Command Palette
Search for a command to run...
Transformer에서의 Attention Sink: 활용, 해석 및 완화에 관한 서베이 (A Survey on Utilization, Interpretation, and Mitigation)
Transformer에서의 Attention Sink: 활용, 해석 및 완화에 관한 서베이 (A Survey on Utilization, Interpretation, and Mitigation)
초록
현대 머신러닝의 근간이 되는 아키텍처인 Transformer는 다양한 AI 분야에서 놀라운 발전을 이끌어왔습니다. 이러한 혁신적인 영향력에도 불구하고, 여러 Transformer 모델에서 지속적으로 발생하는 과제 중 하나는 Attention Sink (AS) 현상입니다. AS는 정보량이 거의 없는 특정 토큰의 소수 부분집합에 불균형적으로 많은 Attention이 집중되는 현상을 의미합니다. AS는 모델의 해석 가능성(interpretability)을 어렵게 만들고, training 및 inference 역학에 상당한 영향을 미치며, hallucination과 같은 문제를 악화시킵니다.최근 몇 년 동안 AS를 이해하고 활용하기 위한 상당한 연구가 이루어져 왔습니다. 그러나 AS 관련 연구를 체계적으로 통합하고 향후 발전을 위한 가이드를 제공하는 포괄적인 survey는 여전히 부족한 실정입니다. 이러한 공백을 메우기 위해, 본 논문은 현재의 연구 지형을 정의하는 세 가지 핵심 차원인 '기초적 활용(Fundamental Utilization)', '메커니즘적 해석(Mechanistic Interpretation)', 그리고 '전략적 완화(Strategic Mitigation)'를 중심으로 구성된 최초의 AS survey를 제시합니다.본 연구는 핵심 개념을 명확히 하고 연구자들이 이 분야의 진화 과정과 트렌드를 파악할 수 있도록 안내함으로써 중추적인 기여를 하고자 합니다. 우리는 본 survey가 연구자와 실무자들이 현재의 Transformer 패러다임 내에서 AS를 효과적으로 관리할 수 있도록 돕는 결정적인 리소스가 되는 동시에, 차세대 Transformer를 위한 혁신적인 발전을 고취하는 계기가 되기를 기대합니다. 본 연구의 논문 목록은 https://github.com/ZunhaiSu/Awesome-Attention-Sink 에서 확인하실 수 있습니다.
One-sentence Summary
This first comprehensive survey on Attention Sink in Transformers systematically categorizes research into fundamental utilization, mechanistic interpretation, and strategic mitigation to clarify key concepts and provide a framework for managing uninformative token focus to improve training, inference, and interpretability.
Key Contributions
- This work presents the first comprehensive survey on Attention Sink (AS) in Transformer architectures by systematically synthesizing over 180 studies. The review is structured around three key dimensions: Fundamental Utilization, Mechanistic Interpretation, and Strategic Mitigation.
- The paper provides a detailed analysis of how AS influences training dynamics, model interpretability, and inference efficiency across various architectures. It clarifies key concepts and examines how empirical utilization strategies, mechanistic studies, and mitigation techniques can be leveraged to improve model performance and robustness.
- The survey establishes a foundational framework for understanding AS and identifies critical future research directions. These include the development of standardized benchmarks for mitigation, the exploration of cross-architecture and cross-modal transfer, and the investigation of synergistic integration between multiple AS handling techniques.
Introduction
Transformers serve as the foundational architecture for modern AI, yet they frequently exhibit Attention Sink (AS), a phenomenon where disproportionate attention concentrates on a small subset of uninformative tokens. This behavior complicates model interpretability, destabilizes training and inference, and contributes to issues like hallucinations and quantization errors. While recent studies have explored various ways to exploit or reduce AS, the existing literature remains fragmented, leaving researchers without a unified reference to guide development. The authors leverage a comprehensive review of over 180 studies to present the first systematic survey of the field. They organize the research into a novel taxonomy based on three dimensions: fundamental utilization, mechanistic interpretation, and strategic mitigation.
Method
The foundational architecture for modern large language models (LLMs) is derived from the Transformer, which operates on an encoder-decoder framework. As shown in the figure below, a standard Transformer block consists of two primary components: a multi-head self-attention (MHSA) module and a position-wise feed-forward network (FFN). The MHSA mechanism enables the model to capture long-range global dependencies without the inductive bias of sequential processing. For an input sequence X∈RN×D, queries Q, keys K, and values V are obtained via linear projections: Q=XWQ, K=XWK, V=XWV, where WQ,WK,WV∈RD×dk. Attention is computed as Attention(Q,K,V)=Softmax(dkQKT)V. The FFN is applied to each position independently and is defined as FFN(x)=σ(xW1+b1)W2+b2. To stabilize training and mitigate the vanishing gradient problem, each sub-layer incorporates a residual connection followed by layer normalization (LayerNorm): Xout=LayerNorm(X+SubLayer(X)).
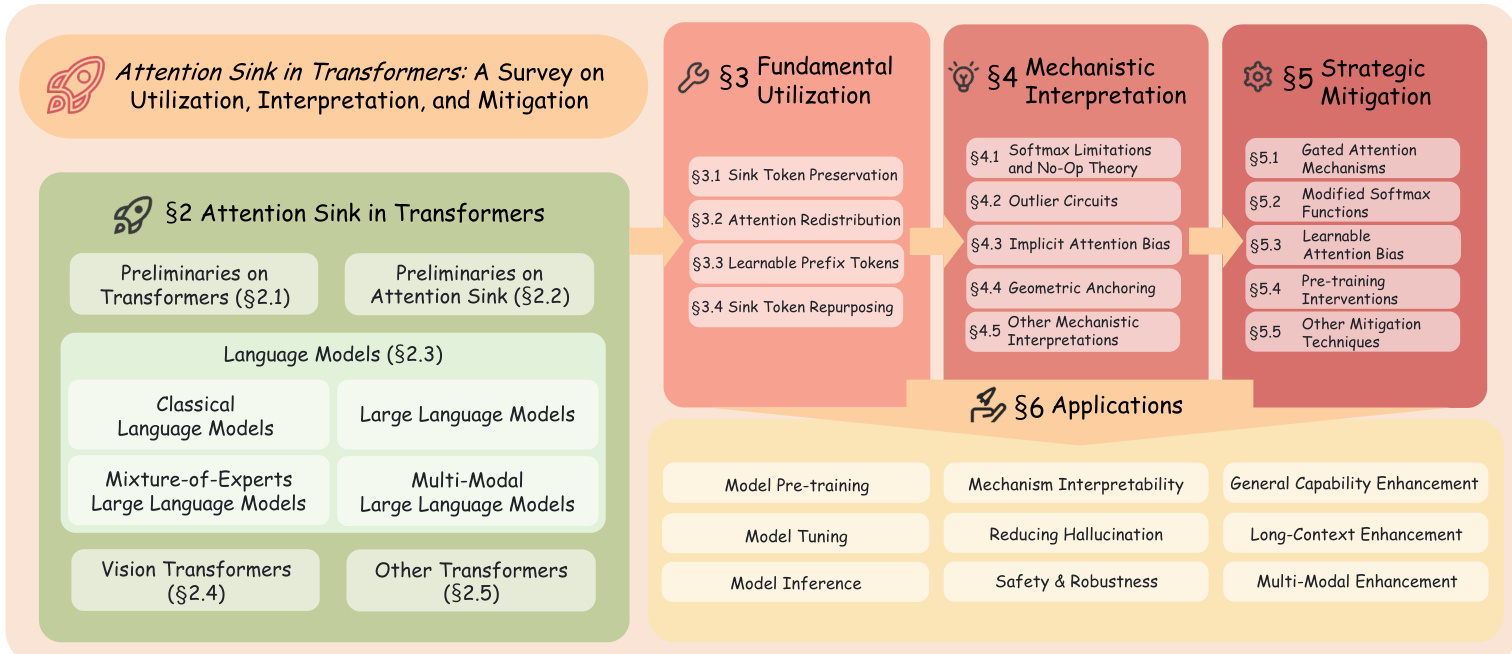
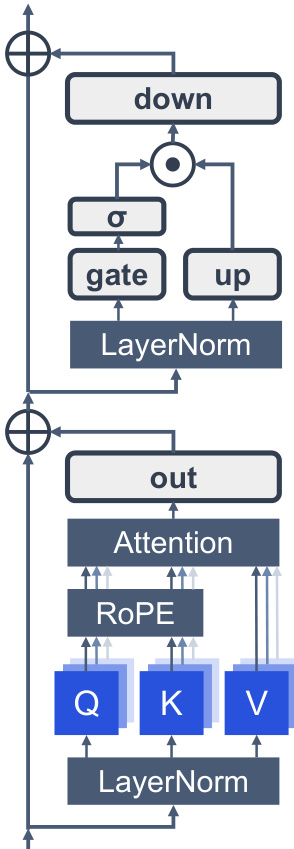
Modern LLMs are a specialized adaptation of the Transformer, fundamentally rooted in the decoder-only configuration. The structural layout of these models is illustrated in Figure 7. A defining constraint inherited from the decoder-only architecture is the causal masking mechanism, which ensures that each query vector qi at position i can only attend to preceding key vectors kj where j≤i. Formally, the attention pattern is defined as Attention(Q,K,V)=softmax(dkQK⊤+M)V, where M is the causal mask with Mij=−∞ for j>i and 0 otherwise. In this setting, only the initial tokens are visible to the entire sequence, making them the most stable candidates for attention offloading. Beyond causal masking, contemporary LLMs incorporate a suite of architectural refinements that collectively enhance training stability, model expressivity, and inference efficiency. For normalization, pre-normalization with Root Mean Square Layer Normalization (RMSNorm) has largely replaced the original post-LN design, mitigating gradient variance and enabling more stable training at scale. The feed-forward network has been upgraded from the original two-layer MLP to Gated Linear Units (GLU), with SwiGLU emerging as the predominant variant due to its superior trade-off between expressivity and computational cost. For positional encoding, Rotary Positional Embeddings (RoPE) encode relative position information through rotation matrices, offering improved length extrapolation capabilities compared to absolute or learnable positional embeddings.
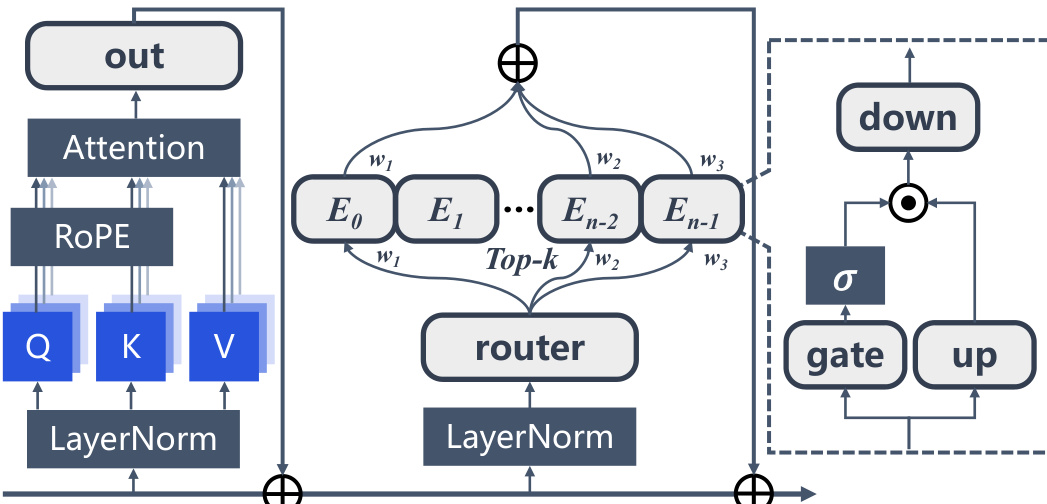
Mixture-of-Experts (MoE) LLMs extend the vanilla Transformer architecture by substituting the static feed-forward network with a sparse MoE layer, as illustrated in Figure 8. The hidden representation after multi-head self-attention, Hl′∈Rn×d, passes through Layer Normalization and is fed into the MoE layer. A router network determines which experts to activate via the weight matrix WG∈Rd×E, where the routing weights G∈Rn×E are computed as G=softmax(Hl′WG). Sparse activation of the experts is achieved by selecting the top-k routing weights for each input token, producing the MoE layer output: MoE(Hl′)=∑i∈Top−k(Gi)Gji⋅FFN(LNmoe(Hjl′)),∀j=1…n. In dense LLMs, AS emerges as a stable pattern anchored to the initial tokens. In MoE LLMs, the sparse activation mechanism dynamically routes different tokens to distinct experts during inference. The interaction between the AS mechanism and the MoE architecture gives rise to unique AS manifestations in MoE LLMs where the distribution of AS may influence or be influenced by expert routing decisions.
Multi-modal LLMs (MLLMs) extend the standard Transformer architecture by integrating a vision encoder with a causal LLM backbone via a cross-modal connector. Formally, given an input image x∈RH×W×C, the vision encoder first extracts a sequence of visual tokens: V={v1,v2,…,vN}=fvision(x), where N denotes the number of patches and fvision represents the vision encoder. These visual tokens are then projected via a cross-modal connector P to align with the LLM's embedding space: V′=P(V)={v1′,v2′,…,vN′}, where vi′∈RDllm. The projected visual tokens V′ are concatenated with textual tokens T={t1,…,tM} to form the full input sequence S=[V′,T], which is subsequently processed by the causal LLM. Unlike text-only Transformers, MLLMs operate over heterogeneous receptive fields, requiring textual queries to attend to information-rich visual patches that are inherently non-causal. This multi-modal integration forces the attention mechanism to reconcile magnitude or variance disparities between visual and textual embeddings, directly influencing the emergence and spatial distribution of AS during multimodal inference.
Vision Transformer (ViT) introduces a patch-based tokenization mechanism to adapt the Transformer for image recognition. Given an image x∈RH×W×C, it is first partitioned into a grid of N=HW/P2 patches, where (P,P) is the resolution of each patch, where each patch pi∈RP2C corresponds to a spatial segment of the image. Each patch is then flattened and linearly projected into a D-dimensional embedding: ei=Epi, where E∈RD×(P2C) is a learnable projection matrix. The resulting sequence of N patch embeddings, together with a learnable [CLS] token ecls, serves as input to the Transformer encoder. Building upon the core ViT architecture, subsequent works have extended its capabilities through novel training paradigms. This architectural choice has direct implications for AS behavior: without the forced causality that concentrates attention on initial tokens, AS in ViT is not constrained to the sequence start but may instead emerge on background patches or low-semantic regions that serve as structurally stable anchoring points across the image.
Experiment
The Implicit Attention Bias framework is evaluated through causal interventions and visualization across various architectures, including LLMs and ViTs, to validate its role in explaining attention sinks. The results demonstrate that the Softmax sum-to-one constraint induces a fixed, input-independent bias that accounts for the disproportionate attention received by sink tokens. While the framework provides a unified explanation for this phenomenon, the underlying training dynamics and the relationships between different forms of implicit bias remain areas for future investigation.