Command Palette
Search for a command to run...
ECHO: One-step Block Diffusion을 이용한 효율적인 Chest X-ray Report Generation
ECHO: One-step Block Diffusion을 이용한 효율적인 Chest X-ray Report Generation
초록
흉부 X-ray 리포트 생성(CXR-RG)은 영상의학과 전문의의 업무 부담을 실질적으로 경감시킬 수 있는 잠재력을 가지고 있습니다. 그러나 기존의 자기회귀(autoregressive) vision-language models(VLMs)는 순차적인 token decoding 방식 때문에 높은 inference latency가 발생하는 문제를 안고 있습니다. Diffusion 기반 모델은 병렬 생성을 통해 유망한 대안을 제시하지만, 여전히 여러 번의 denoising iteration 과정을 거쳐야 합니다. 다단계 denoising을 단일 단계로 압축하면 latency를 더욱 줄일 수 있으나, token-factorized denoiser에 의해 발생하는 mean-field bias로 인해 텍스트의 일관성(coherence)이 저하되는 경우가 많습니다.이러한 과제를 해결하기 위해, 본 논문에서는 흉부 X-ray 리포트 생성을 위한 효율적인 diffusion 기반 VLM(dVLM)인 ECHO를 제안합니다. ECHO는 새로운 Direct Conditional Distillation (DCD) 프레임워크를 통해 블록당 단일 단계의 안정적인 inference를 가능하게 합니다. DCD는 on-policy diffusion trajectories로부터 unfactorized supervision을 구축하여 joint token dependencies를 인코딩함으로써 mean-field의 한계를 완화합니다. 또한, 모델의 성능을 유지하면서 training efficiency를 더욱 향상시키는 Response-Asymmetric Diffusion (RAD) training 전략을 도입합니다. 광범위한 실험 결과, ECHO는 최신 autoregressive 방법론들을 능가하며 RaTE와 SemScore를 각각 64.33%와 60.58% 향상시켰으며, 임상적 정확도를 저해하지 않으면서도 8배 빠른 inference 속도를 달성했습니다.
One-sentence Summary
The proposed ECHO, an efficient diffusion-based vision-language model for chest X-ray report generation, utilizes a Direct Conditional Distillation framework and a Response-Asymmetric Diffusion training strategy to enable stable one-step-per-block inference, achieving an 8× inference speedup while surpassing state-of-the-art autoregressive methods with improvements of 64.33% in RaTE and 60.58% in SemScore.
Key Contributions
- The paper introduces ECHO, a discrete diffusion vision-language model designed for chest X-ray report generation that enables stable one-step-per-block inference.
- A novel Direct Conditional Distillation (DCD) framework is presented to mitigate mean-field bias by using unfactorized supervision from on-policy diffusion trajectories to encode joint token dependencies.
- The study implements a Response-Asymmetric Diffusion (RAD) training strategy and a data normalization paradigm to improve training efficiency and reduce clinical hallucinations, resulting in an 8x inference speedup and significant improvements in RaTE and SemScore metrics.
Introduction
Automated chest X-ray report generation (CXR-RG) is essential for reducing the diagnostic workload of radiologists. While autoregressive vision-language models achieve high clinical accuracy, they suffer from high inference latency due to their sequential decoding process. Diffusion-based models offer faster parallel generation, but they typically require multiple denoising iterations to maintain textual coherence because token-factorized denoisers introduce a mean-field bias. The authors leverage a novel Direct Conditional Distillation (DCD) framework to enable stable one-step-per-block inference. By constructing unfactorized supervision from on-policy diffusion trajectories, ECHO encodes joint token dependencies to mitigate mean-field limitations, achieving an 8x inference speedup over state-of-the-art autoregressive methods without compromising clinical accuracy.
Dataset
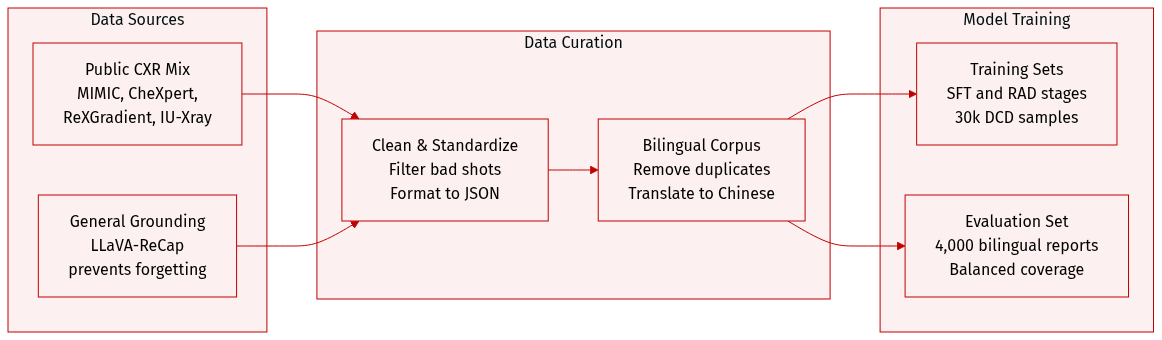
-
Dataset Composition and Sources: The authors constructed a unified chest X-ray (CXR) report corpus by aggregating data from four primary public sources: MIMIC-CXR (approximately 260k reports), CheXpert-Plus (250k reports), ReXGradient (190k reports), and IU-Xray (30k reports). To prevent catastrophic forgetting during training, they also incorporate a subset of the LLaVA-ReCap-558K dataset for general multimodal grounding.
-
Data Processing and Metadata Construction: The corpus undergoes a five-stage preprocessing pipeline:
- Modality Filtering: Non-CXR studies and samples with incomplete clinical descriptions are removed via clinical entity extraction.
- Standardization: A prompt-based rewriting pipeline using BaichuanM2-32B is used to standardize terminology and enforce a structured Findings and Impression format in JSON. This process also normalizes reports by explicitly enumerating all negative findings.
- Semantic Deduplication: Near-duplicates are removed using Qwen3-Embedding-8B and a cosine-similarity threshold.
- Bilingual Augmentation: To create a bilingual dataset, the authors randomly sample 50% of the original reports and translate them from English to Chinese using BaichuanM2-32B, with specific prompts used to maintain medical terminology and structure.
-
Model Training and Evaluation:
- Training: The authors use the standardized bilingual corpus for the Supervised Fine-Tuning (SFT) stage. For the Direct Reinforcement Learning (RAD) stage, they use the same data as the SFT stage. For the DCD stage, they randomly sample 30,000 examples from the RAD training set, ensuring proportional representation across the different source datasets.
- Evaluation: The evaluation set consists of 2,000 English and 2,000 Chinese reports sampled from the normalized MIMIC-CXR, CheXpert-Plus, and ReXGradient datasets to ensure balanced coverage across languages and sources.
Method
The ECHO framework is constructed through a three-stage training pipeline designed to transition from an autoregressive vision-language model to a high-throughput block diffusion model capable of one-step-per-block decoding. The overall approach begins with a base model, which undergoes successive adaptations to optimize both performance and inference speed.
The training process initiates in Stage 1 with continued pre-training (CPT) on a curated corpus of chest X-ray (CXR) reports using the Lingshu-7B model. This stage produces ECHOAR, an autoregressive (AR) vision-language model specialized for generating radiology reports. The primary objective of the subsequent stages is to convert this AR model into a block diffusion model that retains its domain knowledge while enabling faster decoding. In Stage 2, the authors propose Response-Asymmetric Diffusion (RAD) adaptation to transform ECHOAR into ECHOBase. This method is designed to be more efficient than prior two-stage approaches by avoiding the redundant duplication of long vision token sequences. As shown in the framework diagram, RAD duplicates only the response portion of the training sequence and employs a block attention mask that allows each noisy response block to attend to all vision and instruction tokens as well as previously decoded blocks. This asymmetric design significantly reduces training FLOPs and consolidates the adaptation into a single supervised fine-tuning (SFT) stage.
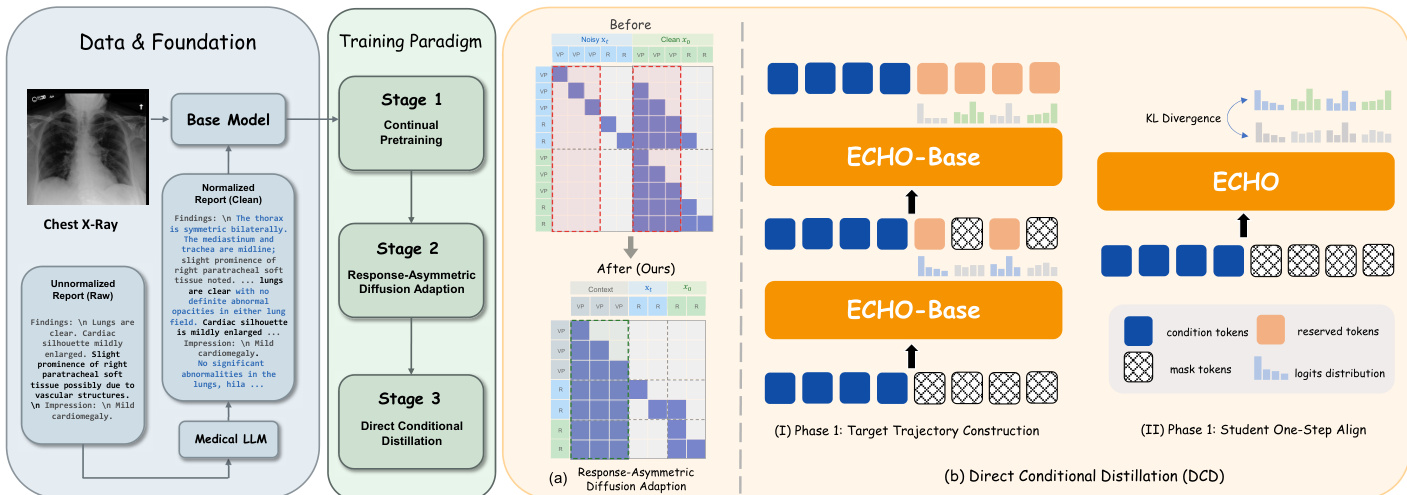
In Stage 3, the model is further optimized for maximum inference throughput through Direct Conditional Distillation (DCD). The goal is to convert ECHOBase into a model that can generate each block of the report in a single forward pass. This requires training a student model to predict the entire block's token distribution in one step, which necessitates a non-factorized training target that captures the inter-token dependencies accumulated during the teacher's multi-step denoising process. The DCD procedure consists of two iterative phases. In Phase 1, a confidence-heuristic denoising trajectory is collected from the teacher model, where tokens are progressively unmasked based on their prediction confidence. The distributions and committed tokens from this process are used to construct a joint supervision target. In Phase 2, the student model is aligned to this target by minimizing the forward Kullback-Leibler (KL) divergence between the student's one-step prediction and the teacher's joint distribution for each block. This alignment process is reinforced by a token reweighting scheme that assigns higher weights to tokens unmasked later in the denoising process, thereby providing stronger supervision for positions subject to greater mean-field bias.
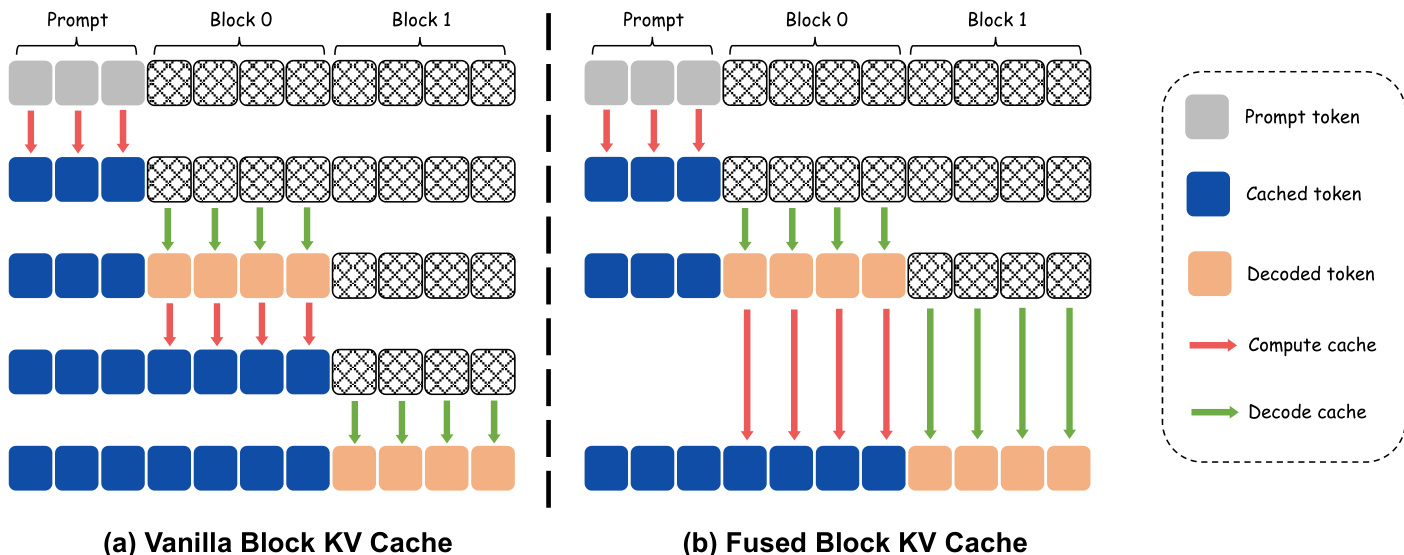
To further maximize inference throughput, the framework employs a fused block key-value (KV) cache mechanism. The standard approach, illustrated in the diagram, involves a dedicated forward pass after each block is decoded to update the KV cache for the newly generated tokens. For a one-step-per-block model, this results in two forward passes per block, doubling the inference cost. The proposed fused block KV cache eliminates this overhead by integrating the KV update for the preceding block directly into the denoising forward of the current block. This fusion is achieved by processing both the decoded tokens of the previous block and the masked tokens of the current block in a single forward pass. The model simultaneously computes the key-value states for the previous block while denoising the current block's tokens, thereby removing the need for a separate KV update pass. This optimization reduces the total number of forward passes from 2N to N for N response blocks while preserving the total FLOPs of the vanilla approach, directly lowering inference latency.

Experiment
The evaluation compares ECHO against general-purpose proprietary models, autoregressive medical VLMs, and diffusion-based distillation baselines to assess report quality, clinical fidelity, and structural stability. Results demonstrate that ECHO consistently outperforms existing state-of-the-art models in clinical accuracy and linguistic fluency while offering a superior quality-speed trade-off through its Direct Conditional Distillation strategy. Furthermore, ablation studies and data scale analyses confirm that components like step-wise weighting and explicit end-of-sequence supervision are critical for mitigating generation artifacts and ensuring reliable clinical reporting.
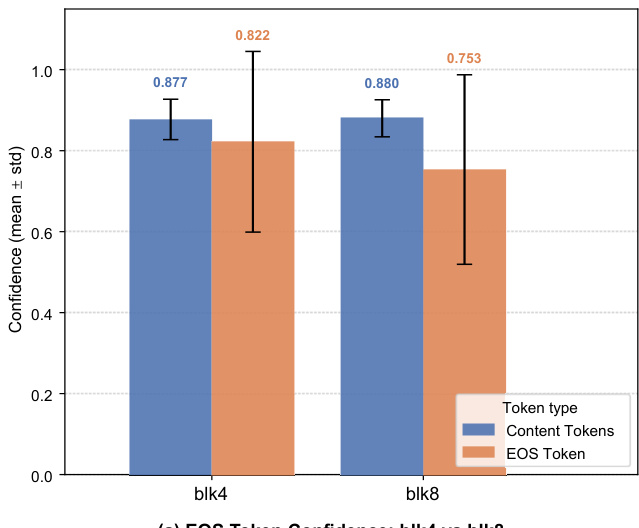
The chart compares the confidence of EOS tokens and content tokens across two block sizes, blk4 and blk8. Results show that content tokens have higher confidence than EOS tokens in both configurations, with a notable gap in blk4 where content token confidence is significantly higher. Content tokens exhibit higher confidence than EOS tokens in both block sizes The confidence gap between content and EOS tokens is more pronounced in blk4 EOS token confidence is lower in blk8 compared to blk4
The authors compare ECHO against state-of-the-art models across linguistic quality, clinical fidelity, and structural stability metrics. Results show that ECHO consistently outperforms both general-purpose and medical-specific models, achieving superior clinical accuracy while maintaining high efficiency in report generation. ECHO achieves the best performance across all metrics compared to proprietary, autoregressive, and diffusion-based models. ECHO significantly outperforms larger medical models in clinical fidelity metrics. ECHO demonstrates a favorable trade-off between speed and quality, with substantial decoding speedup and minimal quality degradation.
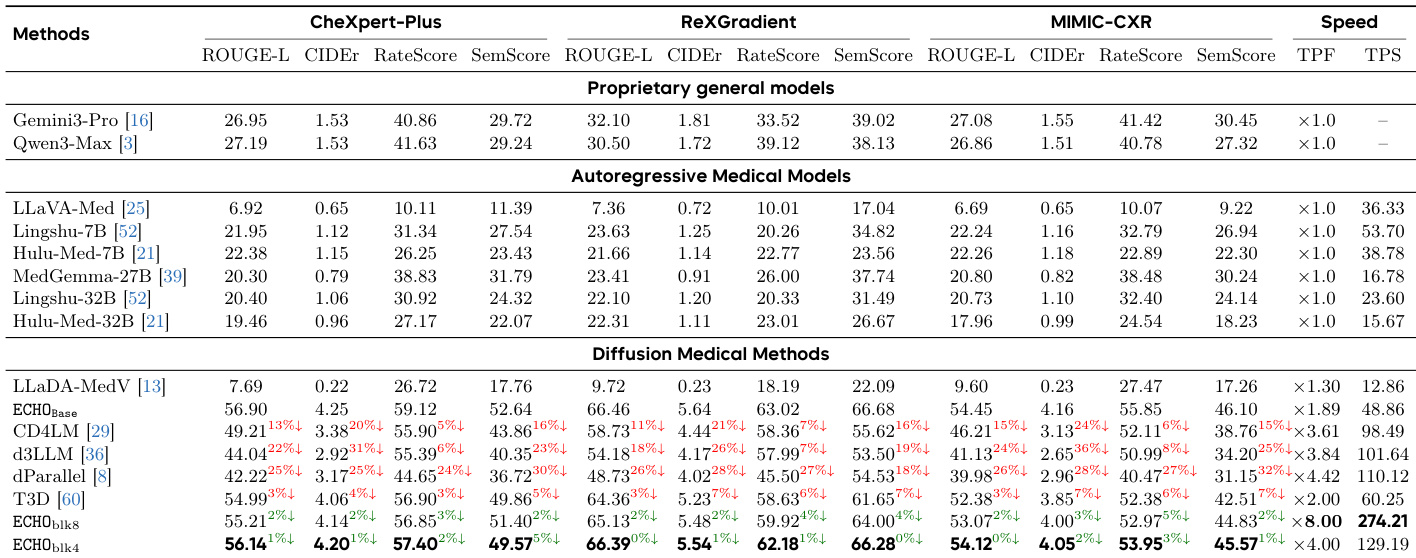
The authors compare ECHO against various state-of-the-art models across proprietary, autoregressive, and diffusion-based categories. Results show that ECHO achieves superior performance in clinical fidelity and linguistic quality, particularly in English, while maintaining strong results in Chinese. Diffusion-based methods, including ECHO, demonstrate competitive or better performance than autoregressive models in key metrics. ECHO outperforms all other models in clinical fidelity and linguistic quality metrics, especially in English. Diffusion-based models, including ECHO, achieve competitive results compared to autoregressive models, with ECHO showing the highest scores. Proprietary models like Gemini3-Pro and Qwen3-Max perform well in some metrics but are outperformed by ECHO in clinical content accuracy and report fluency.
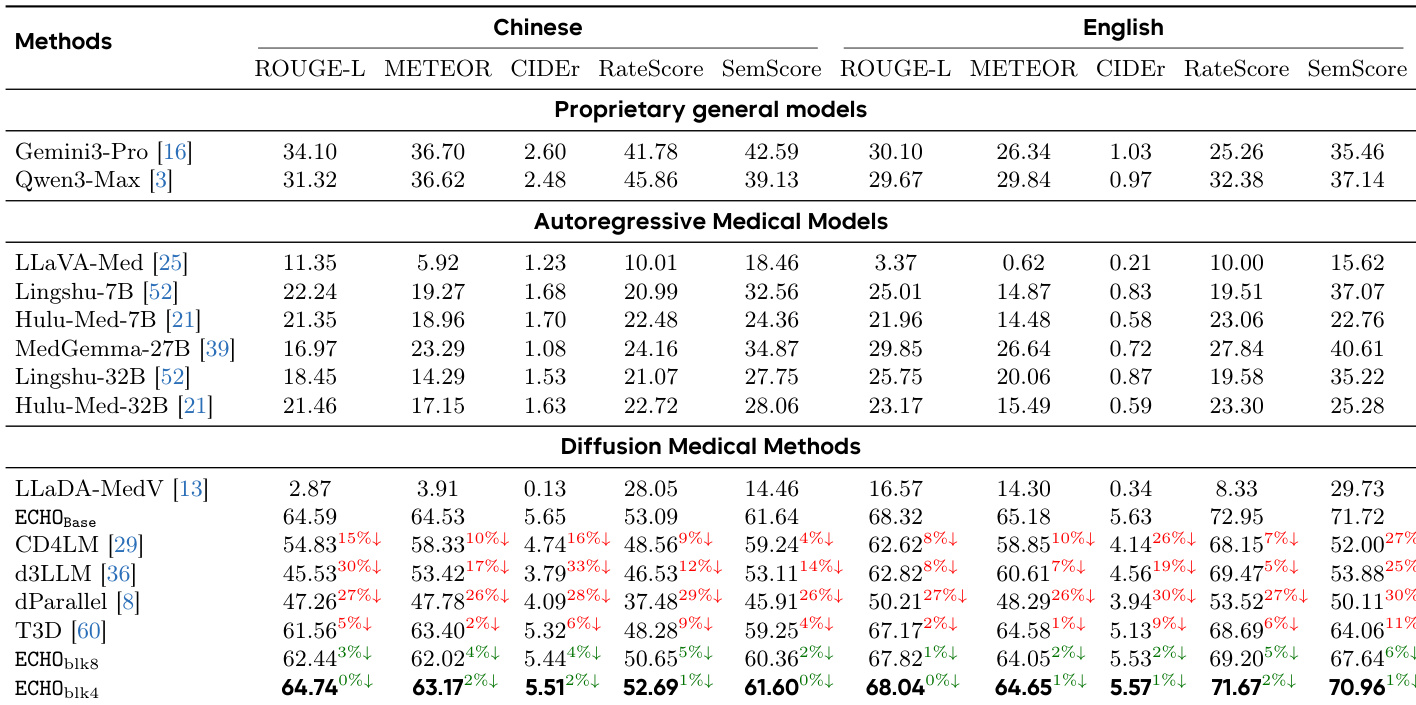
The authors compare ECHO models with different block sizes against their base models on multiple datasets, showing improvements in linguistic and clinical metrics. Results indicate that ECHO consistently outperforms ECHO_Base across all benchmarks, with higher ROUGE-L, CIDEr, and SemScore values, demonstrating enhanced report quality. ECHO models achieve higher ROUGE-L, CIDEr, and SemScore across all datasets compared to ECHO_Base. ECHO shows consistent improvements in both linguistic and clinical fidelity metrics over ECHO_Base. Performance gains are observed across different block sizes, indicating robustness of the ECHO approach.

The the the table shows the impact of using normalized versus unnormalized reports across three training stages. Normalized reports consistently lead to higher performance across all metrics and stages, while unnormalized reports result in significant degradation, especially in clinical fidelity metrics. Normalized reports yield consistently higher performance across all stages and metrics compared to unnormalized reports. Unnormalized reports cause substantial degradation in clinical fidelity metrics, particularly in Stage III. The performance gap between normalized and unnormalized reports widens as training progresses through the stages.

The experiments evaluate the performance of the ECHO model through token confidence analysis, comparative benchmarks against state-of-the-art models, and ablation studies on block sizes and report normalization. ECHO consistently demonstrates superior clinical fidelity and linguistic quality compared to proprietary, autoregressive, and diffusion-based models while maintaining an efficient balance between speed and accuracy. Furthermore, the results indicate that using normalized reports and optimized block sizes significantly enhances report quality and ensures robust performance across various datasets.