Command Palette
Search for a command to run...
KnowRL: Minimal-Sufficient Knowledge Guidance를 이용한 Reinforcement Learning 기반 LLM Reasoning 능력 향상
KnowRL: Minimal-Sufficient Knowledge Guidance를 이용한 Reinforcement Learning 기반 LLM Reasoning 능력 향상
초록
RLVR은 대규모 언어 모델(LLM)의 추론 능력을 향상시키지만, 난도가 높은 문제에서는 심각한 보상 희소성(reward sparsity) 문제로 인해 그 효과가 제한되는 경우가 많습니다. 최근의 힌트 기반 RL 방법들은 부분적인 해법이나 추상적인 템플릿을 주입하여 이러한 희소성을 완화하려 시도하고 있으나, 일반적으로 더 많은 token을 추가하여 가이드를 확장하는 방식을 취합니다. 이는 불필요한 중복성(redundancy), 불일치(inconsistency), 그리고 추가적인 training overhead를 유발한다는 단점이 있습니다.본 논문에서는 힌트 설계를 '최소 충분 가이드 문제(minimal-sufficient guidance problem)'로 다루는 RL training 프레임워크인 KnowRL(Knowledge-Guided Reinforcement Learning)을 제안합니다. RL training 과정에서 KnowRL은 가이드를 원자적 지식 포인트(atomic knowledge points, KPs)로 분해하며, 제약된 부분집합 탐색(Constrained Subset Search, CSS)을 사용하여 학습을 위한 조밀하고 상호작용을 고려한(interaction-aware) 부분집합을 구성합니다. 나아가, 우리는 하나의 KP를 제거하는 것은 도움이 될 수 있지만 여러 개의 KP를 동시에 제거하는 것은 오히려 해가 될 수 있다는 '가지치기 상호작용 역설(pruning interaction paradox)'을 식별하였으며, 이러한 의존성 구조 하에서 강건한 부분집합 큐레이션을 명시적으로 최적화합니다.우리는 OpenMath-Nemotron-1.5B를 바탕으로 KnowRL-Nemotron-1.5B를 training하였습니다. 1.5B 규모의 8개 추론 benchmark 테스트 결과, KnowRL-Nemotron-1.5B는 강력한 RL 및 힌트 제공 baseline 모델들을 일관되게 능가했습니다. 추론(inference) 시 KP 힌트 없이도 KnowRL-Nemotron-1.5B는 평균 정확도 70.08%를 달성하여, 기존 Nemotron-1.5B보다 9.63포인트 높은 성능을 보였습니다. 또한 선택된 KP를 활용할 경우 성능은 74.16%까지 향상되어, 해당 규모에서 새로운 SOTA(state of the art)를 기록했습니다. 모델, 큐레이션된 training 데이터 및 코드는 https://github.com/Hasuer/KnowRL 에서 공개적으로 이용 가능합니다.
One-sentence Summary
The authors propose KnowRL, a reinforcement learning framework that enhances large language model reasoning by treating hint design as a minimal-sufficient knowledge problem, utilizing Constrained Subset Search to select compact, interaction-aware knowledge points that allow KnowRL-Nemotron-1.5B to achieve state-of-the-art performance across eight reasoning benchmarks.
Key Contributions
- The paper introduces KnowRL, a reinforcement learning training framework that treats hint design as a minimal-sufficient guidance problem by decomposing guidance into atomic knowledge points.
- This work presents Constrained Subset Search (CSS), a selection strategy that constructs compact, interaction-aware subsets of knowledge points to address the pruning interaction paradox where removing specific combinations of points can degrade performance.
- Experimental results across eight reasoning benchmarks demonstrate that the KnowRL-Nemotron-1.5B model achieves a new state of the art at the 1.5B scale, reaching 74.16 average accuracy when using selected knowledge point hints.
Introduction
Reinforcement Learning from Verifiable Rewards (RLVR) is essential for improving reasoning in large language models, but it often struggles with reward sparsity when models fail to generate correct answers on difficult tasks. While existing hint-based methods attempt to mitigate this by injecting partial solutions or reasoning templates, they often rely on excessive guidance that introduces redundancy, conceptual ambiguity, and increased computational overhead. The authors propose KnowRL, a framework that treats hint design as a minimal-sufficient guidance problem by decomposing information into atomic knowledge points (KPs). They introduce a Constrained Subset Search (CSS) strategy to identify the smallest, most effective subsets of KPs required to unlock rewards, specifically addressing a pruning interaction paradox where KPs exhibit complex dependencies. This approach allows the model to achieve state-of-the-art reasoning performance at the 1.5B scale while maintaining significantly more compact and efficient training guidance.
Dataset

Dataset Description
The authors construct the KnowRL training dataset through a multi-stage curation and processing pipeline:
-
Dataset Composition and Sources
- The core training data is derived from the open-source QuestA dataset.
- After deduplication, the authors retained 8.8k unique training instances.
-
Knowledge Point (KP) Extraction and Refinement
- Grounding: To ensure reasoning accuracy, the authors first sample responses from DeepSeek-R1 for each problem until a correct solution is obtained.
- Extraction: Using the problem and the verified solution, DeepSeek-R1 is prompted to extract only the essential mathematical principles, creating an initial set of candidate KPs.
- Verification: To prevent data leakage and ensure generalizability, DeepSeek-R1 acts as an automated reviewer to verify each KP. Any KPs that are instance-bound rather than generalizable are manually revised.
-
Data Processing and Selection
- Compactness Strategy: Rather than using all raw KPs, which can lead to cross-hint inconsistency, the authors apply a Compact Subset Selection (CSS) strategy. This process reduces the number of KPs by approximately 38% to create more efficient training hints.
- Sampling Procedure: For each training instance, the authors sample 32 generations using a top_p of 0.9 and a temperature of 0.9. This procedure is repeated over 8 independent runs to build the final training set.
Method
The authors present KnowRL, a framework designed to enhance mathematical reasoning through structured knowledge point (KP) curation and selection. At a high level, KnowRL follows an end-to-end workflow: for each training problem, it first constructs a set of candidate KPs, then filters out leakage and redundancy to obtain a compact, problem-specific subset, and finally uses this curated subset as hint data for reinforcement learning (RL) training only when necessary. The core technical contribution of KnowRL lies in the construction and selection of high-quality KP data, which is performed offline before any RL training begins to ensure reproducibility and efficiency.
The KP construction process begins with the extraction of raw knowledge points from correct solutions. This stage, illustrated in the framework diagram, involves a prompt-based extraction step where the system is given a problem and its correct solution. The task is to identify the essential mathematical knowledge required to solve the problem, focusing on core concepts that are indispensable, general, and mathematically fundamental. The extracted KPs are not meant to reproduce the full solution or explain reasoning steps but to capture the key principles and conditions that must be applied. As shown in the figure below, the output is a concise, numbered list of knowledge points, each accompanied by key considerations that are crucial for their application.

Following extraction, a leakage verification step ensures the quality and independence of the KPs. This stage treats the system as an expert reviewer for mathematical reasoning datasets. Given a problem and a candidate knowledge description, the task is to determine whether the description is strongly coupled to the problem. A knowledge point is deemed strongly coupled if it contains specific numerical values, unique variable names, or configurations that are tied to the problem's structure. The goal is to filter out KPs that are overly specific or leak information from the problem itself, ensuring that the resulting KPs are generalizable and can be used effectively as hints for similar problems. The verification process requires a JSON-formatted response indicating whether the knowledge is strongly coupled and provides a brief explanation.

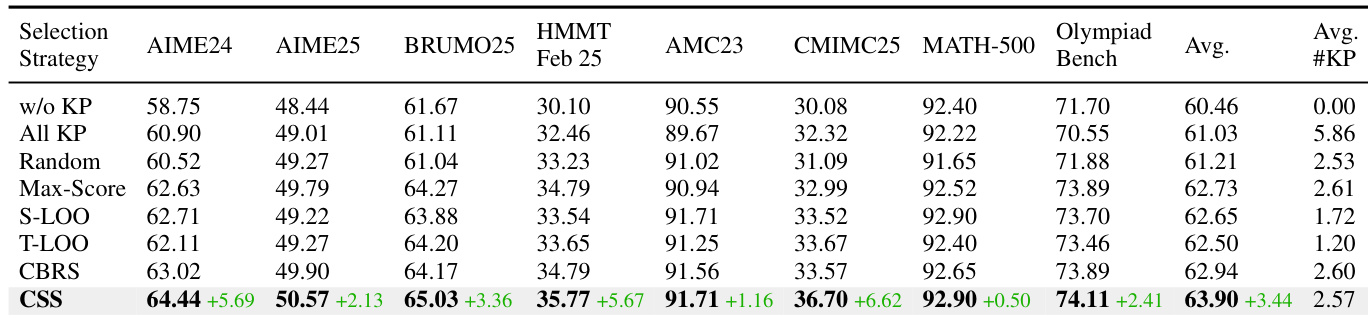
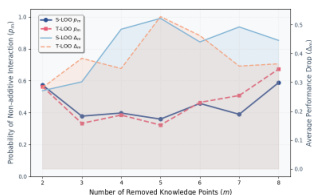
The resulting curated KP set undergoes a problem-wise selection process to determine the optimal subset to use as hints. This involves estimating offline accuracies for various configurations: using no KPs (A∅), using the full set (AK), and performing leave-one-out ablations (A−i). The authors evaluate several selection strategies, including Max-Score, Strict Leave-One-Out (S-LOO), and Tolerant Leave-One-Out (T-LOO), which are formalized as parameterized decision operators. These strategies aim to reduce dependency on KPs while preserving performance. However, a key challenge identified is the pruning interaction paradox, where removing individual KPs may improve performance, but removing them jointly can lead to significant degradation due to cross-hint inconsistency. To address this, the authors introduce Constrained Subset Search (CSS), which first prunes non-degrading and near-optimal KPs, then conducts a global search over the remaining candidate space, achieving a better balance of accuracy and compactness. Additionally, Consensus-Based Robust Selection (CBRS) aggregates results from multiple independent evaluation runs to identify robust, high-performing configurations, further enhancing the selection quality.
Experiment
The experiments evaluate the KnowRL framework through various training configurations, selection strategies, and evaluation protocols to validate its ability to internalize structured reasoning. Results demonstrate that the model significantly improves its underlying policy rather than merely relying on test-time hints, showing particular strength in complex, competition-style reasoning tasks. Furthermore, the CSS selection strategy proves more robust and stable than CBRS, while techniques like entropy annealing effectively accelerate convergence and optimize performance.
The authors compare KnowRL-Nemotron-1.5B against baseline models on multiple reasoning benchmarks, showing that KnowRL achieves superior performance both with and without knowledge point hints. Results indicate that the model's improvements stem from enhanced policy learning rather than reliance on test-time hinting. KnowRL-Nemotron-1.5B outperforms baseline models across all evaluated benchmarks, with notable gains on challenging competition-style datasets. The model achieves strong performance even without knowledge point hints, demonstrating that the training process improves the underlying reasoning capability. Using CSS-selected knowledge points leads to higher average accuracy compared to CBRS, indicating more effective hint construction.
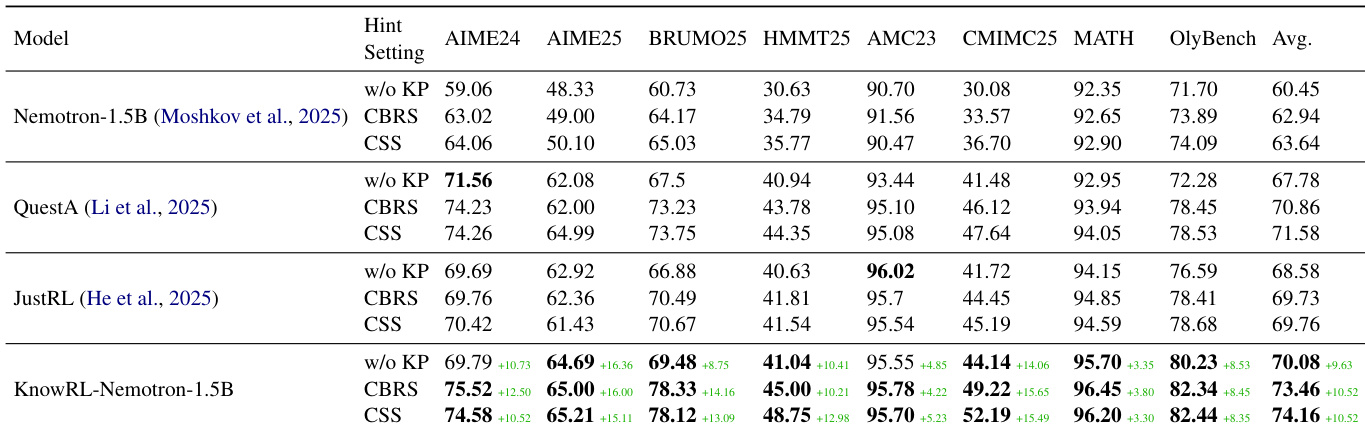
The authors compare KnowRL-Nemotron-1.5B with variants and baselines across multiple reasoning benchmarks. Results show that KnowRL achieves superior performance, especially when using entropy annealing, and outperforms other models without relying on test-time hints. KnowRL-Nemotron-1.5B achieves the highest average performance across all benchmarks compared to other models. The model with entropy annealing outperforms the variant without it, demonstrating improved convergence and final accuracy. KnowRL consistently surpasses baseline models, indicating enhanced reasoning capabilities beyond simple hint injection.

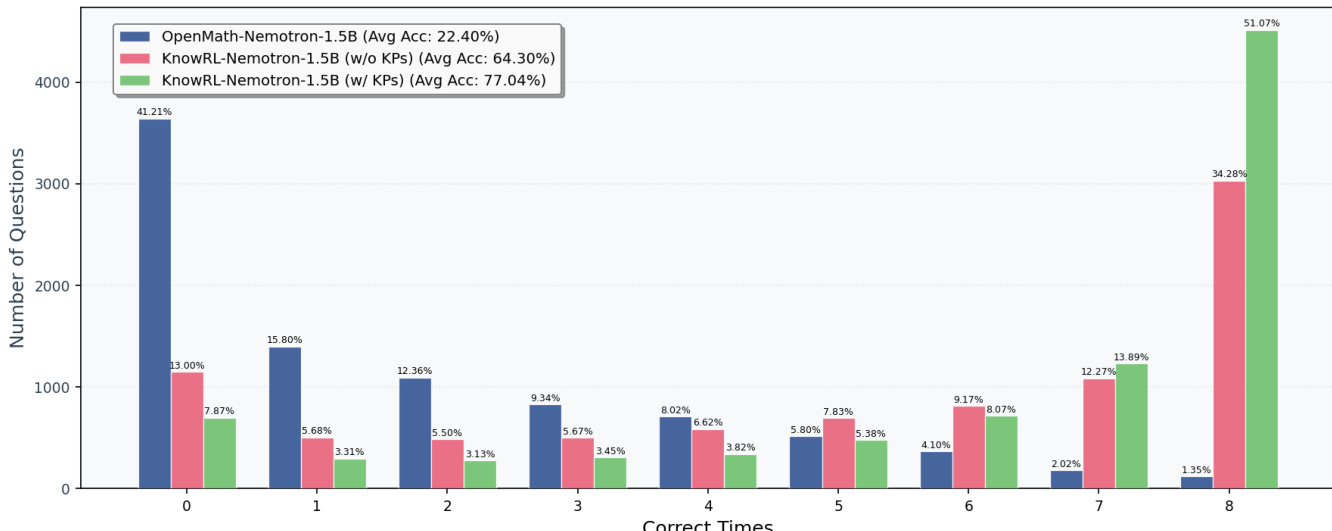
The authors compare the per-query correct count distribution for three models on the training set, showing how performance improves with training and the use of knowledge points. The distribution shifts significantly to the right when moving from the baseline model to the trained models, with the greatest improvement seen when knowledge points are used at inference. The baseline model shows a high frequency of zero correct answers and a low average accuracy. Training with KnowRL improves the distribution, reducing zero-correct queries and increasing the proportion of fully correct answers. Using knowledge points at inference further shifts the distribution toward higher correct counts, with a substantial increase in the highest bucket.
The authors compare different knowledge point selection strategies in a reinforcement learning setup, evaluating their impact on model performance across multiple reasoning benchmarks. Results show that the CSS strategy consistently outperforms other methods, particularly on challenging competition-style datasets, and achieves the highest average accuracy. CSS selection strategy achieves the highest performance across all benchmarks compared to other methods Performance improvements are most pronounced on challenging competition-style reasoning tasks The CSS method demonstrates consistent superiority over CBRS and other baseline selection strategies
The authors analyze the impact of removing knowledge points on model performance during training. Results show that removing knowledge points reduces both the probability of non-additive interaction and average performance, with different removal strategies affecting these metrics in distinct ways. The model's performance degrades as more knowledge points are removed, indicating the importance of these points for effective reasoning. Removing knowledge points decreases the probability of non-additive interaction Performance drops as more knowledge points are removed Different removal strategies lead to varying impacts on model performance
The authors evaluate KnowRL-Nemotron-1.5B against various baselines and configurations across multiple reasoning benchmarks to validate its performance and the effectiveness of its training components. The results demonstrate that the model achieves superior reasoning capabilities through enhanced policy learning rather than a simple reliance on test-time hints, with entropy annealing further improving convergence and accuracy. Additionally, the experiments show that the CSS knowledge point selection strategy is highly effective for challenging tasks and that the inclusion of knowledge points is essential for maintaining high performance and reducing non-additive interactions.