Command Palette
Search for a command to run...
Diffusion Probabilistic Models의 SNR-t Bias 규명
Diffusion Probabilistic Models의 SNR-t Bias 규명
Meng Yu Lei Sun Jianhao Zeng Xiangxiang Chu Kun Zhan
초록
Diffusion Probabilistic Models는 다양한 생성 작업(generative tasks)에서 탁월한 성능을 입증해 왔습니다. 그러나 본 연구에서는 이러한 모델들이 흔히 SNR-timestep (SNR-t) 편향(bias) 문제를 겪는다는 점을 발견했습니다. 이 편향은 inference 단계에서 denoising 샘플의 SNR과 그에 대응하는 timestep 사이의 불일치를 의미합니다. 구체적으로, training 과정에서 샘플의 SNR은 timestep과 엄격하게 결합되어 있습니다. 하지만 inference 과정에서는 이러한 대응 관계가 깨지게 되며, 이는 오차 누적으로 이어져 생성 품질을 저하시킵니다.본 논문에서는 이러한 현상을 입증하기 위한 포괄적인 실증적 근거와 이론적 분석을 제공하며, SNR-t 편향을 완화하기 위한 단순하면서도 효과적인 미분 보정(differential correction) 방법을 제안합니다. Diffusion 모델이 역방향 denoising 과정에서 고주파(high-frequency) 세부 사항에 집중하기 전에 일반적으로 저주파(low-frequency) 성분을 먼저 재구성한다는 점에 착안하여, 우리는 샘플을 다양한 주파수 성분으로 분해하고 각 성분에 개별적으로 미분 보정을 적용합니다.광범위한 실험 결과, 제안된 방식은 계산 오버헤드를 거의 발생시키지 않으면서도 다양한 해상도의 데이터셋에서 여러 diffusion 모델(IDDPM, ADM, DDIM, A-DPM, EA-DPM, EDM, PFGM++, FLUX)의 생성 품질을 유의미하게 향상시킴을 확인했습니다. 코드는 다음 링크에서 확인할 수 있습니다: https://github.com/AMAP-ML/DCW.
One-sentence Summary
To mitigate the Signal-to-Noise Ratio-timestep (SNR-t) bias caused by the misalignment between sample SNR and timesteps during inference, the authors propose a differential correction method that decomposes samples into frequency components to enhance the generation quality of various diffusion models, including IDDPM, ADM, DDIM, A-DPM, EA-DPM, EDM, PFGM++, and FLUX, with negligible computational overhead.
Key Contributions
- The paper identifies the Signal-to-Noise Ratio-timestep (SNR-t) bias in Diffusion Probabilistic Models and provides a theoretical analysis and empirical evidence to explain how this mismatch between sample SNR and timesteps during inference leads to error accumulation.
- A dynamic differential correction method in the wavelet domain is introduced to alleviate this bias by decomposing samples into frequency components and applying targeted corrections based on the model's tendency to reconstruct low-frequency contours before high-frequency details.
- Extensive experiments demonstrate that this training-free and plug-and-play approach significantly improves the generation quality of various models, including IDDPM, EDM, and FLUX, across multiple datasets with negligible computational overhead.
Introduction
Diffusion Probabilistic Models (DPMs) have become essential for high-quality generative tasks such as image, audio, and video synthesis. However, these models often suffer from Signal-to-Noise Ratio-timestep (SNR-t) bias, where the signal-to-noise ratio of a sample during inference deviates from the ratio strictly coupled with its timestep during training. This misalignment, caused by cumulative prediction and discretization errors, leads to inaccurate noise predictions and degraded generation quality. The authors identify this fundamental bias through theoretical and empirical analysis and propose a training-free, plug-and-play differential correction method. By applying this correction within the wavelet domain, the authors allow the model to address different frequency components separately, effectively aligning the predicted sample distribution with the ideal perturbed distribution.
Method
The authors leverage a diffusion probabilistic model (DPM) framework, which operates through a forward diffusion process and a reverse denoising process, both modeled as Markov chains. The forward process gradually adds Gaussian noise to a data sample x0 according to a variance schedule βt, resulting in a sequence of noisy samples x1,…,xT. This process is defined as q(x1:T∣x0)=∏t=1Tq(xt∣xt−1), where q(xt∣xt−1)=N(xt;1−βtxt−1,βtI). The reverse process, which is the core of generation, aims to invert this noise addition step-by-step to recover the original data. A neural network, pθ(xt−1∣xt), is trained to approximate the reverse transition distribution q(xt−1∣xt,x0), specifically to predict the noise ϵt present at timestep t. This network, ϵθ(⋅), is trained to minimize the L2 distance between its predicted noise and the actual noise ϵt, leading to the simple objective Lsimple=Et,x0,ϵt∼N(0,I)[∣∣ϵθ(xt,t)−ϵt∣∣22]. Once trained, the model can generate samples by starting from a standard Gaussian noise xT and iteratively denoising using the learned network pθ(xt−1∣xt).
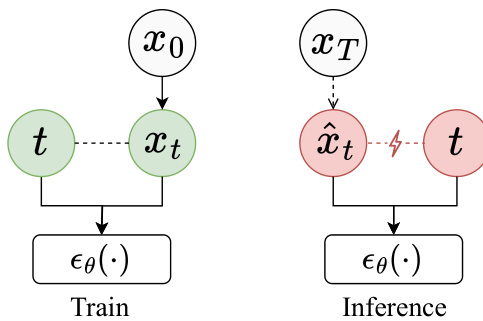
The paper identifies a theoretical bias in this process, termed SNR-t bias, where the Signal-to-Noise Ratio (SNR) of the predicted sample x^t during inference does not match the expected SNR at its corresponding timestep t. To address this, the authors propose a differential correction method. The core idea is that the difference between the predicted sample x^t−1 and the reconstructed sample xθ0(x^t,t) (the output of the noise prediction network) contains a directional signal that can be used to guide the prediction toward a more accurate, lower-bias state. This differential signal is defined as x^t−1−xθ0(x^t,t), and its correction is integrated into the denoising step as x^t−1=x^t−1+λt(x^t−1−xθ0(x^t,t)), where λt is a scalar guidance factor. This correction is applied after the initial denoising step to enhance the sample quality without increasing computational cost.
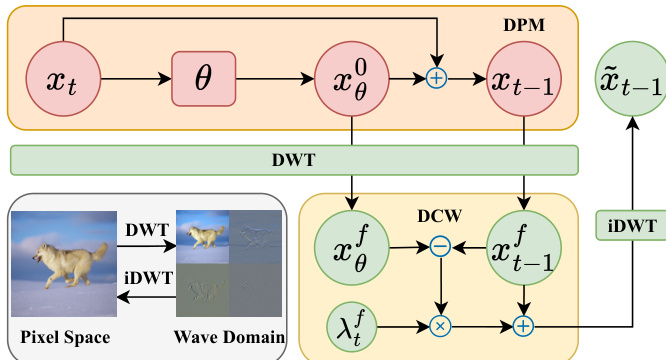
To further improve the correction, the authors introduce the Differential Correction in Wavelet Domain (DCW) framework, as shown in the figure above. This approach decomposes the predicted sample x^t−1 and the reconstructed sample xθ0(x^t,t) into four frequency subbands (LL, LH, HL, HH) using the Discrete Wavelet Transform (DWT). The differential correction is then applied separately to each subband, with the correction term λtf(x^t−1f−xθ0(x^t,t)f), where f represents the frequency component. This allows for targeted correction, as the low-frequency (LL) components, which capture the global structure, are prioritized early in the process, while the high-frequency components, which contain fine details, are emphasized later. The correction coefficients λtf are dynamically adjusted based on the denoising progress, typically using the reverse process variance σt as a guide. This wavelet-domain correction helps reduce the noise interference present in the differential signal, leading to more effective and focused refinement of the generated samples.
Experiment
Experiments investigate the SNR-t bias by analyzing how mismatched signal-to-noise ratios and timesteps affect network predictions, specifically finding that reverse denoising samples often exhibit lower SNR than intended. To address this, the proposed DCW method is evaluated across various diffusion frameworks and datasets to validate its ability to correct these errors. The results demonstrate that DCW consistently improves generation quality and aesthetic appeal with negligible computational overhead, even when integrated into existing bias-corrected models.
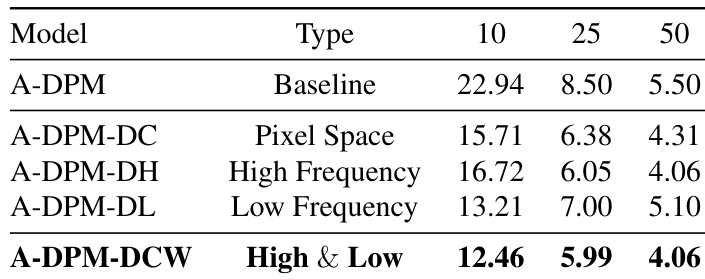
The experiment evaluates the impact of applying differential correction in different domains on generation quality. Results show that combining correction in both high and low frequency wavelet components yields the best performance, outperforming pixel space correction and single frequency corrections. Combined high and low frequency correction achieves the lowest FID scores. High frequency correction alone performs better than low frequency correction. Pixel space correction shows intermediate performance between single frequency and combined approaches.
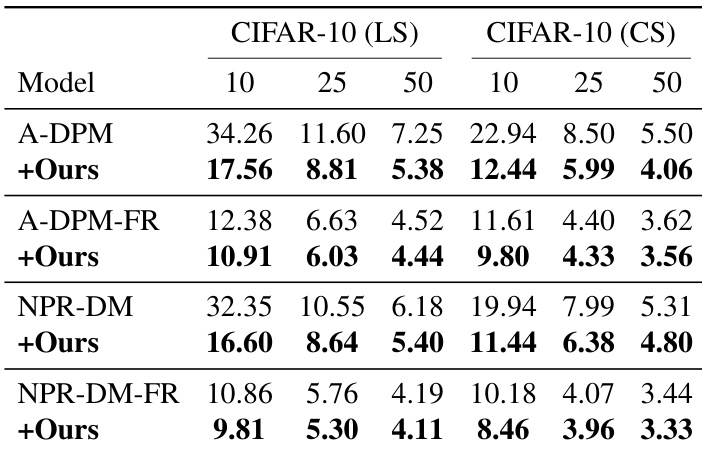
The the the table presents FID scores for several diffusion models on CIFAR-10 datasets under different sampling steps. The integration of the proposed method consistently reduces FID scores across all models and datasets, indicating improved generation quality. The results demonstrate the effectiveness of the method in enhancing model performance regardless of the baseline model or sampling step count. The proposed method reduces FID scores across all models and datasets, improving generation quality. The improvement is consistent across different sampling steps, indicating robustness. The method enhances performance on both low-step and high-step sampling scenarios.
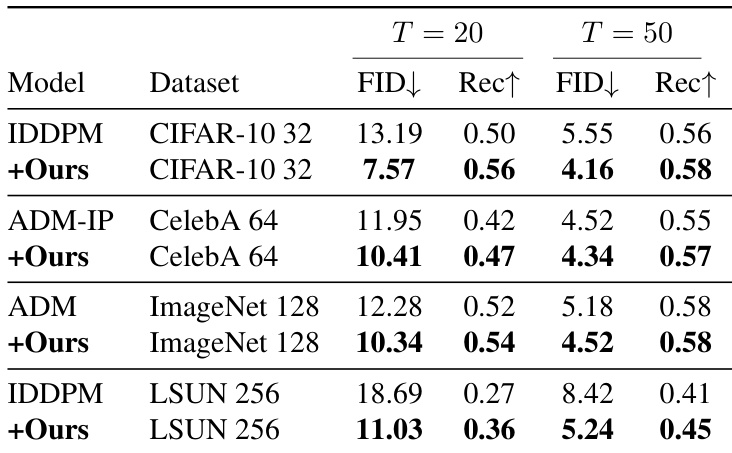
The the the table compares the signal-to-noise ratio (SNR) for forward and reverse samples in diffusion models. The SNR of reverse samples is shown to be lower than that of forward samples due to the mismatch between the actual SNR of denoised samples and the expected SNR at each timestep, leading to prediction errors during the denoising process. Reverse samples exhibit a lower SNR compared to forward samples at the same timestep. The SNR of reverse samples is influenced by the network's tendency to overestimate predictions when processing lower SNR inputs. The discrepancy in SNR between forward and reverse samples contributes to errors in the denoising trajectory.
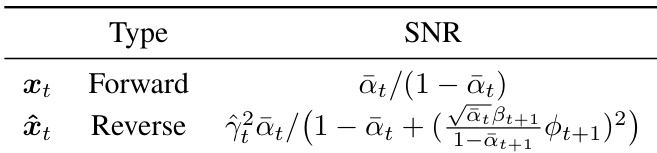
The experiment evaluates the computational overhead of the DCW method across different models and datasets. Results show that DCW introduces minimal additional time cost, with overhead percentages consistently low across all tested configurations. DCW adds negligible computational overhead to baseline models Overhead remains consistently low across different datasets and models The additional time cost is minimal and does not significantly impact generation speed
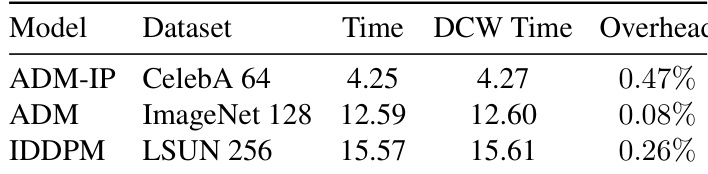
The authors evaluate their method across multiple diffusion models and datasets, demonstrating consistent improvements in generation quality. Results show that the proposed approach reduces FID scores and enhances Recall across various models and sampling steps, indicating improved fidelity and diversity. The method consistently reduces FID scores and improves Recall across different models and datasets. The approach enhances generation quality for both classic and bias-corrected diffusion models. The improvements are observed across varying sampling steps and model architectures.
These experiments evaluate the effectiveness of differential correction across various domains, sampling steps, and diffusion architectures to enhance generation quality. The results demonstrate that applying correction to both high and low frequency wavelet components yields superior performance and that the method consistently improves fidelity and diversity across different datasets. Furthermore, the analysis confirms that the proposed approach addresses SNR discrepancies in the denoising process while introducing negligible computational overhead.