Command Palette
Search for a command to run...
SPPO: Long-Horizon Reasoning Tasks를 위한 Sequence-Level PPO
SPPO: Long-Horizon Reasoning Tasks를 위한 Sequence-Level PPO
Tianyi Wang Yixia Li Long Li Yibiao Chen Shaohan Huang Yun Chen Peng Li Yang Liu Guanhua Chen
초록
제시해주신 영문 텍스트를 요청하신 전문적인 기술 번역 기준에 따라 한국어로 번역하였습니다. (참고: 요청 사항에 '사용자 질문에 한국어로 답변하라'고 되어 있어, 번역 결과물 자체를 한국어로 작성하였습니다.)[번역문]Proximal Policy Optimization (PPO)는 검증 가능한 보상(verifiable rewards)을 활용하여 추론 작업에서의 Large Language Models (LLMs)를 정렬(aligning)하는 데 핵심적인 역할을 합니다. 그러나 표준적인 token-level PPO는 긴 Chain-of-Thought (CoT) 과정에서 발생하는 시간적 신용 할당(temporal credit assignment)의 불안정성과 value model의 과도한 메모리 비용 문제로 인해 이러한 환경에서 어려움을 겪습니다. GRPO와 같이 critic-free 방식을 사용하는 대안들이 이러한 문제를 완화하기도 하지만, baseline 추정을 위해 여러 개의 sample을 필요로 하기 때문에 상당한 계산 오버헤드가 발생하며, 이는 training throughput을 심각하게 제한합니다. 본 논문에서는 PPO의 sample efficiency와 결과 기반 업데이트(outcome-based updates)의 안정성을 조화시킨 확장 가능한 알고리즘인 Sequence-Level PPO (SPPO)를 소개합니다. SPPO는 추론 과정을 Sequence-Level Contextual Bandit 문제로 재정의하며, 디커플링된 스칼라 가치 함수(decoupled scalar value function)를 채택하여 multi-sampling 없이도 저분산 advantage signal을 도출합니다. 수학적 benchmark에 대한 광범위한 실험 결과, SPPO는 표준 PPO를 크게 능가할 뿐만 아니라 계산 집약적인 group-based 방식의 성능과도 대등한 수준을 보여주었으며, 추론용 LLM을 정렬하기 위한 자원 효율적인 프레임워크를 제공합니다.
One-sentence Summary
The authors propose SPPO, a scalable sequence-level reinforcement learning algorithm that reformulates long-horizon reasoning as a contextual bandit problem and employs a decoupled scalar value function to achieve low-variance advantage signals without the multi-sampling overhead of group-based methods, significantly outperforming standard PPO on mathematical benchmarks.
Key Contributions
- The paper introduces Sequence-Level PPO (SPPO), an algorithm that reformulates the reasoning process as a Sequence-Level Contextual Bandit problem to harmonize sample efficiency with the stability of outcome-based updates.
- This work implements a Decoupled Critic strategy that uses a lightweight critic to align a larger policy, which reduces memory usage by 12.8% while enabling high-throughput single-sample updates.
- Extensive evaluations on mathematical benchmarks such as AIME, AMC, and MATH demonstrate that SPPO matches the performance of group-based methods like GRPO while achieving a 5.9x training speedup.
Introduction
Aligning Large Language Models (LLMs) for complex reasoning tasks requires Reinforcement Learning with Verifiable Rewards (RLVR) to ensure logical correctness. While standard token-level Proximal Policy Optimization (PPO) is widely used, it suffers from unstable temporal credit assignment and high memory costs when dealing with long Chain-of-Thought horizons. Conversely, critic-free methods like Group Relative Policy Optimization (GRPO) reduce bias but introduce high variance and significant computational overhead because they require sampling multiple responses per prompt to estimate baselines. The authors leverage a new perspective that treats reasoning as a Sequence-Level Contextual Bandit problem rather than a multi-step Markov Decision Process. They introduce Sequence-Level PPO (SPPO), which uses a learned scalar value function to provide stable advantage signals. This approach allows for high-throughput single-sample updates, matching the performance of group-based methods while achieving a significant training speedup.
Method
The authors leverage a sequence-level optimization framework to address the challenges of credit assignment in long-horizon reasoning tasks. The proposed method, SPPO, reformulates the standard token-level Markov Decision Process (MDP) into a Sequence-Level Contextual Bandit (SL-CB) setting, where the entire generated response sequence is treated as a single atomic action. This shift fundamentally alters the policy optimization process by eliminating the need for a token-level critic that attempts to estimate future returns from intermediate states. Instead, SPPO introduces a scalar value model Vϕ(sp), which predicts the probability of success for a given prompt sp. This value function is trained using Binary Cross-Entropy (BCE) loss to ensure it serves as a calibrated baseline for the advantage calculation.
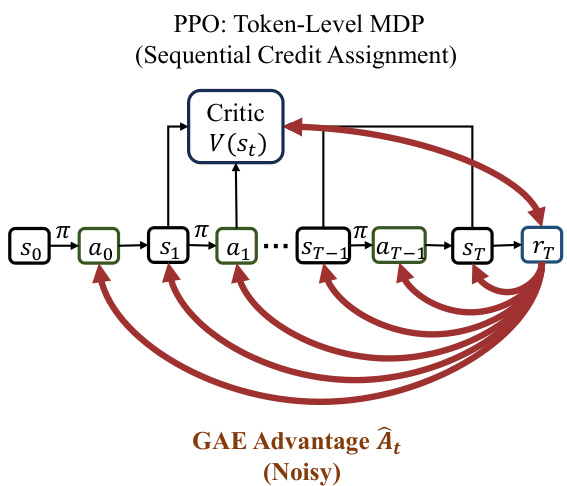
As shown in the figure below, the standard PPO framework operates within a token-level MDP, where the policy π generates actions at sequentially from states st. A critic V(st) estimates the value of each intermediate state, and the advantage A^t is computed via Generalized Advantage Estimation (GAE), which sums discounted temporal difference errors. This mechanism leads to noisy, position-dependent credit assignment, as the advantage signal is heavily influenced by the token's position in the sequence, causing the "tail effect" where rewards are only propagated effectively near the end of the generation.
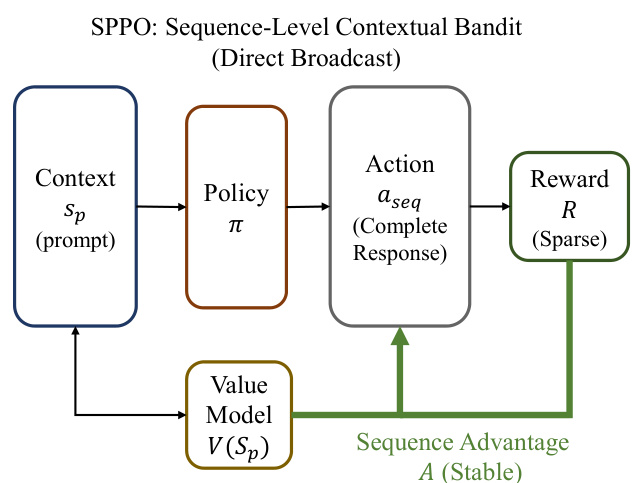
In contrast, the SPPO framework, as illustrated in the figure below, operates on the prompt sp as the sole context. The policy π outputs a complete response sequence aseq, which is then evaluated by a sparse reward function R to determine its correctness. The advantage is computed as a simple scalar difference A(sp,a)=R−Vϕ(sp), which is then directly broadcast to every token within the generated sequence. This sequence-level advantage A is stable and independent of the response length, effectively solving the temporal credit assignment problem by reinforcing or penalizing the entire chain of actions uniformly based on the final outcome. The policy optimization objective adapts the PPO clipped surrogate objective but applies the single sequence-level advantage to all tokens, ensuring that the policy update is aligned with the holistic success or failure of the reasoning process.
Experiment
The evaluation compares the proposed SPPO algorithm against several baselines, including standard PPO, GRPO, RLOO, and ReMax, using mathematical reasoning benchmarks and reinforcement learning control tasks. Results demonstrate that SPPO achieves superior performance and faster convergence by utilizing a sequence-level contextual bandit formulation that effectively resolves credit assignment issues in sparse-reward settings. Furthermore, the study validates that decoupling the critic size from the policy significantly reduces memory overhead without sacrificing accuracy, making large-scale reasoning model alignment more resource-efficient.
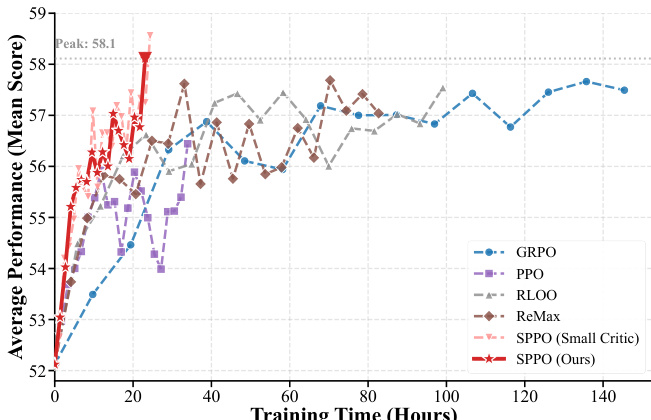
The results show that SPPO achieves higher average performance and faster convergence compared to baseline methods. The approach demonstrates improved training efficiency, with SPPO reaching peak performance more quickly than other algorithms. SPPO outperforms all baselines in average performance and convergence speed SPPO achieves peak performance significantly faster than group-based methods The small critic variant of SPPO maintains high performance while reducing computational overhead
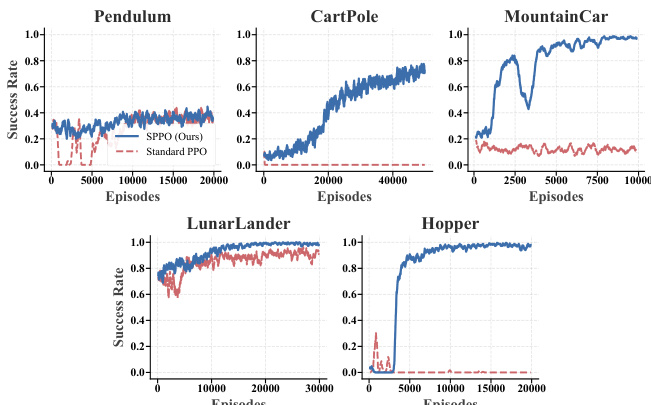
The authors evaluate SPPO against Standard PPO across five control tasks with sparse rewards. Results show SPPO consistently converges and outperforms Standard PPO, particularly in long-horizon tasks where the baseline fails. SPPO achieves robust convergence across all control tasks, while Standard PPO fails in complex environments. In long-horizon tasks, SPPO successfully solves problems where Standard PPO remains at low success rates. SPPO demonstrates superior sample efficiency, rapidly improving in precision tasks like CartPole.
The the the table compares the performance of various reinforcement learning methods on mathematical reasoning benchmarks. SPPO consistently achieves higher average scores than baselines, with the best results observed when using a smaller critic model. The authors use a sequence-level advantage estimation method to improve training stability and efficiency. SPPO outperforms all baselines on both model scales, achieving the highest average score. Using a smaller critic model improves performance and reduces memory usage while maintaining effectiveness. Standard PPO shows limited improvement over the base model, indicating instability in sparse-reward settings.
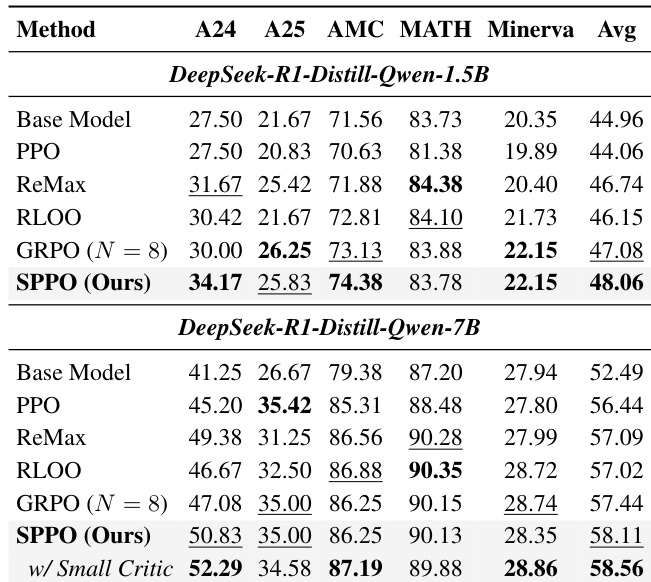
SPPO is evaluated against Standard PPO and other baseline methods across control tasks with sparse rewards and mathematical reasoning benchmarks to validate its training efficiency and stability. The results demonstrate that SPPO achieves superior average performance and faster convergence, particularly in complex, long-horizon environments where baseline methods often fail. Additionally, employing a smaller critic model enhances performance and reduces computational overhead without sacrificing effectiveness.