Command Palette
Search for a command to run...
EVENT TENSOR: DYNAMIC MEGAKERNEL 컴파일을 위한 통합 추상화 모델
EVENT TENSOR: DYNAMIC MEGAKERNEL 컴파일을 위한 통합 추상화 모델
초록
현대적인 GPU 워크로드, 특히 Large Language Model (LLM) 추론은 커널 런칭 오버헤드(kernel launch overheads)와 거친 동기화(coarse synchronization) 문제로 인해 커널 간 병렬성(inter-kernel parallelism)이 제한되는 문제를 겪고 있습니다. 최근의 megakernel 기술은 여러 연산자(operator)를 하나의 persistent kernel로 융합하여 런칭 간극(launch gaps)을 제거하고 커널 간 병렬성을 확보하려 시도하고 있으나, 실제 워크로드에서 발생하는 동적 형태(dynamic shapes) 및 데이터 의존적 연산(data-dependent computation)을 처리하는 데 어려움을 겪고 있습니다.본 논문에서는 동적 megakernel을 위한 통합 컴파일러 추상화 계층인 Event Tensor를 제안합니다. Event Tensor는 타일링된 태스크(tiled tasks) 간의 의존성을 인코딩하며, 형태(shape)와 데이터 의존적 동적 특성(dynamism)을 모두 최우선적으로 지원(first-class support)합니다. 이러한 추상화 계층을 기반으로 구축된 Event Tensor Compiler (ETC)는 정적 및 동적 스케줄링 변환을 적용하여 고성능 persistent kernel을 생성합니다. 평가 결과, ETC는 시스템 웜업(warmup) 오버헤드를 대폭 줄이는 동시에 최첨단(state-of-the-art) 수준의 LLM 서빙 지연 시간(latency)을 달성함을 입증하였습니다.
One-sentence Summary
The authors present Event Tensor, a unified compiler abstraction for dynamic megakernels that encodes dependencies between tiled tasks to enable shape and data-dependent dynamism, and the Event Tensor Compiler applies static and dynamic scheduling transformations to generate high-performance persistent kernels achieving state-of-the-art LLM serving latency while significantly reducing system warmup overhead.
Key Contributions
- Event Tensor is introduced as a unified compiler abstraction that encodes dependencies between tiled tasks to enable first-class support for shape and data-dependent dynamism. This abstraction compactly represents fine-grained dependencies across operator sub-tasks for GPU streaming multiprocessors.
- Built atop this abstraction, the Event Tensor Compiler applies static and dynamic scheduling transformations to generate high-performance persistent kernels. The pipeline fuses operator implementations into megakernels to unlock inter-kernel parallelism beyond single operator patterns.
- Evaluations demonstrate that the system achieves state-of-the-art large language model serving latency while significantly reducing system warmup overhead. These results validate the effectiveness of the proposed scheduling transformations in real workloads.
Introduction
Modern GPU workloads like Large Language Model inference suffer from kernel launch overheads and coarse synchronization that limit inter-kernel parallelism. While megakernel techniques fuse operators to address launch costs, they struggle with the dynamic shapes and data-dependent computation required by real workloads. To solve this, the authors present Event Tensor, a unified compiler abstraction that encodes task dependencies as first-class symbolic objects to support shape and data-dependent dynamism. Their Event Tensor Compiler uses this abstraction to generate high-performance persistent kernels that achieve state-of-the-art latency with significantly reduced warmup overhead.
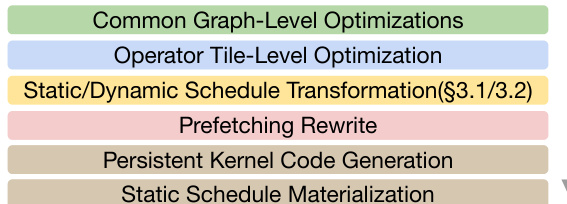
Method
The Event Tensor Compilation (ETC) framework optimizes GPU workloads through a specialized programming model and advanced compilation strategies. The system is built on three primary language constructs: Device Functions, Event Tensors, and Graph Functions. Device functions define parallel task grids, while Event Tensors serve as multi-dimensional structures representing task completion events with operations like notify() and wait(). Graph functions orchestrate these components, explicitly managing dependencies.
Refer to the example below which demonstrates an IRModule where a summation task is partitioned, and dependencies are tracked using Event Tensors with specific coordinate mappings.

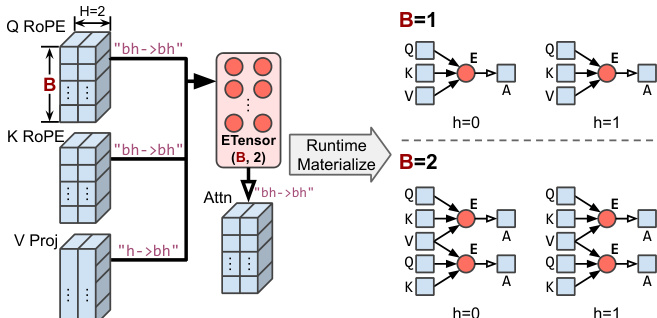
Handling Dynamism A key feature of ETC is its ability to handle both shape and data-dependent dynamism without recompilation. For shape dynamism, the system utilizes symbolic-shape Event Tensors that act as templates for different runtime shapes.
Refer to the diagram below which illustrates how a symbolic batch size B allows the dependency graph to adapt dynamically to different input sizes.
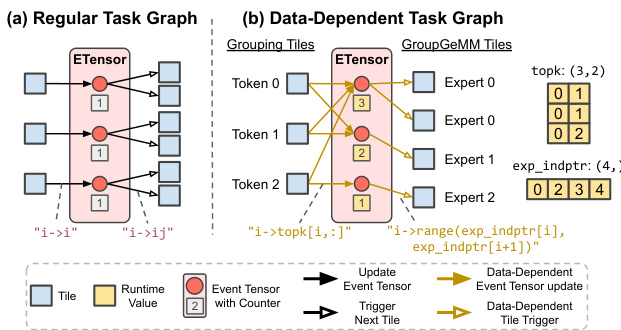
For data-dependent dynamism, such as in Mixture-of-Experts (MoE) layers, the system supports irregular task graphs where dependencies are determined at runtime.
Refer to the comparison below which contrasts a regular static task graph with a data-dependent task graph where runtime tensors define dynamic event updates and task triggers.
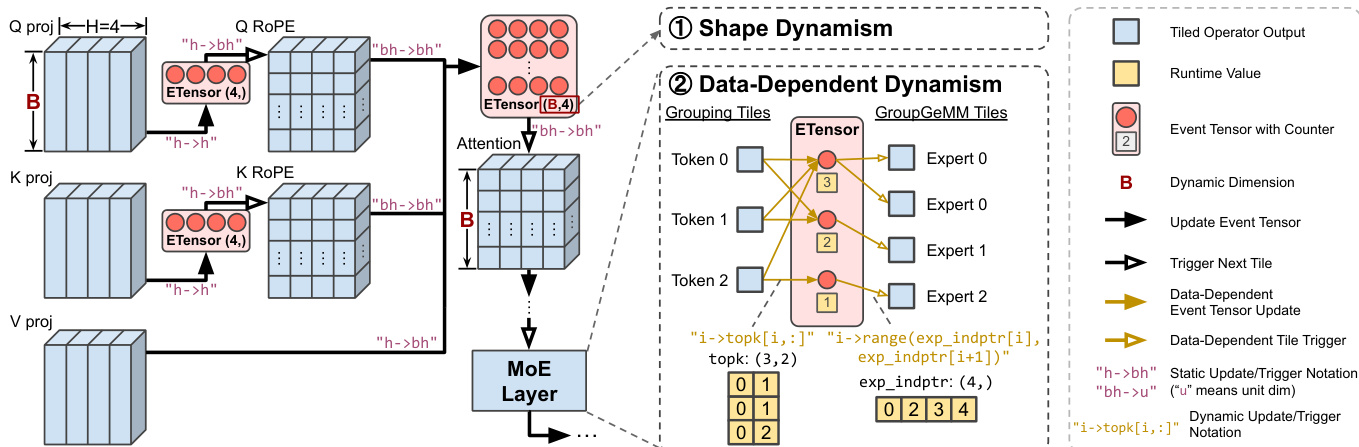
This capability is essential for complex workloads like Attention and MoE layers, where dynamic routing and variable shapes are common.
Refer to the high-level workflow below which depicts the flow from projections to MoE layers, highlighting the points where shape and data-dependent dynamism are managed.
Scheduling Strategies
The compilation process transforms the computational graph into optimized megakernels using either static or dynamic scheduling. The figure below contrasts traditional kernel launches and CUDA Graphs with the proposed megakernel approach, which minimizes launch overhead and manages dependencies within the kernel.
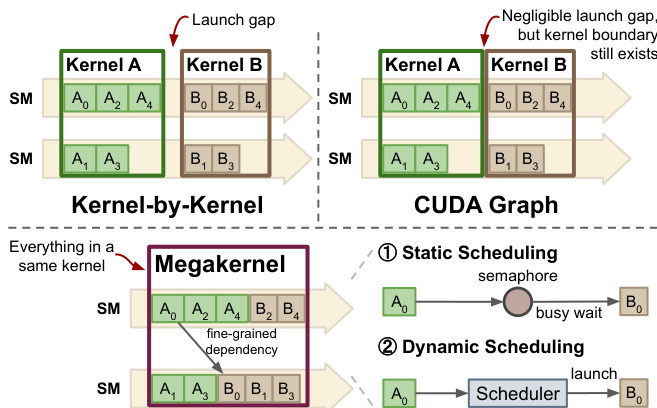
In static scheduling, multiple device functions are fused into a single persistent kernel with tasks pre-assigned to specific SMs.
Refer to the code transformation below which shows GEMM and Reduce-Scatter functions being fused, with explicit notify and wait calls inserted to enforce execution order.
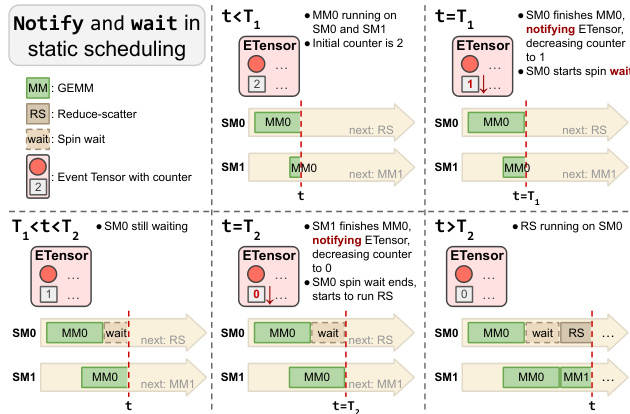
The mechanism relies on low-level synchronization where tasks wait for event counters to reach zero before proceeding.
Refer to the diagram below which visualizes the notify-and-wait mechanism, showing how an SM waits for dependent tasks on other SMs to complete.
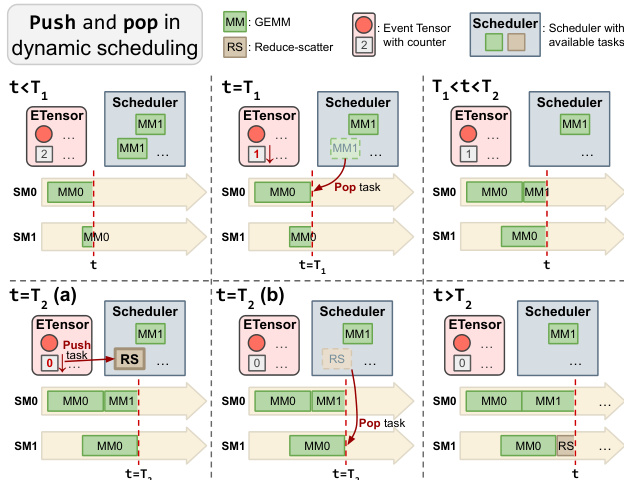
For unpredictable workloads, dynamic scheduling is employed, utilizing an on-GPU task scheduler where SMs atomically pop ready tasks.
Refer to the code transformation below which illustrates the push-pop mechanism where tasks are pushed to the scheduler upon dependency resolution.
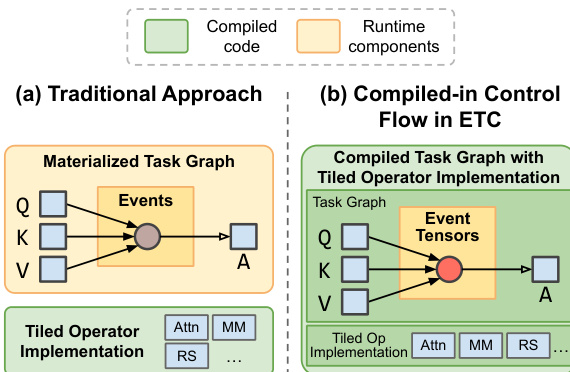
Runtime Architecture Finally, ETC minimizes runtime overhead by compiling scheduling logic directly into the megakernels, avoiding the need to materialize the entire task graph in memory.
Refer to the comparison below which contrasts the traditional runtime executor with ETC's approach of embedding scheduling logic into the compiled kernel.
Experiment
Conducted on NVIDIA B200 GPUs, the evaluation benchmarks ETC against leading systems to assess how the Event Tensor abstraction manages fine-grained dependencies in both static and dynamic task graphs. Experiments demonstrate that fused megakernels lower end-to-end latency in low-batch serving and Mixture-of-Experts layers through improved pipelining and load balancing. Additionally, the framework eliminates runtime warmup overhead via ahead-of-time compilation and reveals distinct performance trade-offs between static and dynamic scheduling strategies for different workload types.
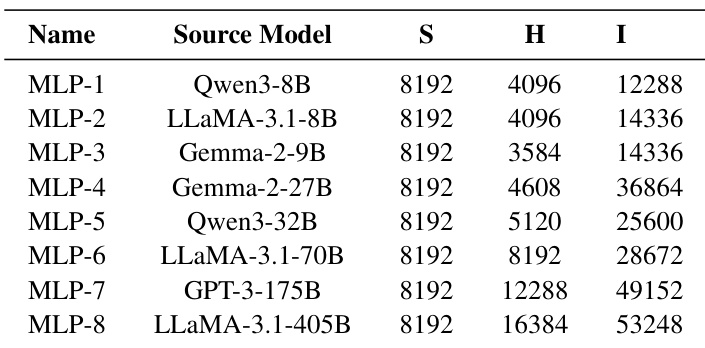
The the the table presents MLP configurations derived from a diverse set of modern large language models to evaluate fused communication and computation performance. While the sequence length remains constant across all entries, the hidden dimensions and intermediate sizes scale significantly to represent models ranging from smaller to massive architectures. This variety allows for assessing the system's effectiveness across different computational complexities and model scales. Configurations span a wide spectrum of model sizes, from smaller to massive architectures. A consistent sequence length is maintained across all tested model configurations. Hidden dimensions and intermediate sizes increase progressively as the model scale grows.
The authors analyze the trade-offs between static and dynamic scheduling strategies on a data-dependent Mixture-of-Experts (MoE) workload. The results demonstrate that dynamic scheduling generally yields higher relative performance for larger workloads due to better load balancing, while static scheduling is slightly more efficient for the smallest workload size. Dynamic scheduling provides superior relative performance compared to static scheduling for all token counts except the smallest. Static scheduling maintains a consistent performance advantage over dynamic scheduling when processing a single token. The dynamic scheduler achieves its maximum relative gain over the baseline at intermediate token counts before converging with the static method at higher counts.

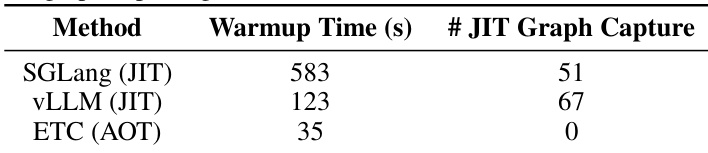
The authors evaluate the warmup overhead of ETC against JIT-based systems like SGLang and vLLM to assess deployment impact. Results demonstrate that ETC's ahead-of-time compilation strategy eliminates the need for runtime graph capture, leading to a substantial reduction in initialization time compared to baselines that require capturing multiple static graphs. ETC achieves significantly faster warmup performance compared to both SGLang and vLLM. The proposed method requires zero runtime JIT graph captures, whereas baselines require numerous captures. Baseline systems incur high warmup costs due to the necessity of capturing static graphs to handle shape variations.
The authors evaluate the performance trade-offs between static and dynamic scheduling strategies on a regular, dense transformer workload with tensor parallelism. The results show that static scheduling consistently delivers higher relative performance than dynamic scheduling across all batch sizes, suggesting that the overhead of dynamic task management negatively impacts efficiency for regular workloads. Static scheduling consistently outperforms dynamic scheduling across all batch sizes. Dynamic scheduling shows reduced relative performance compared to the static approach. The performance advantage of static scheduling remains stable as batch size increases.
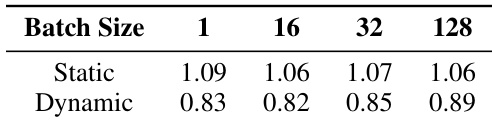
The study evaluates system effectiveness across diverse model scales and scheduling strategies to assess fused communication and computation performance. Results indicate that dynamic scheduling benefits data-dependent Mixture-of-Experts workloads through improved load balancing, while static scheduling yields higher efficiency for regular dense transformer workloads. Additionally, the proposed ETC strategy significantly reduces initialization overhead by avoiding the runtime graph captures required by baseline JIT systems.