Command Palette
Search for a command to run...
PersonaVLM: 장기적 개인화 멀티모달 LLMs
PersonaVLM: 장기적 개인화 멀티모달 LLMs
Chang Nie Chaoyou Fu Yifan Zhang Haihua Yang Caifeng Shan
초록
제시해주신 영문 텍스트를 요청하신 기술 번역 기준에 맞춰 한국어로 번역한 결과입니다. (참고: 요청사항에 "한국어로 답하라"고 되어 있어, 기술적 정확성을 기하기 위해 한국어로 번역을 진행하였습니다.)[번역문]Multimodal Large Language Models (MLLMs)는 수백만 명의 일상적인 어시스턴트 역할을 수행하고 있습니다. 그러나 사용자의 개별적인 선호도에 맞춘 응답을 생성하는 능력은 여전히 제한적입니다. 기존의 방식들은 입력 증강(input augmentation)이나 출력 정렬(output alignment)을 통해 정적인 단발성 개인화(single-turn personalization)만을 가능하게 하므로, 시간이 흐름에 따라 변화하는 사용자의 선호도와 페르소나를 포착하지 못한다는 한계가 있습니다 (그림 1 참조).본 논문에서는 장기적인 개인화를 위해 설계된 혁신적인 개인화 멀티모달 Agent 프레임워크인 PersonaVLM을 소개합니다. PersonaVLM은 다음과 같은 세 가지 핵심 기능을 통합하여 범용 MLLM을 개인화된 어시스턴트로 변환합니다:(a) Remembering (기억): 상호작용으로부터 연대순의 멀티모달 메모리를 능동적으로 추출 및 요약하여, 이를 개인화된 데이터베이스로 통합합니다.(b) Reasoning (추론): 데이터베이스에서 관련 메모리를 검색(retrieval)하고 통합함으로써 다회차(multi-turn) 추론을 수행합니다.(c) Response Alignment (응답 정렬): 장기적인 상호작용 전반에 걸쳐 변화하는 사용자의 페르소나를 추론하여, 출력 결과가 사용자의 고유한 특성과 일치하도록 보장합니다.평가를 위해, 본 연구에서는 7개의 핵심 측면과 14개의 세분화된 태스크를 통해 MLLM의 장기적 개인화 능력을 측정할 수 있도록 설계된 2,000개 이상의 엄선된 상호작용 사례로 구성된 종합 benchmark인 Persona-MME를 구축하였습니다. 광범위한 실험을 통해 본 방법론의 효과를 검증한 결과, 128k context 환경에서 baseline 대비 Persona-MME는 22.4%, PERSONAMEM은 9.8% 향상되었으며, GPT-4o를 각각 5.2%와 2.0% 차이로 상회하는 성능을 기록했습니다.프로젝트 페이지: https://PersonaVLM.github.io
One-sentence Summary
To address the limitations of static personalization in multimodal large language models, the authors propose PersonaVLM, a framework that enables long-term user alignment through proactive multimodal memory extraction, multi-turn reasoning, and evolving personality inference, significantly outperforming baselines on the newly established Persona-MME benchmark.
Key Contributions
- The paper introduces PersonaVLM, a unified agent framework that enables long-term, dynamic personalization for Multimodal Large Language Models through the integration of proactive memory extraction, multi-turn reasoning via memory retrieval, and evolving response alignment.
- This work presents Persona-MME, a comprehensive benchmark consisting of over 2,000 curated interaction cases designed to evaluate long-term personalization across seven key aspects and 14 fine-grained tasks.
- Experimental results demonstrate that PersonaVLM significantly improves personalization capabilities, outperforming both proprietary models like GPT-4o and leading open-source alternatives by 22.4% on the Persona-MME benchmark.
Introduction
As Multimodal Large Language Models (MLLMs) become daily assistants, there is a growing need for them to move beyond general problem solving toward personalized, long-term interactions. Current personalization strategies are largely limited to static, single-turn approaches through input augmentation or output alignment. These methods fail to capture evolving user preferences and cannot adapt to personality shifts that occur over extended periods of interaction.
The authors leverage a new agent framework called PersonaVLM to achieve dynamic, long-term personalization. The framework integrates three core capabilities: proactive multimodal memory management, multi-turn reasoning through retrieval, and response alignment that adapts to a user's evolving personality. To support this, the authors introduce a specialized memory architecture and a comprehensive benchmark named Persona-MME to evaluate multi-faceted personalization performance.
Dataset
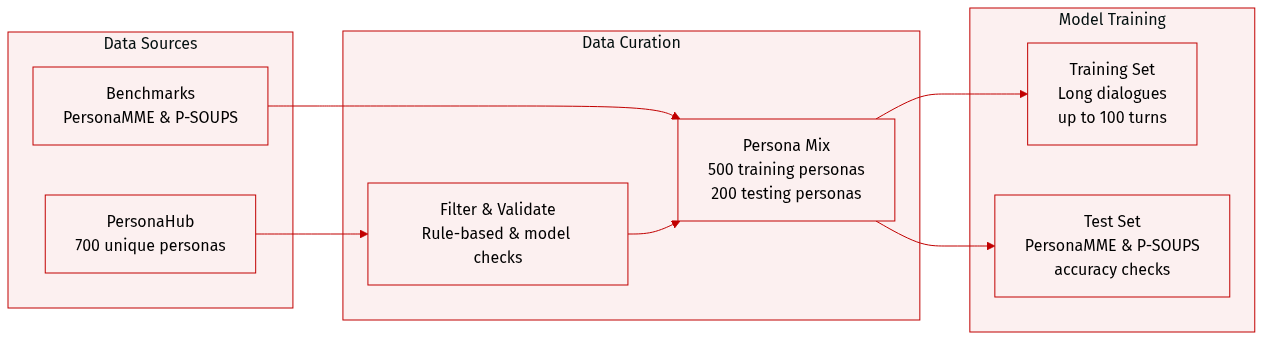
Dataset Overview
The authors utilize a combination of synthesized long-term multimodal dialogue data and established benchmarks to train and evaluate their model:
-
Synthesized Multimodal Dialogue Dataset
- Composition and Sources: The authors synthesized a large-scale dataset by sampling 700 unique personas from PersonaHub.
- Subsets and Distribution: The data is split into 500 personas for training and 200 personas for testing. Training dialogues consist of 20 to 100 turns and simulate a timeframe of up to one month.
- Processing and Validation: To ensure quality, accuracy, and safety, the authors implemented a two-stage filtering process involving rule-based checks and model-based validation. During synthesis, the model generates structured metadata, including timestamps and dialogue turn indices for episodic topics, which are used for data validation.
-
Evaluation Benchmarks
- PERSONAMEM: This benchmark evaluates timeline-aware conversational abilities through synthetic, multi-session data. The authors conduct evaluations using two context-length settings: 32k and 128k. The 128k setting is created by sampling half of the original 2,728 personas, resulting in 1,362 multiple-choice questions, while the 32k setting includes 589 questions.
- P-SOUPS: This benchmark measures personalization across three dimensions: Expertise, Informativeness, and Style. It contains 1,800 total test cases (600 per dimension). Each case provides a user prompt, a profile, and a pair of responses (one chosen and one rejected), requiring the model to select the profile-aligned response. For few-shot experiments, the authors augment inputs with a single example of Pair-wise Comparative Feedback.
Method
The PersonaVLM framework is designed to enable long-term personalization through a dual-stage process comprising a Response stage and an Update stage, both operating within a personalized memory architecture. The overall system architecture, as illustrated in the framework diagram, centers on a multimodal input that includes a user query, a profile, and conversation context. This input is processed by the PersonaVLM model, which interacts with a personalized memory system composed of four distinct memory types: Core Memory, Semantic Memory, Episodic Memory, and Procedural Memory. These memories are stored and managed to maintain a comprehensive, long-term user profile. The system's operation is structured around two collaborative phases: the Response stage, which generates context-aware, personalized responses, and the Update stage, which evolves the user's personality profile and proactively updates the memory database during idle periods.
The Response stage is responsible for generating a personalized response Rm at turn m by performing multi-step reasoning and timeline-based retrieval. This process is initiated with the user's current query Qm, which consists of a text instruction, an optional image, and a timestamp, along with the dialogue context Cm and the state of the personalized memory database Mm−1. The implementation of this stage involves a multi-step interaction between the PersonaVLM agent and its memory system. In the initial step, the model is prompted with the user's instruction, context, and a consolidated profile. The model then outputs a detailed reasoning process and an action result. If the model determines that retrieval is necessary, it generates retrieval conditions, including a time period and keywords, which are used to search the memory database. The agent isolates memories within the inferred time period and performs a parallel search across semantic, episodic, and procedural memory types. The top-k results from each type are collected and fed back to the model to initiate the next reasoning step. This iterative process continues until the model outputs the final response. This design enables precise retrieval by allowing the model to determine not just what to retrieve, but also if retrieval is necessary and from when, thereby addressing the limitations of direct semantic retrieval and the neglect of temporal cues.
The Update stage, which executes automatically after a response is generated, is responsible for evolving the user's personality profile and proactively updating the memories. This stage updates the user's personality profile, Pm, using the proposed Personality Evolving Mechanism (PEM). The PEM maintains a long-term personality profile as a vector p∈R5, corresponding to the Big Five dimensions. At each turn m, the PEM infers a temporary personality vector pm′ from the user's latest query and updates the long-term profile using an exponential moving average (EMA) with a dynamic smoothing factor λ. To ensure high adaptability in early conversations while promoting stability over time, a cosine decay schedule is employed for λ. The updated numerical vector pm is then converted back into a descriptive textual summary, Pm, for use in the Response Stage. The memory types are updated selectively: semantic memory is updated after each turn by extracting and storing key information; core and procedural memory are updated at the end of each session through automated CRUD operations; and episodic memory is constructed by segmenting dialogues into topic-based entries, each containing a summary, keywords, and relevant dialogue turns.
The training of PersonaVLM is conducted in two stages using the Qwen2.5-VL-7B model as the backbone. The first stage is Supervised Fine-Tuning (SFT) on a curated synthetic dataset of 78k samples to equip the model with foundational memory management and multi-turn reasoning skills. The training data consists of examples for memory mechanisms, including personality inference and the four types of memory CRUD operations, as well as QA pairs with complete multi-step reasoning trajectories. After SFT, the model is capable of generating well-formed reasoning and retrieval actions. The second stage is Reinforcement Learning (RL), which aims to further enhance the model's multi-turn reasoning capability. This stage employs Group Relative Policy Optimization (GRPO), an improved PPO algorithm, to train the policy model πθ. During generation, a strictly structured output format is enforced, requiring the model to first output its reasoning process within <think> tags, followed by either retrieval conditions in <retrieve> tags or the final response in <answer> tags. For each training sample, a group of multi-turn trajectories is sampled, and the reward is calculated based on accuracy, logical consistency, and format adherence. The advantage for each trajectory is computed by standardizing its reward within the sampled group.
Experiment
The evaluation utilizes the newly constructed Persona-MME benchmark and the existing PERSONAMEM dataset to assess multimodal large language models across dimensions such as memory, intent, and personality alignment. Experiments validate the PersonaVLM framework by testing its ability to recall long-term user information, align with evolving personality traits, and perform personalized open-ended generation. Findings demonstrate that PersonaVLM significantly outperforms strong open-source models and achieves competitive results against proprietary models like GPT-4o, particularly in complex tasks involving growth modeling and behavioral awareness. Qualitative analysis further confirms that the framework's multi-step reasoning and integrated memory components effectively prevent hallucinations and maintain consistent tonal alignment during long-term interactions.
{"caption": "Persona-MME dataset statistics", "summary": "The the the table presents key statistics for the Persona-MME benchmark, highlighting the average dialogue length, multimodal content proportion, and question and answer lengths. These metrics reflect the benchmark's design for evaluating long-term personalization in multimodal interactions.", "highlights": ["The average dialogue spans over 140 turns, indicating extensive conversational history for evaluation.", "Approximately 15.87% of turns in the dataset are multimodal, emphasizing the inclusion of visual and textual inputs.", "A significant portion of questions require visual information, with 34.02% being image-related, underscoring the multimodal nature of the benchmark."]
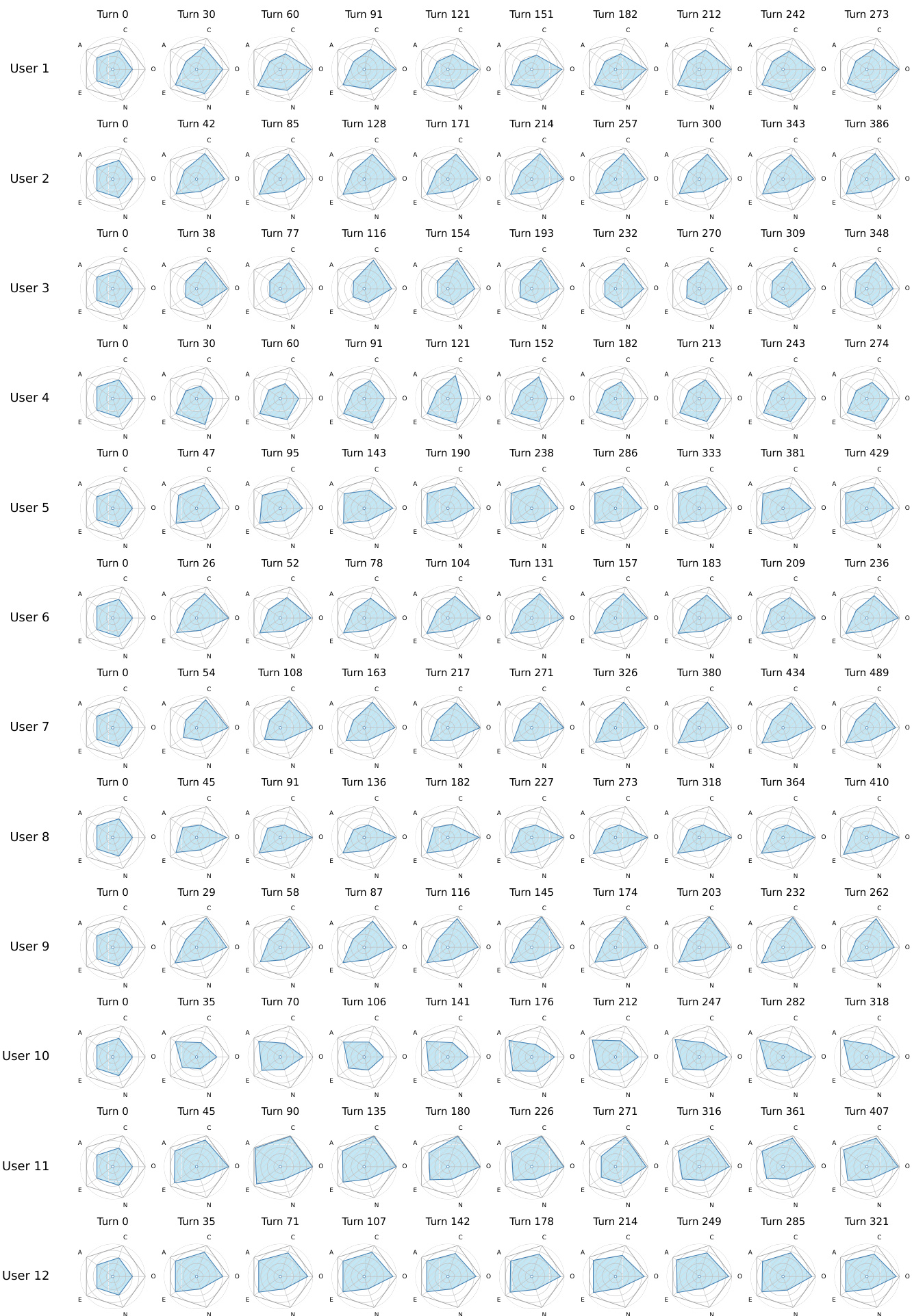
The figure visualizes the dynamic evolution of personality traits for multiple users across a series of conversation turns. Each user's personality profile is represented as a radar chart that changes over time, showing shifts in traits such as openness, conscientiousness, and extraversion as interactions progress. Personality traits change over time for each user as interactions progress. The radar charts show distinct patterns of trait evolution across different users. The visualizations highlight longitudinal changes in user characteristics during extended conversations.
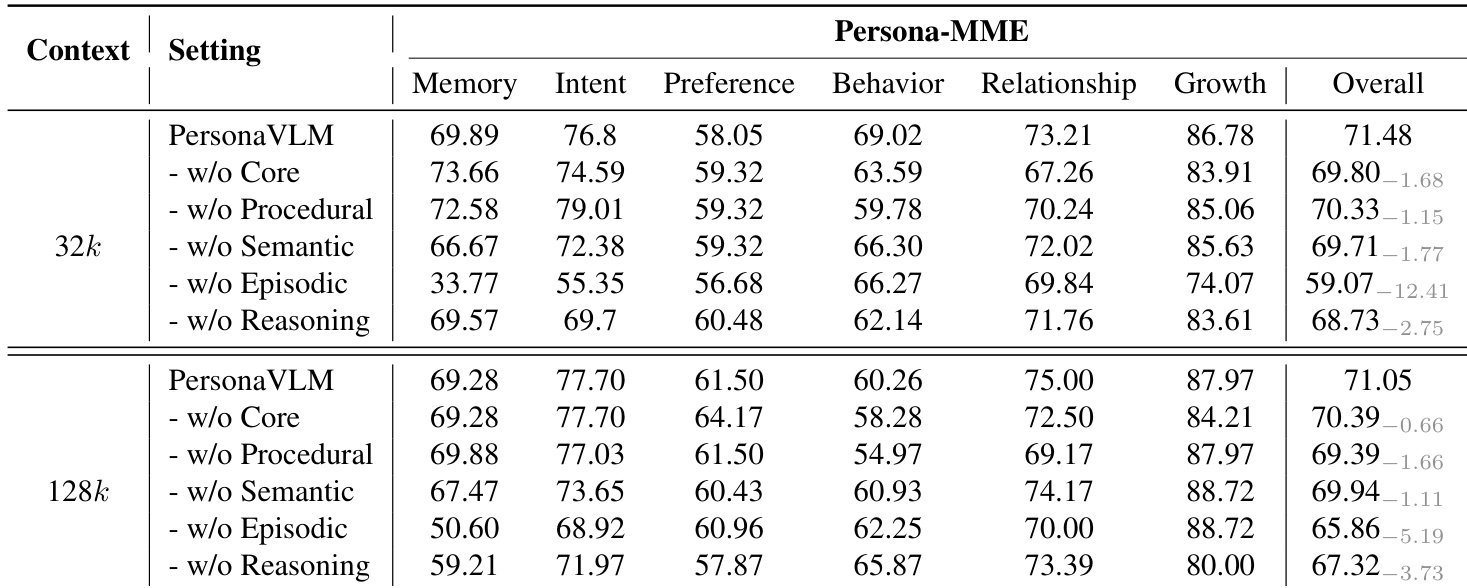
The the the table presents an ablation study on the Persona-MME benchmark, evaluating the impact of removing key components of the PersonaVLM framework. Results show that the full model achieves the highest performance across all context settings, with significant drops observed when specific components like episodic memory or reasoning are removed, indicating their critical role in long-term personalization. Removing episodic memory causes the largest performance drop in both context settings. The reasoning component contributes to improved performance, especially in the 128k context. All memory types and reasoning are essential, as their removal degrades overall performance.
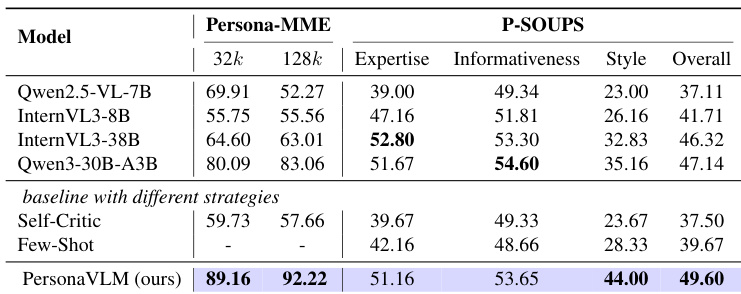
The the the table presents a comparison of various models on the Persona-MME and P-SOUPS benchmarks, focusing on performance across different context lengths and alignment dimensions. Results show that the proposed PersonaVLM model achieves competitive or superior performance, particularly in the 128k context setting and across key alignment metrics. PersonaVLM achieves the highest scores on the 128k context setting and overall alignment metrics. The model outperforms baseline models with different strategies, including Self-Critic and Few-Shot. PersonaVLM shows significant improvements in expertise and style alignment compared to other models.
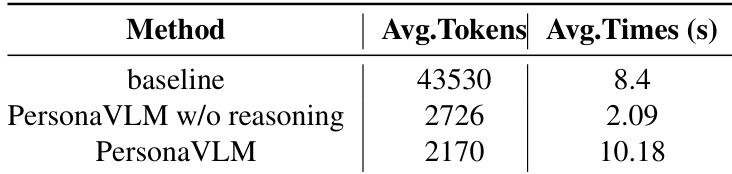
The the the table compares the efficiency of PersonaVLM with and without reasoning against a baseline model, measuring average token consumption and response time. Results show that disabling reasoning significantly reduces token usage and speeds up responses, while adding reasoning further reduces tokens but increases latency. Disabling reasoning reduces token consumption and response time significantly compared to the baseline. Adding reasoning further reduces token usage but increases response time compared to the non-reasoning version. PersonaVLM without reasoning achieves a 93.7% reduction in token consumption and a 4.8x speedup over the baseline.
The Persona-MME benchmark evaluates long-term multimodal personalization through extensive dialogue histories and evolving user personality traits. Ablation studies and comparative evaluations demonstrate that the PersonaVLM framework excels in expertise and style alignment, particularly in long-context settings, by leveraging critical components such as episodic memory and reasoning. While incorporating reasoning enhances performance and reduces token consumption, it introduces a trade-off by increasing response latency.