Command Palette
Search for a command to run...
ClawGUI: GUI Agent의 Training, Evaluating 및 Deploying을 위한 Unified Framework
ClawGUI: GUI Agent의 Training, Evaluating 및 Deploying을 위한 Unified Framework
Fei Tang Zhiqiong Lu Boxuan Zhang Weiming Lu Jun Xiao Yueting Zhuang Yongliang Shen
초록
GUI agent는 프로그래밍 방식의 API 대신 시각적 인터페이스를 통해 애플리케이션을 구동하며, 탭(tap), 스와이프(swipe), 키스트로크(keystroke)를 통해 임의의 소프트웨어와 상호작용합니다. 이를 통해 CLI 기반 agent가 도달할 수 없는 광범위한(long tail) 애플리케이션 영역에 접근할 수 있습니다. 그러나 이 분야의 발전은 모델링 역량의 문제라기보다, 일관된 풀스택 인프라의 부재로 인해 병목 현상을 겪고 있습니다. 구체적으로는 온라인 RL training이 환경의 불안정성과 폐쇄적인 pipeline 문제로 어려움을 겪고 있으며, 평가 프로토콜은 연구마다 일관성 없이 변하며, 학습된 agent가 실제 기기에서 실제 사용자에게 도달하는 경우도 드뭅니다.본 논문에서는 이러한 세 가지 격차를 단일 시스템 내에서 해결하는 오픈소스 프레임워크인 ClawGUI를 선보입니다. ClawGUI-RL은 병렬 가상 환경과 실제 물리적 기기를 모두 검증된 방식으로 지원하는 최초의 오픈소스 GUI agent RL 인프라를 제공하며, 조밀한 step-level supervision을 위해 GiGPO를 Process Reward Model과 통합하였습니다. ClawGUI-Eval은 6개의 benchmark와 11개 이상의 모델에 대해 완전히 표준화된 evaluation pipeline을 적용하여, 공식 baseline 대비 95.8%의 재현율을 달성했습니다. ClawGUI-Agent는 hybrid CLI-GUI 제어 및 지속적인 개인화 메모리(persistent personalized memory) 기능을 갖춘 12개 이상의 채팅 플랫폼을 통해 학습된 agent를 Android, HarmonyOS, iOS로 확장합니다. 이 pipeline 내에서 end-to-end로 학습된 ClawGUI-2B는 MobileWorld GUI-Only 환경에서 17.1%의 Success Rate를 기록하며, 동일 규모의 MAI-UI-2B baseline 대비 6.0% 높은 성능을 보였습니다.
One-sentence Summary
ClawGUI is an open-source unified framework that addresses infrastructure gaps in GUI agent development by integrating ClawGUI-RL, which utilizes GiGPO with a Process Reward Model for training on both virtual and physical devices, ClawGUI-Eval, which provides a standardized pipeline across 6 benchmarks with 95.8% reproduction accuracy, and ClawGUI-Agent, which enables cross-platform deployment on Android, HarmonyOS, and iOS.
Key Contributions
- The paper introduces ClawGUI-RL, an open-source reinforcement learning infrastructure that supports both parallel virtual environments and real physical devices by integrating GiGPO with a Process Reward Model for dense step-level supervision.
- The work establishes ClawGUI-Eval, a standardized evaluation pipeline covering 6 benchmarks and over 11 models that achieves a 95.8% reproduction rate against official baselines.
- The authors present ClawGUI-Agent, a deployment system that enables natural-language automation across Android, HarmonyOS, and iOS via 12+ chat platforms using hybrid CLI-GUI control and persistent personalized memory.
Introduction
GUI agents are essential for digital automation because they can interact with any application through visual interfaces rather than relying on limited programmatic APIs. However, progress in this field is currently bottlenecked by a lack of cohesive full-stack infrastructure. Existing research suffers from unstable online reinforcement learning (RL) environments, evaluation protocols that drift across different studies, and a significant gap between simulated training and real-world device deployment.
The authors leverage a unified open-source framework called ClawGUI to bridge these gaps across the entire agent lifecycle. They introduce ClawGUI-RL to provide scalable training support for both virtual emulators and physical devices using dense step-level rewards. To ensure scientific rigor, they contribute ClawGUI-Eval, a standardized pipeline that achieves high reproduction rates across multiple benchmarks. Finally, they present ClawGUI-Agent, a deployment system that enables agents to operate on Android, HarmonyOS, and iOS using a hybrid CLI and GUI control method.
Dataset

The authors introduce ClawGUI-Eval, a comprehensive evaluation framework designed to assess GUI grounding and navigation capabilities. The dataset and its implementation details include:
- Benchmark Composition: The evaluation covers six distinct benchmarks to ensure diverse scenario coverage: ScreenSpot-Pro, ScreenSpot-V2, UI-Vision, MMBench-GUI, OSWorld-G, and AndroidControl.
- Model Coverage: The framework is designed to evaluate over 11 different models, including specialized GUI agents like UI-TARS, MAI-UI, and StepGUI, as well as large scale vision language models such as Qwen2.5-VL and Gemini.
- Reproducibility: To support community research, the authors provide the full evaluation code and release all inference results publicly.
Method
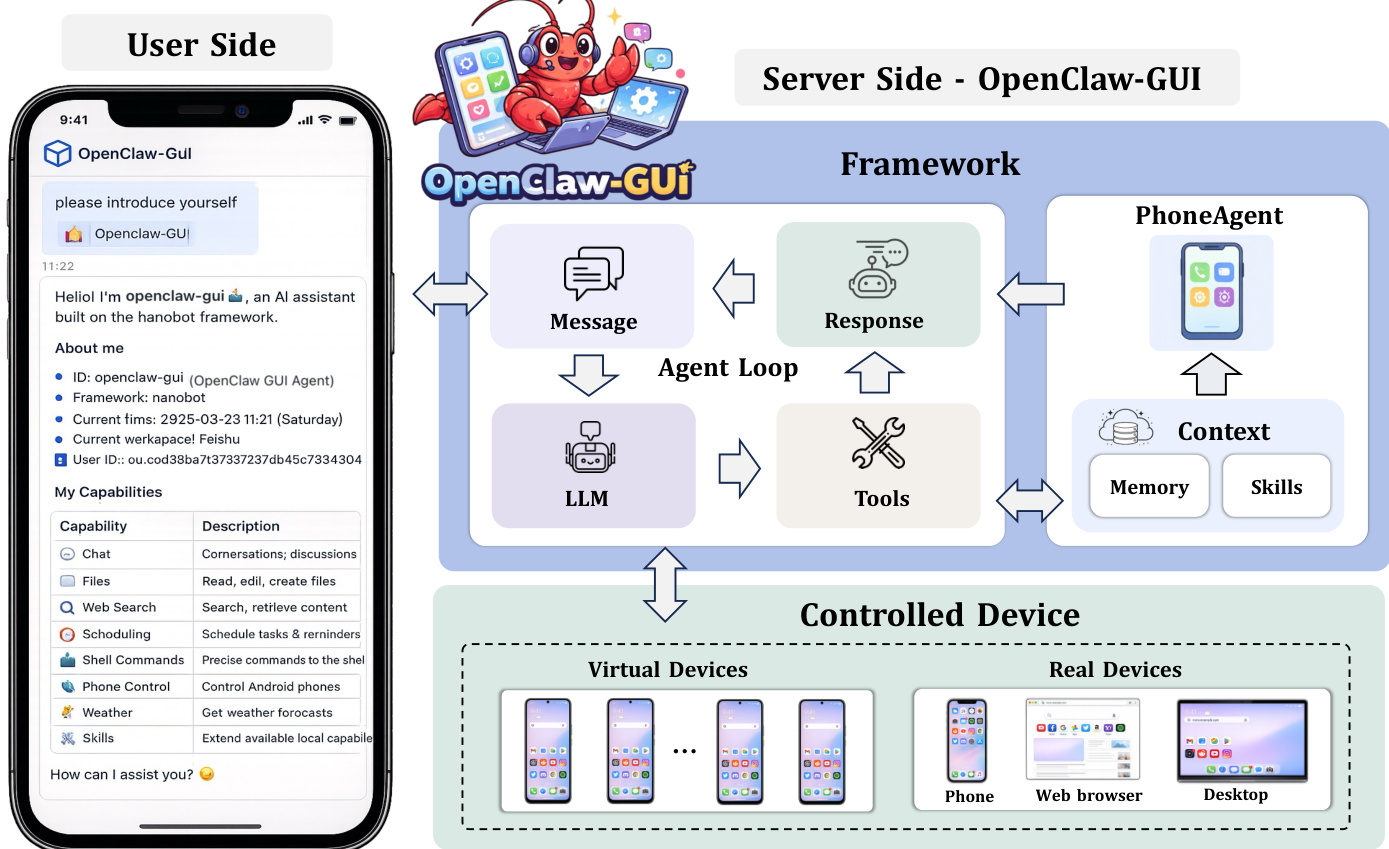
The ClawGUI framework is structured around three core components—ClawGUI-RL, ClawGUI-Eval, and ClawGUI-Agent—that collectively support the full lifecycle of GUI agent development, from training and evaluation to deployment and interaction. The overall architecture is designed to enable scalable, reproducible, and real-world capable GUI agents through modular and interoperable systems.
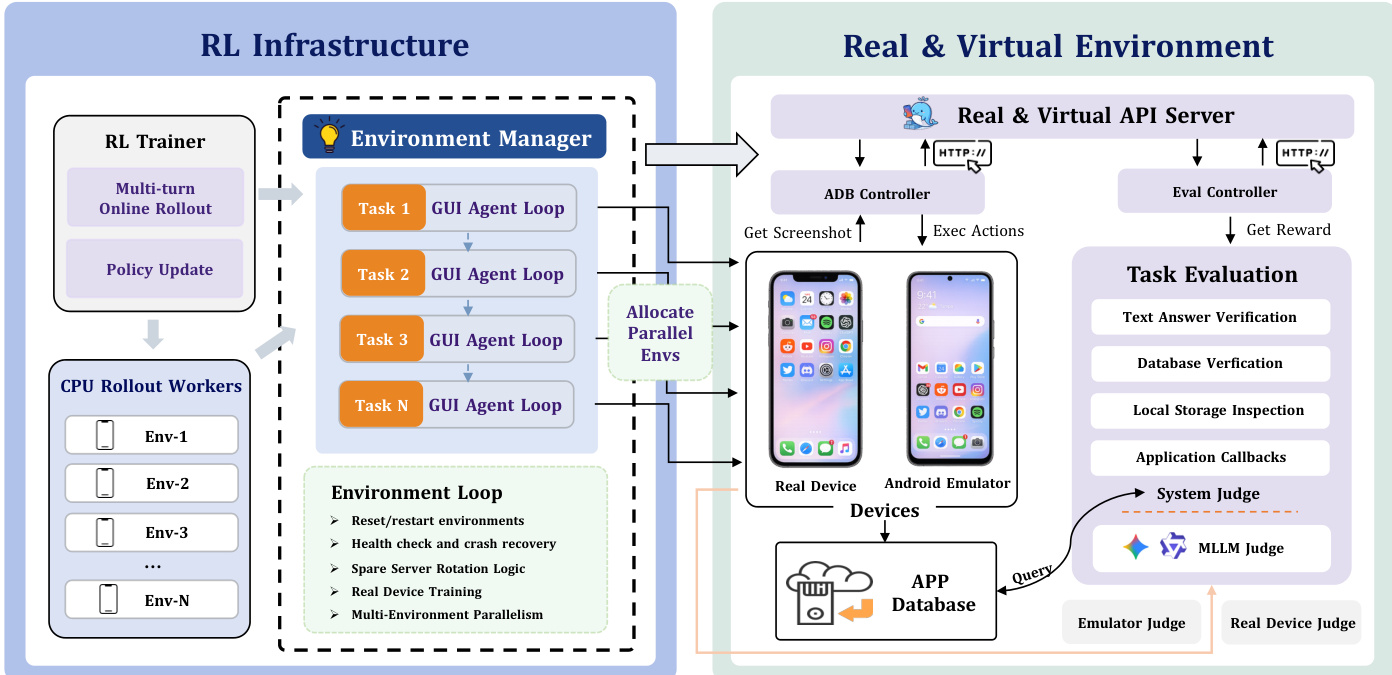
ClawGUI-RL serves as the training backbone, built upon a robust reinforcement learning infrastructure that supports both virtual and physical devices. At its core is the Environment Manager, which abstracts device backends behind a unified interface, enabling seamless integration of virtual environments and real devices within the same training loop. As shown in the framework diagram, the system leverages Docker-based Android emulators for virtual environments, each exposed via a backend URL for interaction with training workers. Each environment follows a four-stage lifecycle: task reset to ensure a clean state at the start of each episode, task evaluation using system-level root access for reliable verification, spare server rotation to maintain stability during long training runs by automatically replacing unhealthy containers, and periodic teardown to prevent state drift. For real-device training, the system supports physical Android devices or cloud phones through the same interface, though it requires manually authored tasks and relies on an MLLM-as-judge for outcome verification due to the lack of system-level access.
The reward design in ClawGUI-RL combines a binary outcome reward with a dense step-level reward to address the sparsity inherent in long-horizon GUI tasks. The binary reward assigns a value of 1 for task success and 0 for failure, while a Process Reward Model (PRM) provides per-step feedback by assessing whether each action meaningfully advances task completion. This dense reward signal is combined with the outcome reward to form the total reward R=Routcome+Rstep, enabling more effective learning by providing guidance at each step.
The RL Trainer module builds on existing frameworks verl and verl-agent, supporting a range of reinforcement learning algorithms such as Reinforce++, PPO, GSPO, GRPO, and GiGPO. GRPO estimates advantages by normalizing returns within task-specific groups of rollouts, but its uniform episode-level advantage assignment is too coarse for long-horizon tasks. To address this, ClawGUI-RL integrates GiGPO, which employs a two-level hierarchical advantage estimation. At the episode level, it retains macro relative advantages across complete trajectories, preserving global quality signals. At the step level, it clusters steps encountering the same intermediate environment state across different rollouts into sub-groups and estimates micro relative advantages within each group via discounted return normalization. This approach enables fine-grained credit assignment without requiring a learned value network or additional rollouts.
ClawGUI-Eval provides a standardized and reproducible evaluation pipeline, decomposing the process into three decoupled stages: Infer, Judge, and Metric. The inference stage generates raw predictions using either local GPU inference via transformers or remote API inference via OpenAI-compatible endpoints, with multi-GPU parallel inference managed through Python multiprocessing. The judge stage parses raw outputs and evaluates them against ground truth using benchmark-specific judges, such as a point-in-box judge for standard GUI grounding or a polygon and refusal-aware judge for OSWorld-G. The metric stage aggregates per-sample correctness labels into final accuracy scores with detailed breakdowns by platform, UI element type, and task category. This modular design allows any stage to be rerun independently, facilitating efficient experimentation and validation.
ClawGUI-Agent enables real-device deployment and human interaction through a message-driven agent loop. It supports two deployment modes: remote control, where users issue commands from 12+ chat platforms to control a target device remotely, and local control, where instructions are sent directly from a chat application on the same device, enabling direct local execution without external hardware or cloud relay. The agent incorporates a persistent personalized memory system that automatically extracts structured facts from interactions—such as contact names, frequently used applications, and user habits—and stores them as vector embeddings. During task execution, the top-k most semantically similar memories are retrieved and injected into the system context, allowing the agent to adapt to individual user patterns over time. Additionally, ClawGUI-Eval is exposed as a built-in tool skill, enabling users to trigger a complete benchmark evaluation pipeline with a single natural-language command.
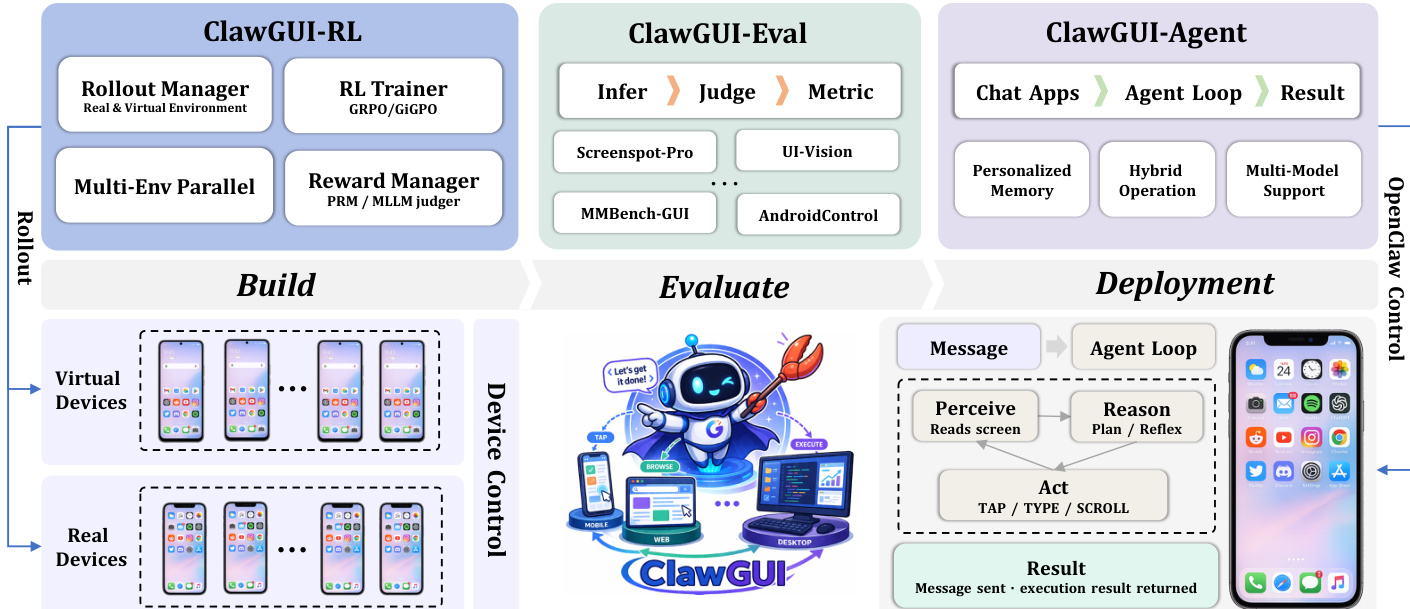
The framework’s design emphasizes modularity and extensibility, with each component contributing to a cohesive system for developing, evaluating, and deploying GUI agents. The integration of diverse reward signals, advanced advantage estimation techniques, and a flexible evaluation pipeline enables robust training and reliable performance across a wide range of GUI tasks.
Experiment
The ClawGUI framework is evaluated through a series of training, reward design, and benchmarking experiments to validate its ability to close existing gaps in the GUI agent ecosystem. Training results demonstrate that a well-engineered RL infrastructure allows small models to outperform significantly larger untrained models, while ablation studies confirm that dense, step-level credit assignment provides a much richer learning signal than coarse episode-level rewards. Furthermore, the standardized evaluation pipeline achieves a high reproduction rate across multiple benchmarks, proving that current discrepancies in GUI research are primarily due to inconsistent evaluation configurations rather than fundamental model limitations.
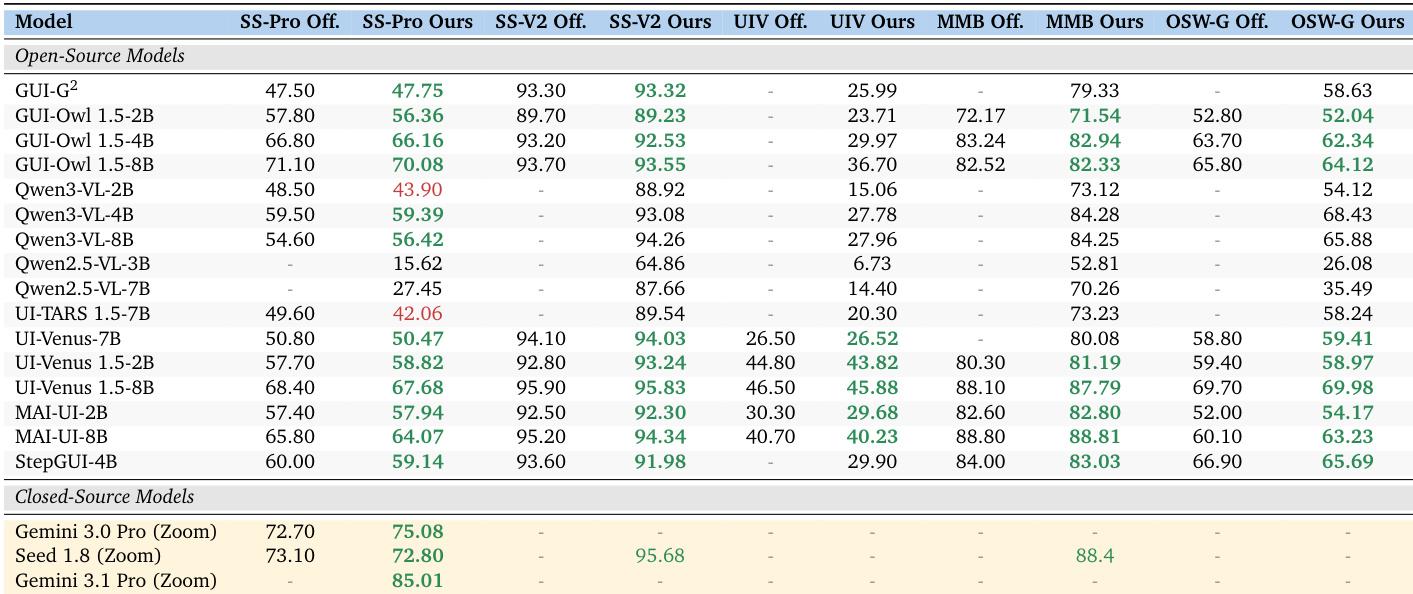
The authors present a standardized evaluation framework that achieves high reproducibility across multiple benchmarks and models. Results show that consistent evaluation protocols lead to reliable comparisons, with most published results successfully reproduced using the proposed pipeline. A standardized evaluation pipeline achieves 95.8% reproduction rate across benchmarks and models Open-source models show high reproducibility, while some failures are linked to undisclosed evaluation configurations Closed-source models are successfully reproduced using a two-stage crop-then-ground strategy
The authors compare two reward types in GUI agent training, showing that dense step-level rewards lead to higher success rates than binary episode-level rewards. The results demonstrate that fine-grained credit assignment improves learning in long-horizon GUI tasks. Dense step-level rewards outperform binary episode-level rewards Fine-grained credit assignment improves success rates in GUI tasks The improvement is consistent across the evaluated methods

The authors compare the success rates of various models on the MobileWorld GUI-Only benchmark, highlighting the performance of their proposed ClawGUI-2B model. Results show that ClawGUI-2B achieves a competitive success rate, outperforming several larger models and demonstrating the effectiveness of their training infrastructure and reward design. ClawGUI-2B achieves a success rate that surpasses several larger models on the MobileWorld GUI-Only benchmark. The performance of ClawGUI-2B is competitive with other end-to-end models, despite being trained within an open-source framework. The results indicate that effective training infrastructure and reward design can lead to strong performance even with modest model scale.
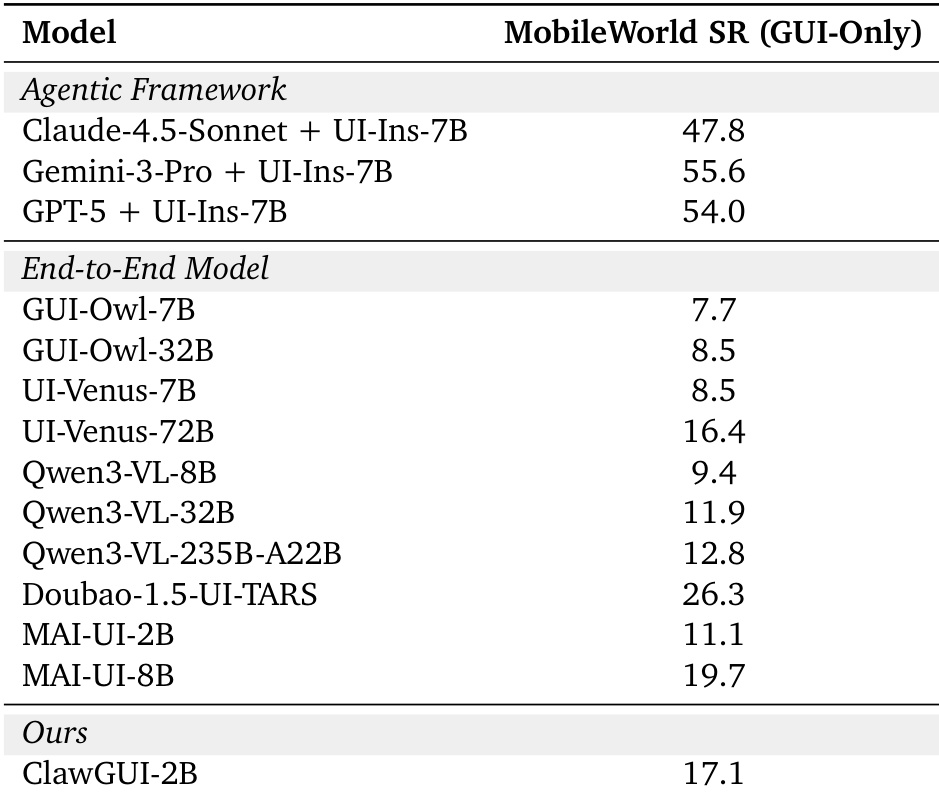
The authors introduce a standardized evaluation framework to validate reproducibility across various benchmarks and models, demonstrating that consistent protocols yield reliable comparisons. They further investigate reward mechanisms and model performance, showing that dense step-level rewards provide superior credit assignment for long-horizon tasks compared to binary rewards. Finally, the evaluation of the ClawGUI-2B model on the MobileWorld benchmark confirms that effective training infrastructure and reward design can enable smaller models to achieve competitive performance against larger counterparts.