Command Palette
Search for a command to run...
StyleID: Stylization-Agnostic Facial Identity Recognition을 위한 인지 기반 데이터셋 및 메트릭
StyleID: Stylization-Agnostic Facial Identity Recognition을 위한 인지 기반 데이터셋 및 메트릭
Kwan Yun Changmin Lee Ayeong Jeong Youngseo Kim Seungmi Lee Junyong Noh
초록
창의적인 얼굴 스타일화(Creative face stylization)는 인물의 식별 가능한 정체성(identity)을 유지하면서, 만화, 스케치, 회화 등 다양한 시각적 양식으로 초상화를 구현하는 것을 목표로 합니다. 그러나 일반적으로 자연스러운 사진을 바탕으로 학습 및 보정되는 기존의 identity encoder들은 스타일화 과정에서 심각한 취약성(brittleness)을 보입니다. 이러한 encoder들은 질감이나 색상 팔레트의 변화를 정체성의 변화(identity drift)로 오인하거나, 기하학적 과장(geometric exaggerations)을 감지하지 못하는 경우가 많습니다. 이는 다양한 스타일과 강도에 걸쳐 정체성 일관성을 평가하고 감독할 수 있는 스타일 불가지론적(style-agnostic) 프레임워크가 부족함을 시사합니다.이러한 공백을 메우기 위해, 본 논문에서는 스타일화된 얼굴 정체성에 대한 인간의 지각을 고려한 데이터셋이자 평가 프레임워크인 StyleID를 제안합니다. StyleID는 다음 두 가지 데이터셋으로 구성됩니다: (i) StyleBench-H: 확산 모델(diffusion) 및 플로우 매칭(flow-matching) 기반의 스타일화에서 다양한 스타일 강도에 따른 인간의 동일성/차이성 검증 판단을 포착한 벤치마크, (ii) StyleBench-S: 통제된 이분 선택 강제(2AFC, two-alternative forced-choice) 실험을 통해 얻은 정신물리학적 인식 강도 곡선(psychometric recognition-strength curves)에서 도출된 감독 세트(supervision set).StyleBench-S를 활용하여, 본 연구에서는 기존의 semantic encoder를 미세 조정(fine-tune)함으로써 다양한 스타일과 강도에 걸쳐 이들의 유사도 순위(similarity orderings)가 인간의 지각과 일치하도록 정렬하였습니다. 실험 결과, 본 연구에서 보정한 모델은 인간의 판단과 유의미하게 높은 상관관계를 보였으며, 도메인 외(out-of-domain) 데이터인 화가가 그린 초상화에 대해서도 향상된 강건성(robustness)을 입증하였습니다.본 연구의 모든 데이터셋, 코드 및 사전 학습된 모델은 다음 페이지에서 공개적으로 이용 가능합니다: https://kwanyun.github.io/StyleID_page/
One-sentence Summary
To address the brittleness of identity encoders under creative face stylization, the authors introduce StyleID, a perception-aware dataset and evaluation framework comprising StyleBench-H for human same-different verification judgments and StyleBench-S for psychometric supervision from two-alternative forced-choice experiments, utilizing the latter to fine-tune semantic encoders that align similarity orderings with human perception and enhance robustness for out-of-domain artist-drawn portraits.
Key Contributions
- The paper introduces StyleID, a human perception-aware dataset and evaluation framework for assessing facial identity consistency across varying stylization strengths. This framework comprises StyleBench-H for capturing human verification judgments and StyleBench-S for deriving supervision from psychometric recognition-strength curves.
- Existing semantic encoders are fine-tuned using the StyleBench-S supervision set to align similarity orderings with human perception across different styles and transformation intensities. The supervision set is derived from psychometric recognition-strength curves obtained through controlled two-alternative forced-choice experiments.
- Experiments demonstrate that the calibrated models yield significantly higher correlation with human judgments and enhanced robustness for out-of-domain artist-drawn portraits. All datasets, code, and pretrained models associated with this work are publicly available.
Introduction
Creative face stylization is integral to modern avatar platforms and multimodal models, yet maintaining recognizable identity across visual idioms remains a significant challenge. Existing identity encoders trained on natural photographs often fail under stylization, mistaking texture shifts or geometric exaggerations for identity drift. The authors address this limitation with StyleID, a perception-aware framework that aligns identity metrics with human judgment across diverse styles and strengths. They construct StyleBench-H to capture human verification data and StyleBench-S to generate psychometric supervision curves. By fine-tuning semantic encoders on this data, the resulting model achieves higher correlation with human perception and improved robustness for stylized portrait recognition compared to prior methods.
Dataset
The authors introduce StyleBench to address the limitations of standard face recognition datasets under stylization. The dataset comprises two subsets tailored for evaluation and model training.
-
StyleBench-H (Human Perception Benchmark)
- Source: High-quality portraits from FFHQ, filtered to exclude large head rotations and images containing multiple people.
- Composition: Source images are stylized using three methods across ten artistic styles and seven discrete strength levels.
- Annotation: 68 valid participants completed pairwise verification tasks to determine if source and stylized images depict the same person.
- Filtering: Data was cleaned based on response latency and consistency, yielding 3,551 balanced datapoints.
- Splits: Includes standard, Cross-Style, and Cross-Method splits to test robustness against unseen identities and frameworks.
-
StyleBench-S (Large-Scale Synthetic Supervision)
- Calibration: Psychometric curves map stylization strength to human recognition probability using data from 72 participants.
- Selection Strategy: Pairs are retained only if the estimated human recognition probability exceeds 90 percent to ensure identity preservation.
- Configuration: The set includes 4,073 identities with 55 stylized images per identity across various method and style combinations.
- Size: The final dataset contains approximately 224,000 stylized samples for training.
-
Data Usage and Processing
- StyleBench-H evaluates generalization and alignment with human judgment across varying style strengths.
- StyleBench-S provides perception-aware supervision for training the deep identity encoder.
- Processing involves constructing psychometric functions to calibrate synthetic data thresholds against human perceptual limits.
Method
The authors establish a unified framework for perception-aligned identity evaluation and modeling under creative face stylization. This process begins with a controllable stylization pipeline that employs state-of-the-art diffusion and flow-based frameworks, such as IP-Adapter, InstantID, and InfiniteYou. These tools allow for the generation of stylized portraits with explicit control over the degree of deviation from the source identity. Refer to the framework diagram for the overall data construction and evaluation pipeline. The authors utilize human evaluation tasks, specifically Two Alternative Force Choice and Same-Different Verification, to construct the StyleBench-H benchmark. These annotations are used to identify an optimal stylization strength where recognition accuracy remains robust despite artistic variations. This insight drives the creation of StyleBench-S, a large-scale synthetic dataset derived from recognition-strength trends, which provides structured training signals for learning identity representations that remain stable under stylization.
To leverage this data, the authors introduce StyleID, a perception-calibrated identity encoder built upon the CLIP image encoder. As shown in the figure below: the architecture utilizes a dual-branch setup where the main StyleID encoder is adapted via LoRA adapters injected into the attention and linear layers of the frozen CLIP backbone. This design allows the model to learn style-robust representations without catastrophic drift from the pretrained manifold. The training objective combines three distinct loss terms to ensure discriminative power and stability. First, an angular margin head enforces discriminative angular margins between identities using the ArcFace loss formulation. Given an embedding zi and class weights wc, the cosine logit is computed as: cosθi,c=z^i⊤w^c.θi,c=arccos(cosθi,c)∈[0,π]. With an additive angular margin m and scale α, the loss for sample i is: ℓiang=−logexp(α⋅cos(θi,yi+m))+∑c=yiexp(α⋅cosθi,c)exp(α⋅cos(θi,yi+m)). Second, a supervised contrastive loss (Lscon) is applied to the normalized embeddings to explicitly pull together samples of the same identity while pushing apart different identities at the instance level. For an anchor i, the set of positives P(i) includes samples sharing the same identity: P(i)={p∈{1,…,B}\{i}∣yp=yi}. The loss is then computed using a temperature τ: ℓiscon=−∣P(i)∣1∑p∈P(i)log∑a∈{1,...,B}\{i}exp(z^i⊤z^a/τ)exp(z^i⊤z^p/τ). Finally, an embedding regularization loss (Lreg) constrains the adapted representation to remain close to the original frozen CLIP embedding to ensure stability: Lreg=B1∑i=1Bz^i−z^i(0)22. The total training loss is the weighted sum of these components: L=Lang+λsconLscon+λregLreg.
Experiment
Extensive evaluations on StyleBench-H and SKSF-A demonstrate that StyleID significantly outperforms conventional identity and semantic encoders in preserving human identity under diverse stylization and pose variations. Ablation and backbone selection experiments validate that a CLIP-based architecture with combined angular and contrastive losses provides superior robustness compared to models optimized solely for natural photographs. Furthermore, integrating StyleID into generative frameworks reduces visual artifacts and aligns better with human perceptual judgments than standard face recognition baselines.
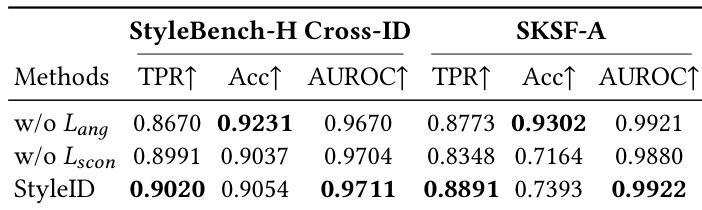
The authors evaluate the impact of replacing the ArcFace encoder with their proposed StyleID within the JoJoGAN stylization framework. The results show that the new configuration significantly outperforms the baseline across style fidelity, identity preservation, expression retention, and overall quality. The proposed method demonstrates superior performance in preserving identity and facial expressions compared to the baseline. Scores for style fidelity and overall image quality are notably higher with the new encoder. Quantitative metrics consistently favor the JoJoGAN configuration using StyleID over ArcFace.
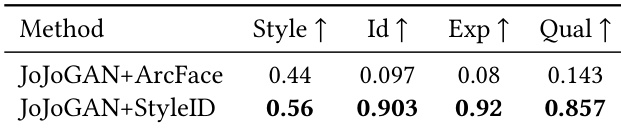
The authors evaluate StyleID against several baselines on the StyleBench-H dataset to assess identity preservation under stylization. The results demonstrate that StyleID consistently outperforms both general-purpose identity encoders and specialized stylized face recognition models across all reported verification metrics. StyleID achieves the highest True Positive Rate, verification accuracy, and AUROC compared to all baseline methods. Identity-focused models like ArcFace and AdaFace significantly outperform semantic encoders such as CLIP and SigLIP2 but still fall short of StyleID's performance. The specialized StylizedFace method shows improved results over general baselines but remains consistently lower than the proposed StyleID approach.
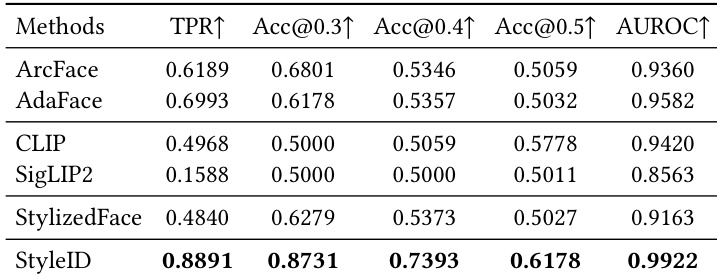
The provided the the table compares the proposed StyleID method against various baseline models on the StyleBench-H dataset across Cross-ID, Cross-Style, and Cross-Method evaluation settings. The results demonstrate that StyleID consistently outperforms all other methods, including specialized face recognition models and general-purpose semantic encoders. StyleID achieves the top performance in verification accuracy and True Positive Rate across all tested splits. The method shows significant improvement over baseline models in challenging Cross-Style and Cross-Method scenarios. General-purpose encoders like CLIP and SigLIP2 display lower performance compared to identity-focused models and the proposed approach.
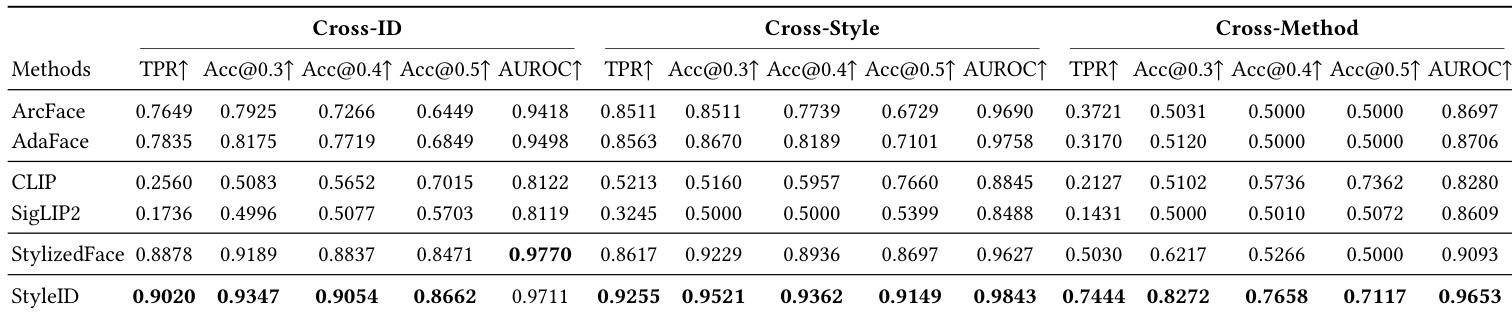
The authors conduct an ablation study to validate the contributions of the angular margin loss and supervised contrastive loss to the StyleID model. The results indicate that the full model, which combines both loss functions, consistently achieves the highest True Positive Rate and AUROC scores across both the StyleBench-H and SKSF-A datasets. Although removing the angular loss occasionally yields higher accuracy at a fixed threshold, the complete model demonstrates superior discriminability and robustness in verification tasks. The full StyleID model achieves the highest True Positive Rate and AUROC on both StyleBench-H Cross-ID and SKSF-A datasets compared to ablated variants. Removing the supervised contrastive loss leads to a significant degradation in performance, particularly evident in the drop of True Positive Rate on the SKSF-A dataset. While the variant without angular loss shows higher accuracy at a fixed threshold, the full model provides better overall separability between same-identity and different-identity pairs.
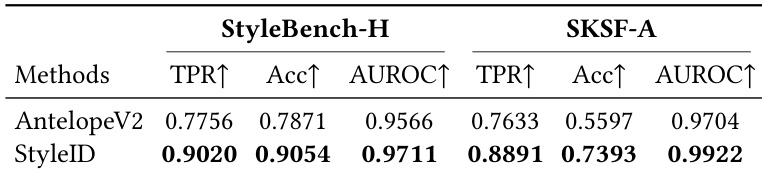
The authors compare the proposed StyleID method against the AntelopeV2 baseline on two stylized face recognition benchmarks. Results show that StyleID consistently outperforms the baseline across all metrics, demonstrating superior robustness to appearance shifts caused by stylization. StyleID achieves higher verification accuracy and true positive rates than AntelopeV2 on both StyleBench-H and SKSF-A datasets. The baseline model exhibits substantial performance degradation under stylization while StyleID remains robust. StyleID yields higher AUROC scores, indicating better separability of same-identity and different-identity pairs under artistic transformations.
The evaluation assesses the proposed StyleID method by integrating it into the JoJoGAN framework and comparing it against various baselines on the StyleBench-H and SKSF-A datasets. Results demonstrate that StyleID consistently outperforms existing identity encoders and specialized models in preserving identity and facial expressions while maintaining high style fidelity. Furthermore, ablation studies confirm that the combination of angular margin and supervised contrastive losses yields superior robustness and discriminability across challenging stylization scenarios.