Command Palette
Search for a command to run...
OmniShow: Human-Object Interaction 비디오 생성을 위한 멀티모달 조건의 통합
OmniShow: Human-Object Interaction 비디오 생성을 위한 멀티모달 조건의 통합
초록
본 연구에서는 텍스트, 참조 이미지, 오디오 및 포즈(pose)를 조건으로 하여 고품질의 인간-사물 상호작용 비디오를 합성하는 것을 목표로 하는 Human-Object Interaction Video Generation (HOIVG)을 연구합니다. 이 과업은 이커머스 시연, 숏폼 비디오 제작, 인터랙티브 엔터테인먼트와 같은 실제 응용 분야에서 콘텐츠 제작을 자동화하는 데 있어 중요한 실용적 가치를 지닙니다. 그러나 기존 방식들은 이러한 필수 조건들을 모두 수용하는 데 한계가 있습니다. 이에 본 논문에서는 이 실용적이면서도 도전적인 과업에 맞춤화된 엔드 투 엔드(end-to-end) 프레임워크인 OmniShow를 제안하며, 이는 멀티모달 조건을 조화롭게 통합하여 산업 수준의 성능을 제공할 수 있습니다.제어 가능성(controllability)과 품질 사이의 트레이드오프(trade-off)를 극복하기 위해, 효율적인 이미지 및 포즈 주입을 위한 Unified Channel-wise Conditioning과 정밀한 오디오-비주얼 동기화를 보장하기 위한 Gated Local-Context Attention을 도입합니다. 또한, 데이터 부족 문제를 효과적으로 해결하기 위해, 모델 머징(model merging)을 포함한 다단계 학습 프로세스를 활용하여 이질적인 서브 태스크(sub-task) 데이터셋을 효율적으로 활용할 수 있는 Decoupled-Then-Joint Training 전략을 개발하였습니다. 나아가, 이 분야의 평가 공백을 메우기 위해 HOIVG 전용의 종합적인 벤치마크인 HOIVG-Bench를 구축하였습니다. 광범위한 실험을 통해 OmniShow가 다양한 멀티모달 조건 설정에서 전반적으로 SOTA(state-of-the-art) 성능을 달성함을 입증하였으며, 이는 새롭게 등장하는 HOIVG 과업에 대한 견고한 기준을 제시합니다.
One-sentence Summary
OmniShow is an end-to-end framework for Human-Object Interaction Video Generation that harmonizes text, reference images, audio, and pose conditions via Unified Channel-wise Conditioning and Gated Local-Context Attention to resolve controllability-quality trade-offs, employs a Decoupled-Then-Joint Training strategy to mitigate data scarcity, and establishes the HOIVG-Bench to address the evaluation gap for applications such as e-commerce demonstrations, short video production, and interactive entertainment.
Key Contributions
- The paper introduces OmniShow, an end-to-end framework designed to synthesize human-object interaction videos conditioned on text, reference images, audio, and pose. The framework utilizes Unified Channel-wise Conditioning for efficient injection and Gated Local-Context Attention to ensure precise audio-visual synchronization.
- To address data scarcity, a Decoupled-Then-Joint Training strategy leverages a multi-stage process with model merging to harness heterogeneous sub-task datasets. This approach efficiently utilizes diverse data sources to circumvent data scarcity in HOIVG training.
- The work establishes HOIVG-Bench, a dedicated and comprehensive benchmark specifically designed for HOIVG evaluation. Extensive experiments on this benchmark demonstrate that the method achieves state-of-the-art performance across various multimodal conditioning settings.
Introduction
Real-world applications such as e-commerce demonstrations and interactive entertainment require high-quality Human-Object Interaction Video Generation (HOIVG) conditioned on text, reference images, audio, and pose. However, existing approaches struggle to unify these diverse multimodal inputs. Reference-to-Video methods typically lack audio responsiveness while Audio-to-Video techniques limit reference image usage. Other works often overlook pose conditions or depend on rigid inputs such as masks. Data scarcity and the absence of dedicated benchmarks further hinder research. The authors propose OmniShow, an end-to-end framework designed to harmonize these multimodal conditions. They leverage Unified Channel-wise Conditioning for efficient image and pose injection alongside Gated Local-Context Attention for precise audio-visual synchronization. To address data scarcity, they develop a Decoupled-Then-Joint Training strategy and establish HOIVG-Bench for comprehensive evaluation.
Dataset

The authors develop a comprehensive data strategy comprising a large-scale training collection and a specialized evaluation benchmark to support Human-Object Interaction Video Generation (HOIVG).
Training Data Collection
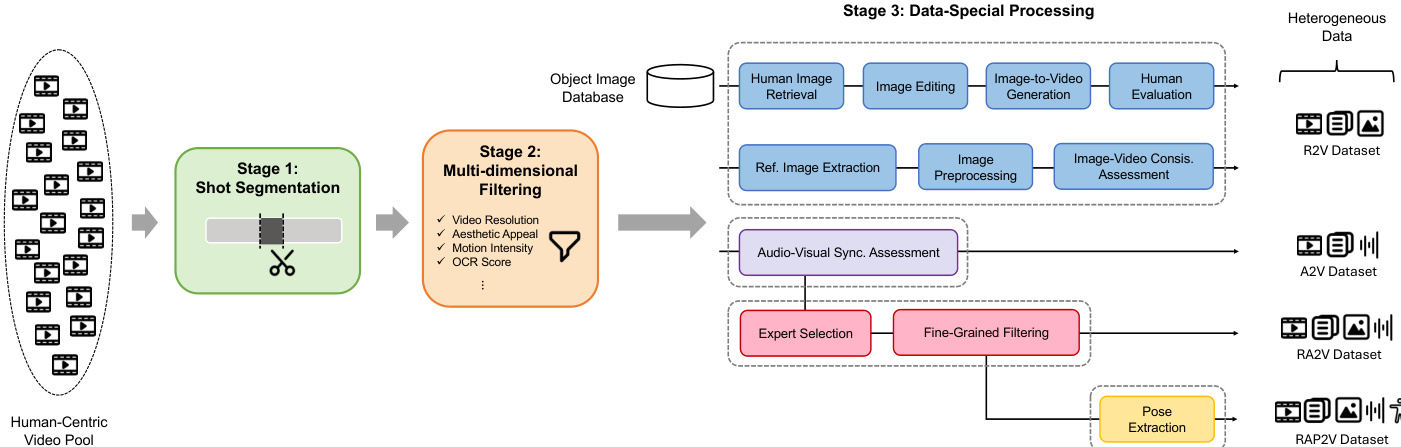
- Source and Scale: The dataset originates from a massive in-house human-centric video pool, resulting in approximately 1 million clips totaling around 3500 hours.
- Preprocessing Pipeline: Videos undergo shot segmentation to isolate continuous narratives, followed by multi-dimensional filtering based on resolution, aesthetic appeal, motion intensity, and OCR scores to exclude watermarks or excessive text.
- Heterogeneous Subsets: The filtered data is processed into four specific subsets for different training objectives:
- R2V (Reference-to-Video): Created using internal object databases combined with human images via editing or real video references enhanced with super-resolution. Human evaluation filters out distortions or artifacts.
- A2V (Audio-to-Video): Focuses on audio-driven generation where clips are selected based on strict audio-visual synchronization alignment.
- RA2V (Reference+Audio-to-Video): A high-quality joint training set subjected to expert selection and fine-grained filtering for visual and semantic consistency.
- RAP2V (Reference+Audio+Pose-to-Video): Derived from the RA2V subset, this data includes per-frame human pose skeletons extracted via DWPose for precise motion control during final fine-tuning.
- Metadata: Video captioning is integrated to provide descriptions of human subjects, objects, actions, environments, and interaction details.
HOIVG-Bench Evaluation Suite
- Composition: The benchmark consists of 135 curated samples featuring text captions, human and object reference images, semantically aligned audio, and coherent pose sequences.
- Construction Details:
- Video Selection: Raw videos exceed 4 seconds and feature clear human-object interactions with diverse human attributes and object categories.
- Image Generation: Reference images for humans and objects are generated using Nano Banana to modify textures and ensure privacy compliance through identity de-identification.
- Audio and Pose: Speech scripts are generated by GPT-4o and synthesized via ElevenLabs to match human attributes, while poses are extracted using DWPose.
- Usage: All evaluation metrics and analyses are standardized to 5-second video clips at 720p resolution in portrait mode to ensure fair comparison with baseline methods.
Method
The OmniShow framework is designed to generate high-quality videos by conditioning on a flexible combination of multimodal inputs. As illustrated in the overview of unified tasks and applications, the system supports diverse generation scenarios including Reference-to-Video (R2V), Pose-to-Video (RP2V), and Audio-to-Video (RA2V), alongside broader applications like audio-driven avatars and object swapping.

Refer to the framework diagram for the detailed architecture and training pipeline. The core architecture is built upon the Waver 1.0 backbone, a 12B Multimodal Diffusion Transformer (MMDiT) that utilizes Flow Matching for training. The objective is to minimize the discrepancy between the predicted velocity field vθ and the ground-truth flow velocity u. The framework employs a Unified Channel-wise Conditioning strategy to inject reference images and pose cues without disrupting generative priors. Instead of introducing hybrid tokens that increase learning costs, the authors expand the input capacity by augmenting noisy video tokens with pseudo-frame tokens. Reference image tokens and pose video tokens are injected via channel concatenation. To ensure the model retains semantic details, a Reference Reconstruction Loss is applied to these pseudo-frames, compelling the model to perceive and preserve high-fidelity visual consistency.
For audio synchronization, the framework integrates a Gated Local-Context Attention module. Raw audio signals are processed through Wav2Vec 2.0 to extract semantic and rhythmic features. These features undergo frame alignment and window aggregation to capture temporal context. The packed audio features interact with video tokens through a masked attention mechanism, ensuring that each latent frame attends only to its corresponding audio segment. To stabilize the training process, an Adaptive Gating mechanism is introduced. A learnable gating vector modulates the audio injection, starting near zero to prevent disruption of pretrained feature distributions during early training. This efficient design allows the model to achieve precise audio-visual alignment while keeping the parameter increase minimal.
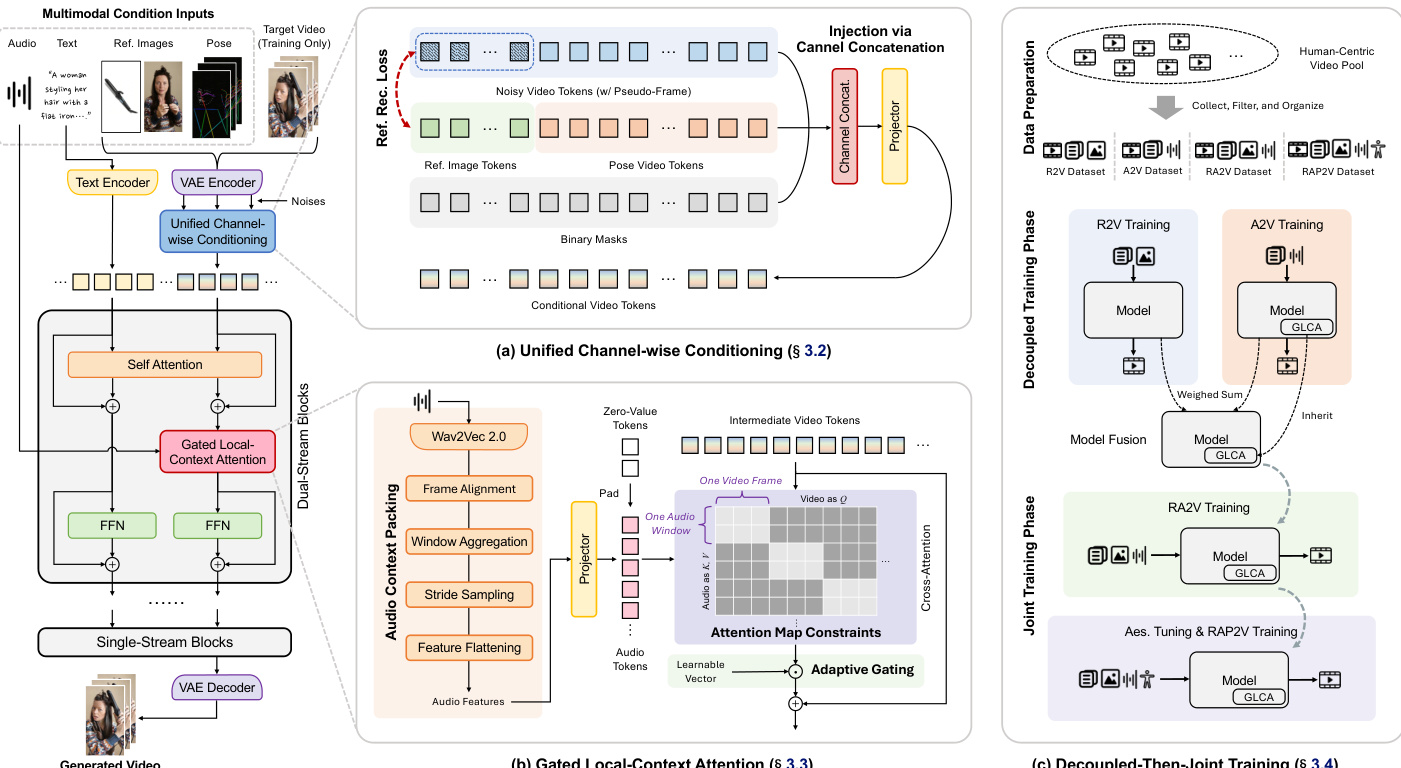
The training process follows a Decoupled-Then-Joint strategy to effectively harness heterogeneous datasets. As shown in the data preparation pipeline, the authors first collect a massive human-centric video pool and apply multi-dimensional filtering to ensure quality. They then curate specific subsets for R2V, A2V, and RA2V tasks. Initially, specialized R2V and A2V models are trained on their respective datasets. These models are then merged via linear weight interpolation, prioritizing audio synchronization weights due to their sensitivity. The resulting model exhibits emergent capabilities for combined tasks and undergoes joint fine-tuning on the full RA2V dataset, followed by final fine-tuning with pose conditions to enhance naturalness and aesthetics.
Experiment
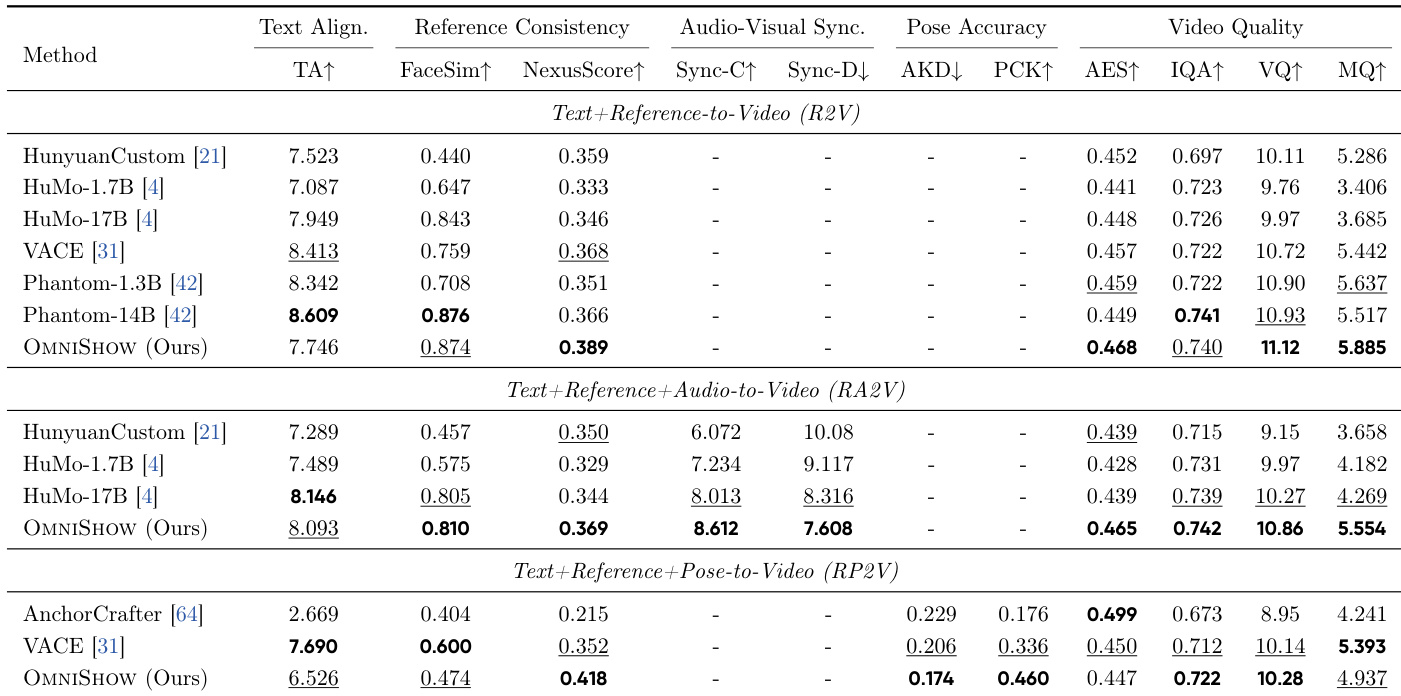
The evaluation compares OMNISHOW against leading open-source methods across diverse multimodal conditioning settings to validate its unified framework capabilities. Quantitative and qualitative results indicate that the model achieves top-tier performance in reference preservation and audio-visual synchronization while maintaining superior parameter efficiency. Ablation studies further verify that architectural components like gated local-context attention and decoupled-then-joint training are essential for balancing consistency with coherence. Finally, human evaluations and comparisons with cascaded baselines demonstrate the model's robustness in complex scenarios and its preference for overall visual quality.
The authors demonstrate that OMNI SHOW achieves state-of-the-art or highly competitive performance across diverse multimodal conditioning settings, including reference, audio, and pose inputs. The model effectively balances reference preservation with audio-visual synchronization, often outperforming specialized baselines while maintaining superior parameter efficiency. Furthermore, it is the only framework capable of handling the full spectrum of multimodal inputs simultaneously, showing distinct advantages over cascaded approaches in complex generation tasks. OMNI SHOW matches specialized methods in reference preservation for R2V while leading in audio-visual synchronization for RA2V tasks. Human evaluation studies indicate a strong preference for OMNI SHOW results over baselines due to smoother temporal dynamics and richer visual details. In the complex RAP2V setting, the unified end-to-end approach yields significantly better synchronization and video quality compared to cascaded baselines.
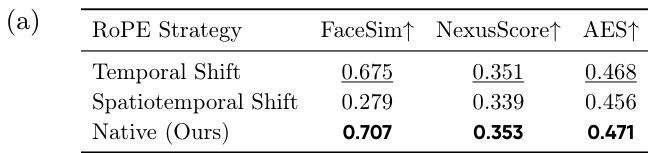
The authors compare different Rotary Positional Embedding strategies for integrating reference frames into the video generation process. Their proposed native strategy, which treats pseudo-frames and video frames as a continuous sequence, consistently outperforms alternative approaches involving temporal or spatiotemporal shifts across all measured metrics. This outcome highlights the importance of maintaining temporal continuity to align with the model's pre-training distribution. The native RoPE strategy achieves the best performance in face similarity, nexus score, and audio-visual synchronization metrics. Aligning reference frames with the standard continuous video sequence allows for more effective utilization of reference context. Artificial positional shifts, such as temporal or spatiotemporal shifts, lead to reduced performance compared to the native approach.
The authors validate three key components through ablation studies: unified channel-wise conditioning, gated local-context attention, and a decoupled-then-joint training strategy. Results show that the full model consistently outperforms variants lacking these components across metrics for reference consistency, synchronization, and video quality. Specifically, the proposed training paradigm achieves a better balance between reference preservation and audio-visual synchronization compared to single-stage or naive multi-stage baselines. Unified channel-wise conditioning yields superior reference consistency and video quality compared to token concatenation. Gated local-context attention is crucial for capturing temporal coherence and precise lip synchronization. The decoupled-then-joint training strategy outperforms single-stage and standard multi-stage approaches in balancing consistency and synchronization.

The authors evaluate their end-to-end OMNIShow framework against a cascaded baseline constructed from existing methods for the RAP2V task. The results demonstrate that the unified approach achieves superior performance across all metrics, including synchronization, pose accuracy, and video quality. This comparison highlights the advantages of simultaneous modeling over sequential synthesis pipelines. OMNIShow outperforms the cascaded baseline across all evaluation metrics. The proposed method achieves better audio-visual synchronization and pose adherence. Video and motion quality scores are substantially higher for the end-to-end framework.

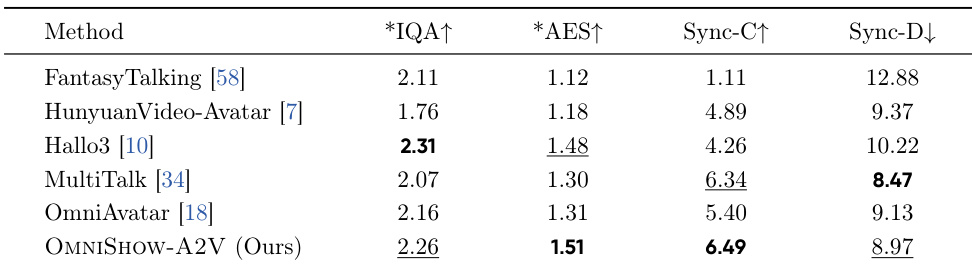
The authors evaluate their OMNIShow-A2V model on the EMTD benchmark against leading open-source methods for audio-driven avatar generation. Results show that their unified framework achieves state-of-the-art or highly competitive performance across diverse metrics, particularly excelling in synchronization tasks. The proposed method achieves the highest scores in audio-visual synchronization consistency and overall synchronization metrics. Image quality assessment results are highly competitive, placing second among all compared methods. The model demonstrates strong synchronization capabilities, outperforming specialized baselines in key consistency areas.
The authors evaluate the OMNI SHOW framework across diverse multimodal conditioning settings and benchmarks, comparing it against specialized baselines and cascaded approaches to validate its unified architecture. Ablation studies confirm the necessity of specific components, such as native Rotary Positional Embedding and decoupled-then-joint training, for effectively balancing reference preservation with audio-visual synchronization. Overall, the end-to-end approach demonstrates superior performance in synchronization and video quality compared to sequential pipelines, with human evaluations indicating a strong preference for its smoother temporal dynamics.