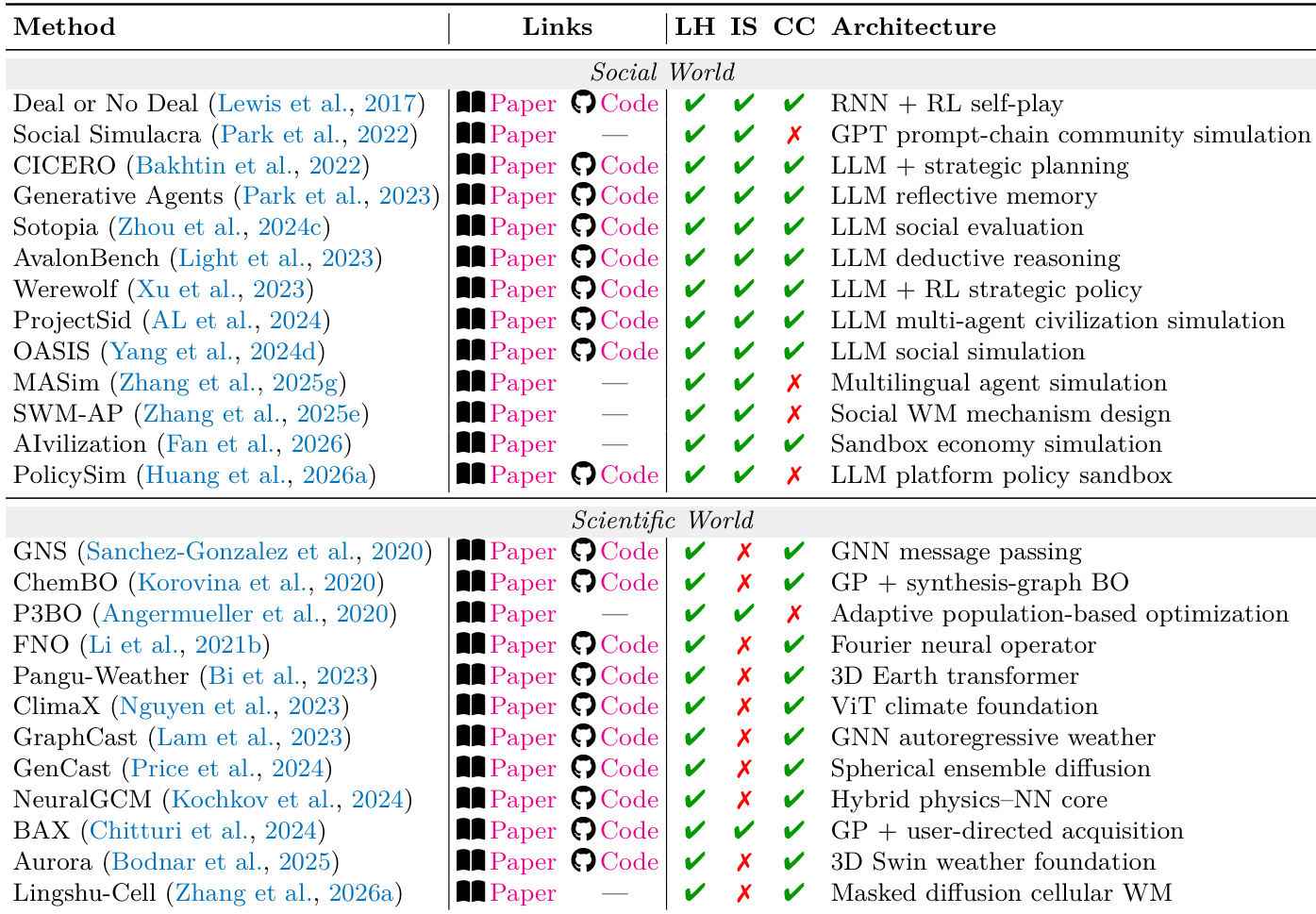
The the the table categorizes various L2 systems across four domains—Physical, Digital, Social, and Scientific—based on their capabilities in design, execution, observation, and reflection. Systems in each domain exhibit different patterns of constraint satisfaction, with notable differences in how they handle failure modes and evaluation priorities, particularly in cross-domain scenarios where multiple regimes interact. Systems across different domains show varying capabilities in design, execute, observe, and reflect, with some lacking in specific areas like reflection or observation. Cross-domain systems often require joint constraint satisfaction, as violations in one domain can cascade into others, affecting overall system coherence. The the the table highlights that making constraints explicit improves long-horizon stability more than increasing perceptual fidelity, regardless of the domain.
The authors categorize L2 systems across four governing-law regimes—physical, digital, social, and scientific—and evaluate their performance based on core metrics and boundary conditions. The the the table shows that systems in each regime vary in their use of paper and code links, with some achieving success in L1 and L2 but failing in L3, indicating limitations in generalization or long-horizon stability. Systems in the physical and digital worlds show consistent L1 and L2 performance but often fail in L3, suggesting challenges in scaling to more complex tasks. The social world systems achieve high L1 and L2 performance but fail in L3, indicating difficulties in handling long-term social dynamics. In the scientific world, systems achieve success across all three levels, highlighting the importance of structured evaluation and hypothesis validation.
The authors present a comparative analysis of L2 simulators across physical and digital worlds, categorizing methods by their adherence to governing laws related to formalizability and observability. The the the table highlights that successful simulators often prioritize explicit constraint modeling over perceptual fidelity, with notable differences in architecture and evaluation focus between regimes. Simulators in both physical and digital worlds prioritize formalizability and observability of constraints over perceptual fidelity. Methods in the physical world often use geometric or physical dynamics, while digital world methods rely on code-based or state transition models. Cross-regime systems face challenges due to cascading failures when constraints from one domain violate those in another.
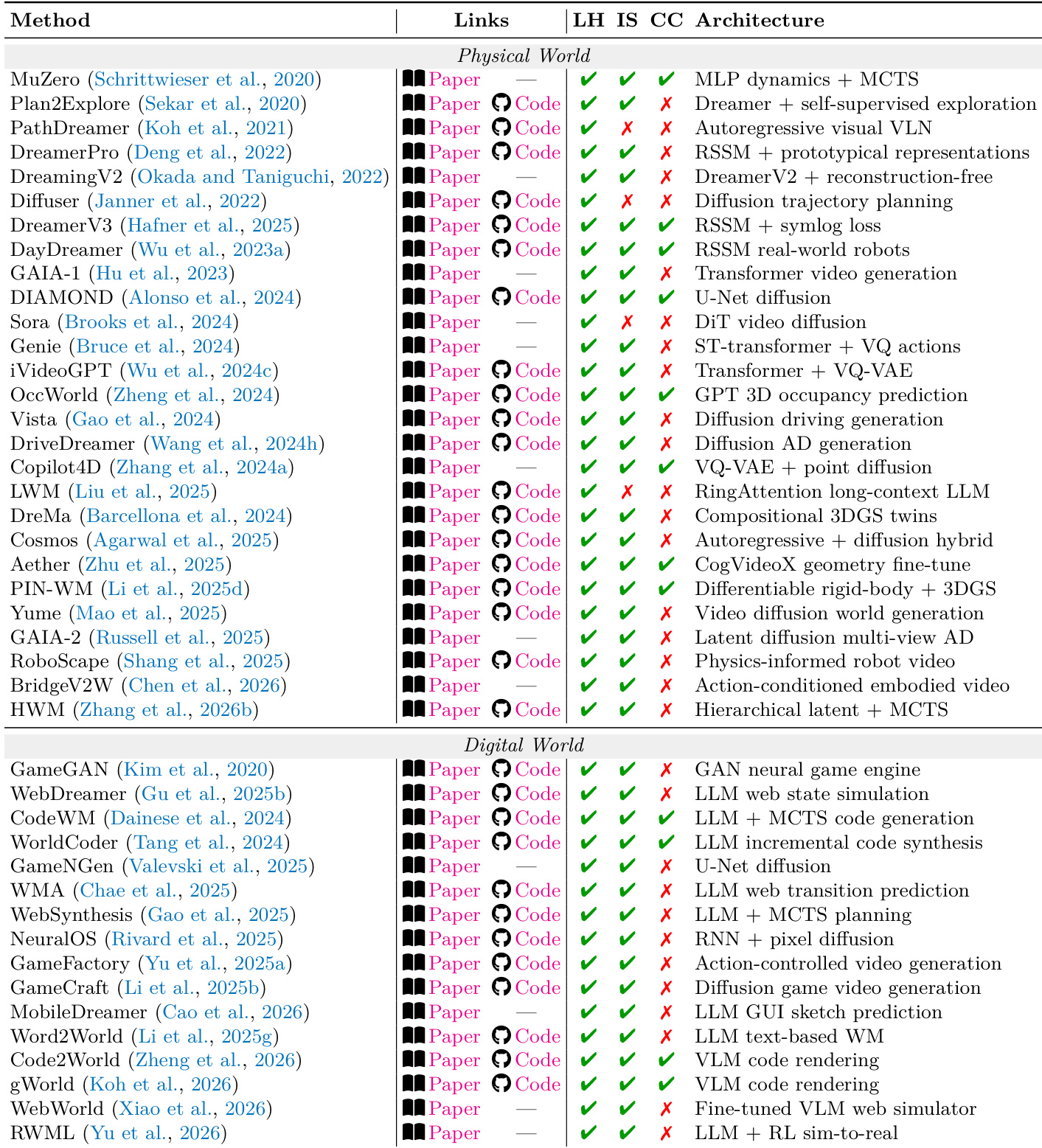
The evaluation categorizes L2 systems across physical, digital, social, and scientific domains to assess their ability to satisfy governing laws through design, execution, observation, and reflection. The findings indicate that while systems vary in their capacity to handle specific boundary conditions, successful performance often depends on explicit constraint modeling rather than mere perceptual fidelity. Furthermore, the analysis reveals that maintaining cross-regime coherence is essential, as many systems struggle with long-horizon stability and cascading failures when navigating complex, multi-domain interactions.