Command Palette
Search for a command to run...
화면 위의 튜링 테스트: Mobile GUI Agent의 인간다움(Humanization)을 평가하기 위한 Benchmark
화면 위의 튜링 테스트: Mobile GUI Agent의 인간다움(Humanization)을 평가하기 위한 Benchmark
Jiachen Zhu Lingyu Yang Rong Shan Congmin Zheng Zeyu Zheng Weiwen Liu Yong Yu Weinan Zhang Jianghao Lin
초록
제시해주신 텍스트를 요청하신 전문적인 기술 번역 기준에 따라 한국어로 번역하였습니다.자율형 GUI Agent의 부상은 디지털 플랫폼의 적대적 대응(adversarial countermeasures)을 촉발했으나, 기존 연구들은 탐지 방지(anti-detection)라는 핵심적인 차원보다는 유용성(utility)과 견고성(robustness)을 우선시해 왔습니다. 본 논문에서는 Agent가 인간 중심의 생태계에서 생존하기 위해서는 반드시 '인간화(Humanization)' 능력을 진화시켜야 한다고 주장합니다. 우리는 상호작용을 탐지기(detector)와 행동 편차(behavioral divergence)를 최소화하려는 Agent 사이의 MinMax 최적화 문제로 공식화한 'Turing Test on Screen'을 도입합니다. 이어 모바일 터치 역학(touch dynamics)에 관한 새로운 고충실도(high-fidelity) 데이터셋을 수집하였으며, 분석을 통해 기존의 vanilla LMM 기반 Agent들이 부자연스러운 운동학적 특성(unnatural kinematics)으로 인해 쉽게 탐지될 수 있음을 확인했습니다. 이에 따라 우리는 모방 가능성(imitability)과 유용성 사이의 트레이드오프를 정량화하기 위해 Agent Humanization Benchmark (AHB)와 탐지 지표를 수립합니다. 마지막으로, 휴리스틱 노이즈(heuristic noise)부터 데이터 기반의 행동 매칭(data-driven behavioral matching)에 이르는 방법론을 제안하며, Agent가 성능 저하 없이 이론적·실증적으로 높은 모방 가능성을 달성할 수 있음을 입증합니다. 본 연구는 패러다임을 'Agent가 작업을 수행할 수 있는가'에서 '인간 중심의 생태계 내에서 어떻게 수행하는가'로 전환하며, 적대적인 디지털 환경 내에서 원활한 공존을 위한 토대를 마련합니다.
One-sentence Summary
To enhance anti-detection capabilities, the authors introduce the Turing Test on Screen, which models mobile GUI agent interaction as a MinMax optimization problem and utilizes the Agent Humanization Benchmark and high-fidelity touch datasets to demonstrate that data-driven behavioral matching improves agent imitability without sacrificing task utility.
Key Contributions
- The paper introduces the Turing Test on Screen, a formal framework that models the interaction between a detector and an agent as a MinMax optimization problem focused on minimizing behavioral divergence.
- A new high-fidelity dataset of mobile touch dynamics is presented alongside the Agent Humanization Benchmark (AHB), which provides detection metrics to quantify the trade-off between agent utility and human-like imitability.
- The authors develop humanization methods ranging from heuristic noise to data-driven behavioral matching, demonstrating that agents can achieve high levels of imitability without sacrificing task performance.
Introduction
As autonomous Graphical User Interface (GUI) agents powered by Large Multimodal Models (LMMs) become more prevalent, they face an increasing conflict with digital platforms that rely on human engagement for revenue. While existing research focuses on improving task utility and robustness against environmental perturbations, it largely overlooks the "Detect vs. Anti-Detect" paradigm. This gap is critical because platforms often deploy behavioral biometrics to filter non-human traffic, and current agents are easily identified by their unnatural, mechanical touch kinematics and rigid temporal rhythms.
The authors leverage this challenge to introduce the "Turing Test on Screen," a framework that models agent-platform interaction as a MinMax optimization problem between a detector and an agent. They contribute a high-fidelity dataset of mobile touch and sensor dynamics, establish the Agent Humanization Benchmark (AHB) to quantify the trade-off between imitability and task utility, and propose various humanization strategies—ranging from heuristic noise to data-driven matching—to help agents achieve human-like behavioral nuances.
Dataset
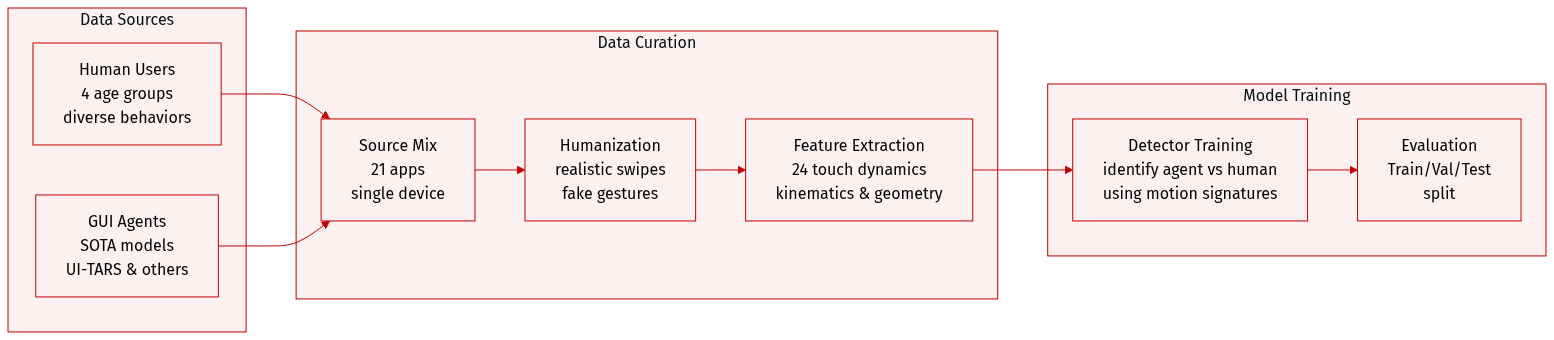
-
Dataset Composition and Sources: The authors constructed a large-scale, multi-modal dataset capturing interactions across 21 diverse applications organized into five functional clusters, such as Social Media and Shopping. The data is sourced from two primary distributions:
- Human Operators: Four distinct sub-populations (Young Man, Young Woman, Middle-aged, and Elderly) to capture physiological and age-related behavioral variances.
- GUI Agents: Action sequences from state-of-the-art models, including UI-TARS, MobileAgent-E (using both GPT-4o and Claude-3.5-Sonnet), AgentCPM, and AutoGLM.
-
Data Processing and Humanization: All data was collected on a single device (Xiaomi Mi Max 2) to ensure consistency. The authors applied humanization techniques to agents in real time rather than post hoc:
- Without fake actions: Tap durations are elongated and swipes are rendered via data-driven trajectory matching.
- With fake actions: Agents undergo tap elongation and swipe humanization, augmented by small circular gestures (50 px radius) emitted from the last tap location following a Poisson process.
- Action Classification: Actions are categorized as taps if they contain fewer than 5 FingerEvents and as swipes if they contain 5 or more.
-
Feature Construction and Metadata: To differentiate between humans and agents, the authors derived 24 statistical features based on touch dynamics, including kinematics (velocity, acceleration), geometry (path efficiency, curvature), and temporal dynamics (duration, latency). The dataset also includes various sensor streams such as the accelerometer, gyroscope, magnetic field, and light sensors, though the primary focus remains on MotionEvents.
-
Model Usage: The authors use the dataset to evaluate the discriminative power of a detector. They utilize the collected motion and sensor events to study the behavioral signatures that distinguish authentic human users from autonomous agents.
Method
The framework for the Agent Humanization Benchmark (AHB) is structured as a Min-Max adversarial game between a Detector DΘ and a GUI Agent GΦ, designed to evaluate the ability of an agent to mimic human-like interaction patterns while maintaining task utility. This adversarial setup is grounded in a hierarchical interaction model, where the agent's actions are decomposed into two levels: the logical action level and the physical event level. At the logical level, the agent generates high-level UI commands—such as taps or swipes—based on the current environmental state st, following the transition dynamics st+1=T(st,at), where at=GΦ(st) is the agent's output. These commands are then translated into fine-grained physical events Et through a mapping function f, resulting in a sequence of motion and sensor events. The motion events capture touch dynamics (coordinates, pressure), while sensor events include data from the gyroscope, magnetometer, and other hardware, collectively forming the behavioral trace E1:T=⋃t=1TEt. This trace serves as the input for the detector, which aims to classify the sequence as human or agent-generated.
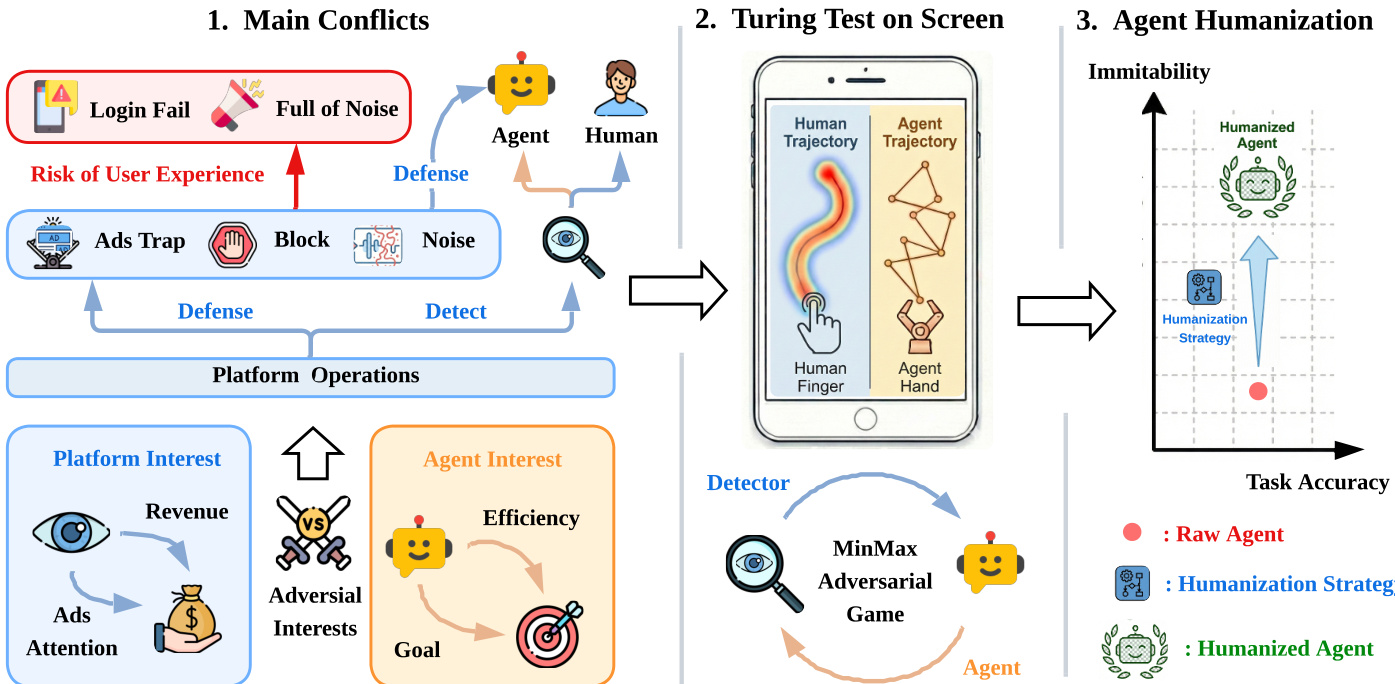
The detector DΘ evaluates the accumulated event stream E1:t at each time step, outputting a probability yt=DΘ(E1:t) that reflects the likelihood of the sequence being human-generated. Its objective is to maximize classification accuracy, formalized as the cross-entropy loss: LD=EE∼H[logDΘ(E)]+EE∼GΦ[log(1−DΘ(E))], where H and GΦ represent the distributions of human and agent-generated event sequences, respectively. In contrast, the agent GΦ must optimize its parameters to minimize detection probability while preserving task utility, leading to a regularized loss function: LG=Es∼S[∑t=1TI(DΘ(E1:t)<τ)−λ⋅Rtask(GΦ)]. Here, τ is a detection threshold, I(⋅) is the indicator function, and Rtask denotes the task success rate, with λ governing the trade-off between imitability and functionality.
To achieve humanization, the framework employs an external wrapper module H that transforms raw agent actions araw into humanized sequences ahuman. Four distinct strategies are proposed to address different aspects of human behavior: (1) Heuristic Noise Injection using B-spline smoothing to introduce biologically plausible curvature into swipe trajectories, (2) Data-Driven History Matching, which aligns agent actions with real human trajectories through affine transformations to preserve authentic velocity profiles and micro-jitters, (3) Fake Actions, which inject non-functional micro-interactions during idle periods to mask inference latencies, and (4) Longer Presses, which sample tap durations from a Gaussian distribution fitted to human data to eliminate the near-zero tap durations characteristic of raw agents. The theoretical foundation for these strategies is provided by theorems that establish the effectiveness of variance injection and the asymptotic superiority of history matching in reducing the Jensen-Shannon divergence between human and agent behavior distributions.
Experiment
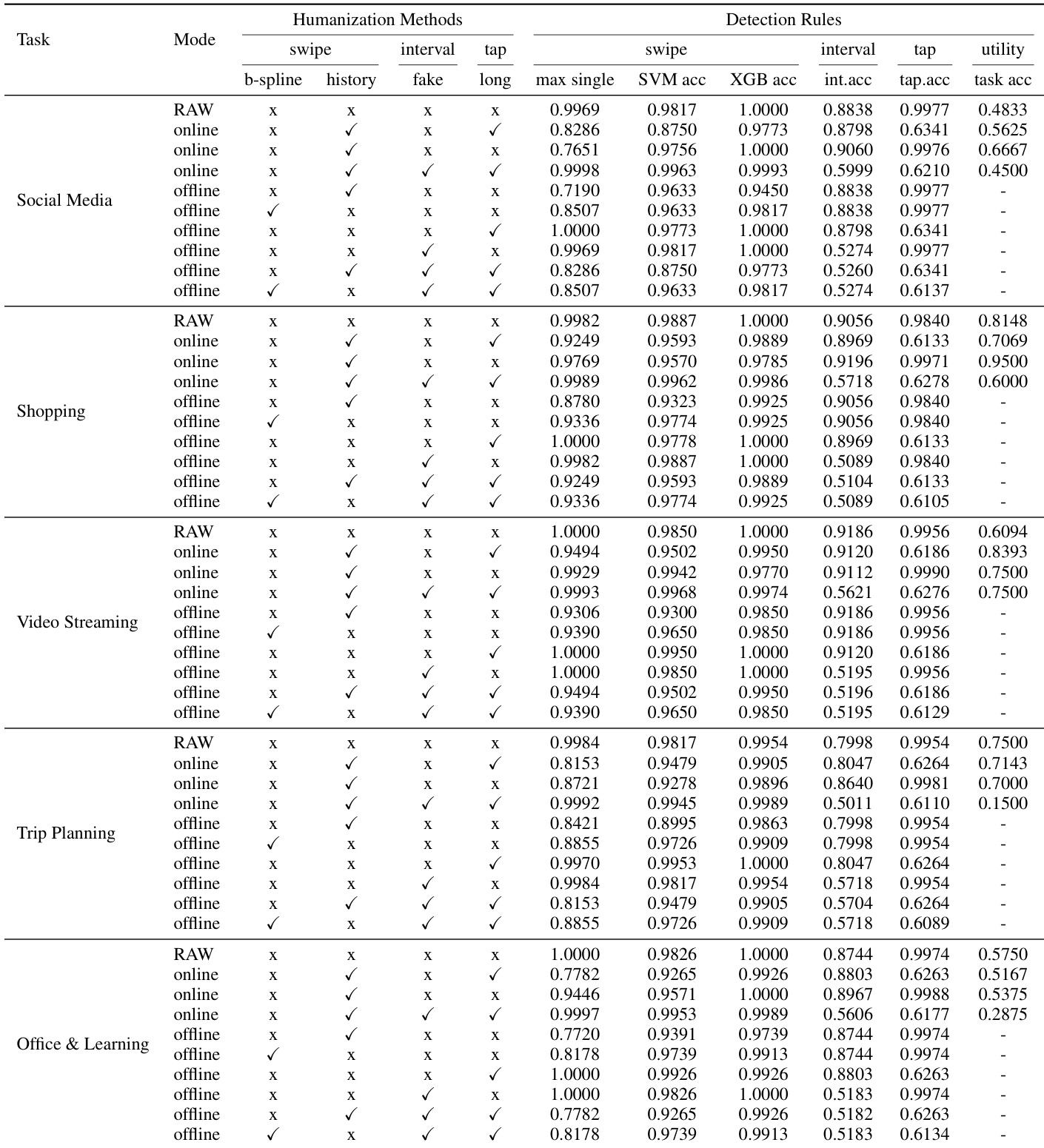
The evaluation compares various humanization strategies, including trajectory adjustment and temporal noise injection, against machine learning classifiers to assess their ability to mask mechanical agent patterns. While geometric features like path shape are easily humanized through empirical data matching, temporal rhythms and endpoint precision remain difficult to mask due to a fundamental trade-off between behavioral imitability and task utility. Ultimately, the results demonstrate that while effective humanization can significantly reduce detection accuracy, naive noise injection can inadvertently introduce new mechanical artifacts or disrupt task success, necessitating more context-aware approaches.
The authors compare various humanization methods across multiple tasks and detection rules, evaluating their effectiveness in reducing detectability while maintaining task utility. Results show that different strategies perform variably depending on the task and detection rule, with some methods significantly lowering detection accuracy but at the cost of utility. History Matching consistently outperforms B-spline Noise in reducing detection accuracy across tasks. Fake Action injection reduces detection accuracy but often leads to significant task utility loss. The effectiveness of humanization varies by task, with some strategies maintaining high utility while others cause substantial performance degradation.
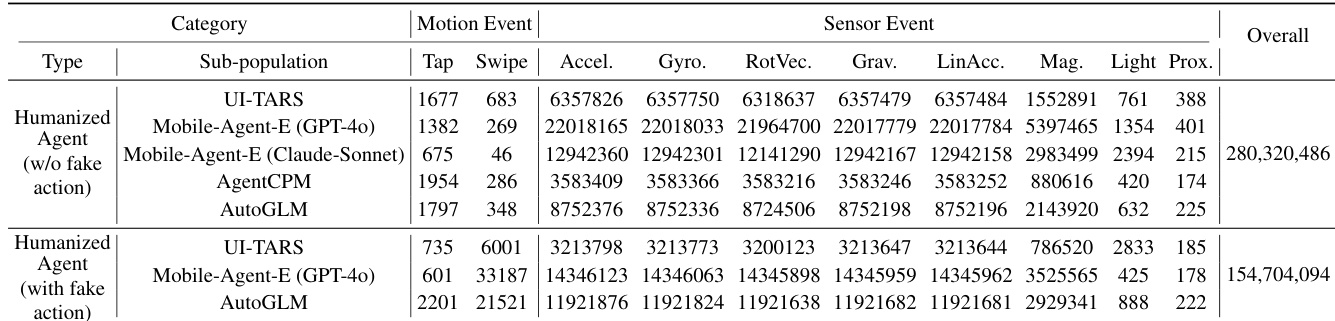
The authors compare the effectiveness of different humanization strategies across motion and sensor events. Results show that humanized agents with fake action injection achieve higher overall detection scores compared to those without, indicating reduced imitability. Humanization with fake action injection leads to higher detection scores than without. Different humanization strategies impact motion and sensor event features differently. The overall detection score is higher for agents with fake action injection.
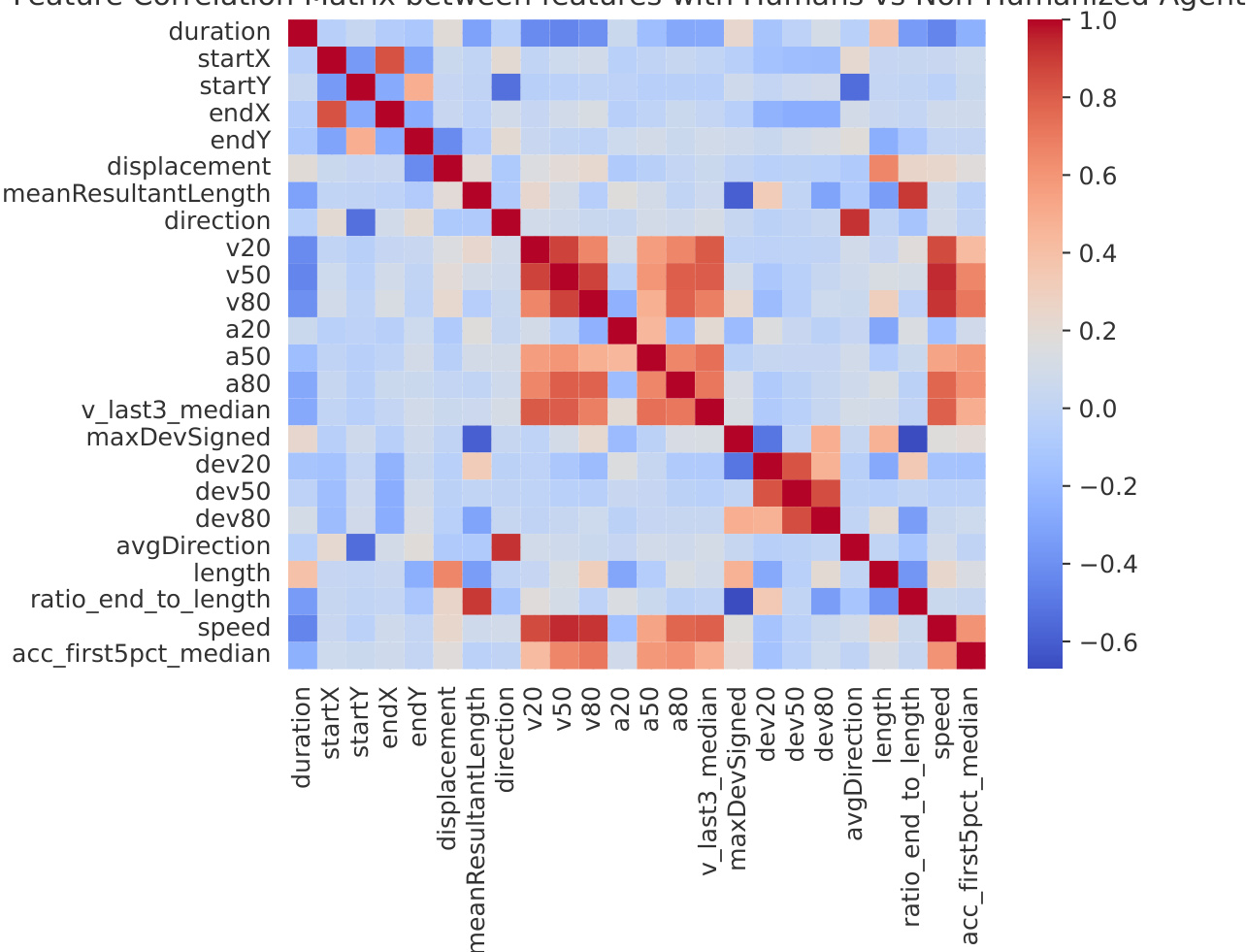
The heatmap visualizes correlations between behavioral features extracted from human and non-humanized agent trajectories. It reveals clusters of highly correlated features, particularly among velocity and deviation metrics, indicating shared patterns in agent motion that differ from human variability. Velocity and deviation features show strong positive correlations among non-humanized agents. Features like duration and start coordinates exhibit mixed correlations, suggesting varied behavioral patterns. The matrix highlights distinct clusters of correlated attributes, reflecting underlying structural differences between human and agent motion.
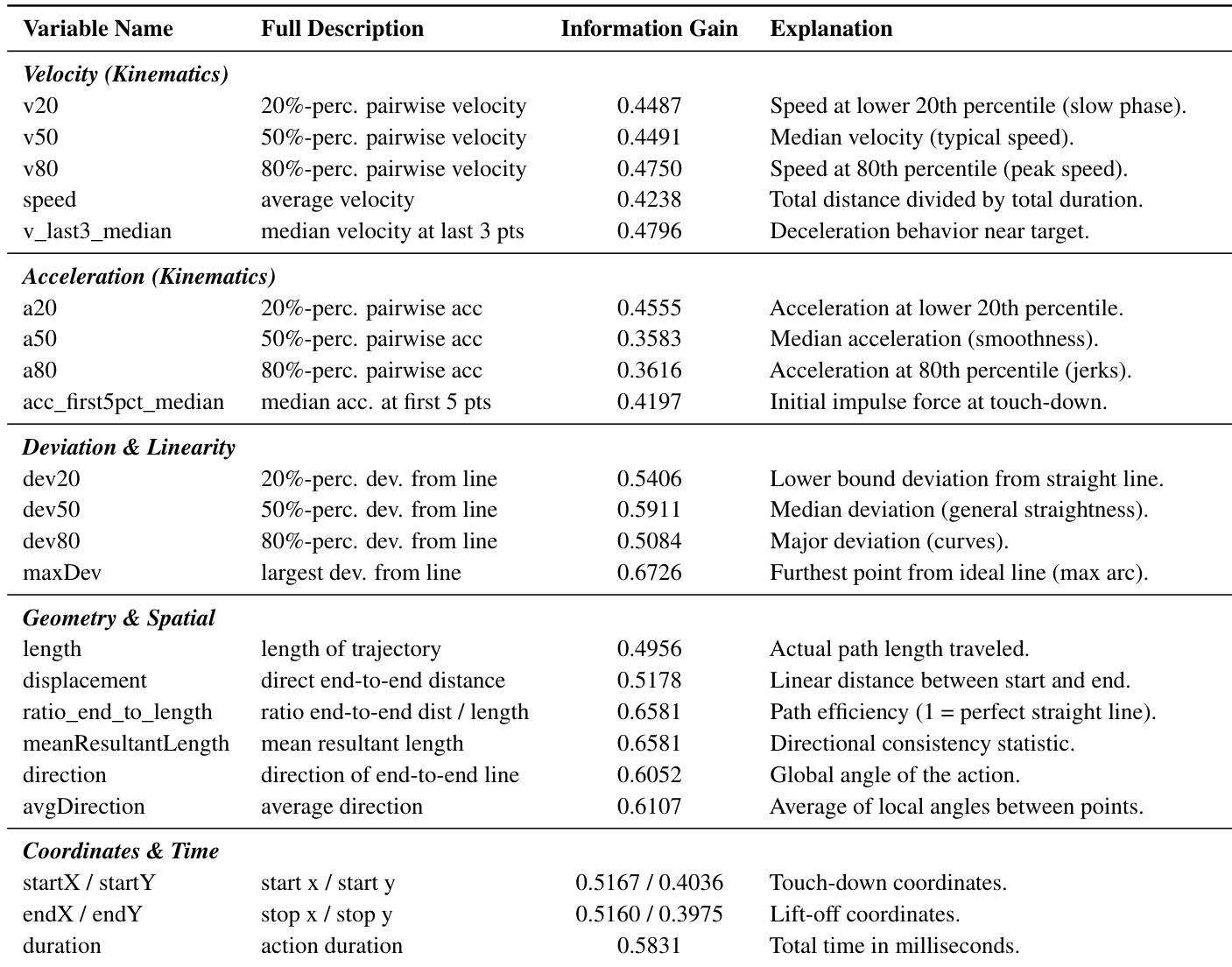
The the the table presents information gain values for various behavioral features, indicating their ability to distinguish between human and agent actions. Features related to trajectory deviation and spatial metrics show higher discriminative power compared to coordinate and temporal attributes. Geometric and deviation features exhibit higher information gain than coordinate and time-based features. Velocity and acceleration metrics show moderate information gain, with peak values around 0.5. Features like maxDev and ratio_end_to_length have high information gain, suggesting they are strong discriminators of human-like behavior.
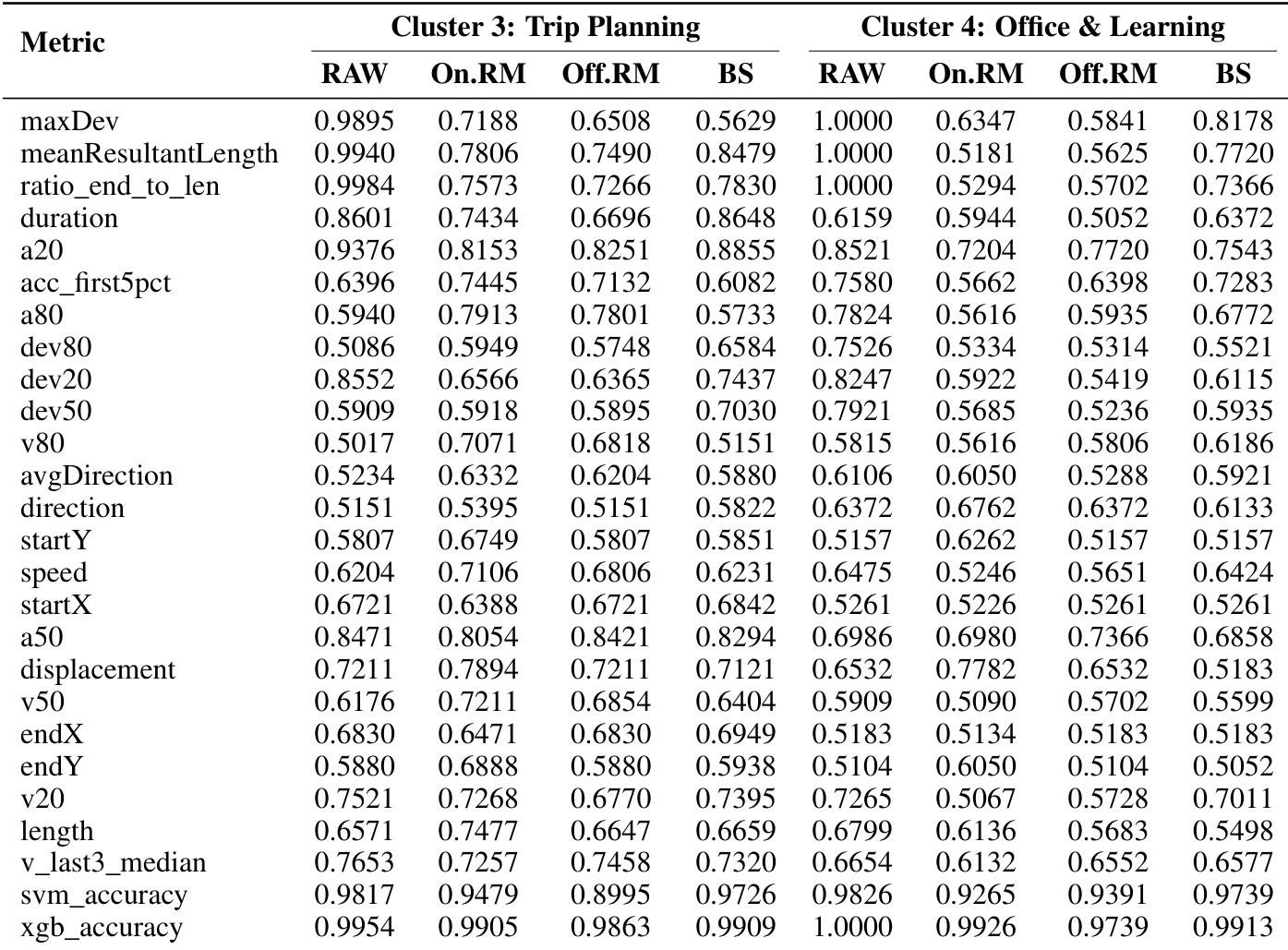
The the the table presents detection accuracy results for different humanization strategies across two application clusters. Results show that humanization methods reduce detectability, with varying effectiveness depending on the feature and cluster. Humanization strategies reduce detection accuracy across most features compared to raw agent data. History Matching shows consistent improvement in reducing detectability across both clusters. The effectiveness of humanization varies by feature, with some metrics like maxDev showing significant reduction while others like duration remain high.
The authors evaluate various humanization strategies across multiple tasks and detection rules to assess their ability to reduce detectability while preserving task utility. The experiments demonstrate that while methods like History Matching consistently lower detection accuracy, others such as fake action injection may cause significant performance degradation. Furthermore, the analysis of feature correlations and information gain reveals that geometric and deviation metrics serve as the most critical discriminators between human and agent behaviors.