Command Palette
Search for a command to run...
HY-Embodied-0.5: Real-World Agent를 위한 Embodied Foundation Model
HY-Embodied-0.5: Real-World Agent를 위한 Embodied Foundation Model
HY-Embodied-0.5 원클릭 배포: 현실 세계 에이전트를 위한 신체적 기초 모델
초록
저희는 실제 환경의 Embodied Agent를 위해 특별히 설계된 파운데이션 모델 제품군인 HY-Embodied-0.5를 소개합니다. 일반적인 Vision-Language Models (VLMs)와 Embodied Agent의 요구 사항 사이의 간극을 메우기 위해, 저희 모델은 Embodied Intelligence에 필수적인 핵심 역량인 시공간적 시각적 지각(spatial and temporal visual perception), 그리고 예측, 상호작용 및 계획을 위한 고도의 Embodied Reasoning 능력을 강화하도록 개발되었습니다.HY-Embodied-0.5 제품군은 두 가지 주요 변체(variant)로 구성됩니다. 하나는 에지(edge) 배포를 위해 설계된 2B activated parameters 규모의 효율적인 모델이며, 다른 하나는 복잡한 추론을 목표로 하는 32B activated parameters 규모의 강력한 모델입니다. Embodied task에 필수적인 세밀한 시각적 지각을 지원하기 위해, 저희는 모달리티 특화 컴퓨팅(modality-specific computing)을 가능하게 하는 Mixture-of-Transformers (MoT) 아키텍처를 채택하였습니다. Latent tokens를 통합함으로써, 이 설계는 모델의 지각적 표현(perceptual representation)을 효과적으로 향상시킵니다. 추론 능력을 개선하기 위해, 저희는 반복적이고 자기 진화적인(self-evolving) post-training 패러다임을 도입하였습니다. 또한, On-policy distillation을 적용하여 대형 모델의 고급 역량을 소형 모델로 전이함으로써, 컴팩트한 모델의 성능 잠재력을 극대화했습니다.시각적 지각, 공간 추론 및 Embodied understanding을 아우르는 22개의 benchmark에 대한 광범위한 평가를 통해 저희 방식의 유효성을 입증했습니다. 저희의 MoT-2B 모델은 16개의 benchmark에서 유사한 규모의 최첨단(state-of-the-art) 모델들을 능가하였으며, 32B 변체는 Gemini 3.0 Pro와 같은 프론티어 모델에 필적하는 성능을 달성했습니다. 다운스트림 로봇 제어 실험에서는 저희의 견고한 VLM 파운데이션을 활용하여 효과적인 Vision-Language-Action (VLA) 모델을 학습시켰으며, 실제 물리적 평가에서 놀라운 결과를 얻었습니다.코드와 모델은 다음 링크에서 오픈 소스로 공개됩니다: https://github.com/Tencent-Hunyuan/HY-Embodied
One-sentence Summary
Developed by Tencent Robotics X and the HY Vision Team, HY-Embodied-0.5 is a family of foundation models for real-world agents that utilizes a Mixture-of-Transformers architecture and latent tokens to enhance spatial and temporal perception, while employing an iterative, self-evolving post-training paradigm and on-policy distillation to bridge the gap between general vision-language models and complex embodied reasoning.
Key Contributions
- The paper introduces HY-Embodied-0.5, a family of foundation models featuring a modality-adaptive Mixture-of-Transformers (MoT) architecture and visual latent tokens to enhance fine-grained spatial and temporal perception for embodied agents.
- This work presents an iterative, self-evolving post-training paradigm and a large-to-small on-policy distillation method to transfer complex reasoning capabilities from a 32B parameter model to an efficient 2B parameter variant designed for edge deployment.
- Experimental results across 22 benchmarks demonstrate that the models achieve state-of-the-art performance, with the 32B variant surpassing Gemini 3.0 Pro and the 2B variant outperforming larger models like Qwen3-VL-4B and RoboBrain2.5-4B.
Introduction
While Vision-Language Models (VLMs) have made significant strides in digital intelligence, they often struggle to meet the specialized demands of physical agents. Existing models typically lack the fine-grained visual perception necessary for physical grounding and are inadequately optimized for the dynamic prediction, interaction, and planning required in embodied environments. The authors address these gaps by introducing HY-Embodied-0.5, a family of foundation models designed specifically for real-world agents. They leverage a Mixture-of-Transformers architecture with visual latent tokens to enhance spatial and temporal perception, alongside an iterative, self-evolving post-training paradigm to boost reasoning capabilities. Furthermore, the authors utilize on-policy distillation to transfer advanced intelligence from a large 32B parameter model to an efficient 2B parameter variant optimized for edge deployment.
Dataset

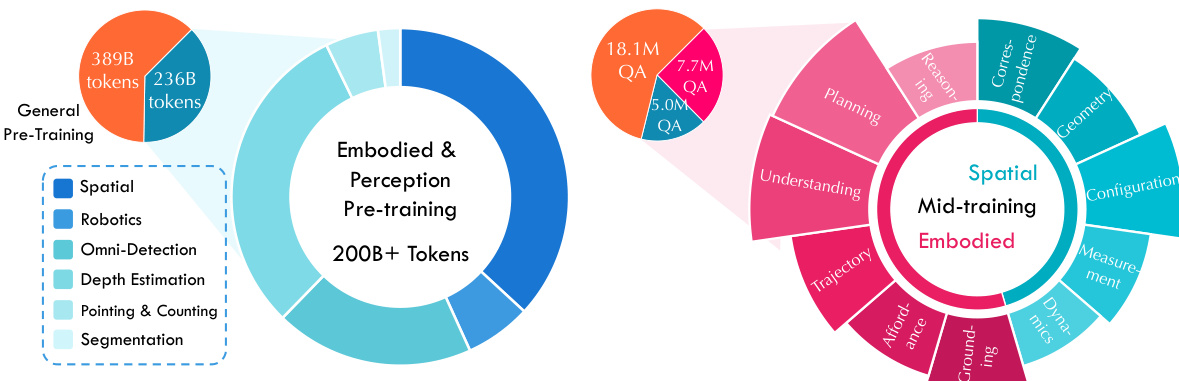
The authors develop a multi-stage training curriculum using a diverse mixture of vision-language data, categorized into four primary domains:
-
Visual Perception Data: This subset focuses on low-level grounding and recognition.
- Omni-Detection (62M samples): Combines 2D and 3D detection data from sources like OpenImages, Objects365, RefCOCO, and SA-1B. The authors use an automated pipeline involving a VLM and SAM to label low-quality data, with a stronger VLM teacher for verification. Coordinates are normalized to an integer range of 0 to 1000.
- Depth Estimation (36M samples): Derived from 3D indoor/outdoor and autonomous driving datasets. The authors use a point-sampling strategy to exclude object boundaries and infinity, and normalize camera focal lengths to standardize scale.
- Segmentation (5M samples): Sourced from SA-1B. The authors filter out excessively small, large, or fragmented masks and use an expanded tokenizer vocabulary to convert masks into question-answering pairs.
- Pointing and Counting (11M samples): Uses ground-truth points from Pixmo-Points and selects high-density scenes from detection corpora to increase task difficulty.
-
Embodied-Centric Data: Organized into a three-tiered hierarchy (perception, semantic understanding, and planning) to support physical agent operations.
- Grounding: Uses Molmo, RoboPoint, and RefSpatial to reinforce spatial recognition of interactive objects and manipulators.
- Affordance: Combines RoboAfford and ShareRobot with VLM-generated user instructions paired with existing grounding annotations.
- Trajectory: Extracted from open-source datasets and manipulation videos using the CoTracker3 model. Trajectories are downsampled to a maximum of 15 waypoints, plotted on images, and verified by a VLM judge.
- Understanding and Planning: Aggregates QA pairs from Robo2VLM, RoboVQA, and others. Planning data is created by using a VLM to temporally segment robotic videos into action-sequence query-response pairs.
- Reasoning: An in-house dataset targeting long-horizon tasks like visual puzzle resolution and intuitive physics.
-
Spatial-Centric Data: Focuses on 3D geometric reasoning using ScanNet, ScanNet++, and ARKitScenes.
- Correspondence and Geometry: Includes cross-frame point matching and 2D-3D mapping, as well as depth estimation and comparison. Geometry tasks use point pairs with a depth disparity of at least 0.3m to ensure clarity.
- Configuration and Measurement: Covers object counting, relative direction, and distance ranking. Measurement tasks provide metric outputs (e.g., centimeters or meters) for object size, absolute distance, and room area, with filters to exclude trivially close objects.
- Dynamics: Captures camera ego-motion and object movement via 3D point tracks.
-
General Understanding Data: Includes in-house data covering semantics, STEM, fine-grained parsing, and agentic operations. This data is partitioned into two subsets for use in pre-training and mid-training stages.
Training and Processing Strategy:
- Pre-training and Mid-training: The pre-training mixture consists of over 200B tokens of spatial, robotics, and perception data. The mid-training stage utilizes over 12M high-quality QA pairs.
- Supervised Fine-Tuning (SFT): The authors construct 100k cold-start Chain-of-Thought (CoT) instances through a human-model collaborative pipeline, which are then evaluated by an LLM for logical correctness.
- Reinforcement Learning (RL): Instead of a fixed dataset, the authors use a capability-adaptive curriculum. They maintain a candidate pool and select samples that lie near the model's current capability frontier (those with partial success) to provide the most informative signals.
Method
The authors leverage a hybrid vision-language model architecture, HY-Embodied-0.5, built upon a foundational Vision-Language Model (VLM) paradigm that integrates a vision encoder and a large language model (LLM). To enhance visual perception while maintaining a balance with language capabilities, particularly for edge deployment, the model incorporates several architectural innovations. The core visual encoder is an efficient, native-resolution Vision Transformer (ViT), specifically HY-ViT 2.0, which is optimized for edge-device deployment. This model supports arbitrary input resolutions and achieves robust perception through knowledge distillation from a larger internal model. It is designed to project visual inputs into the language embedding space, enabling the LLM to process multimodal data. The overall framework is structured around a Mixture-of-Transformers (MoT) design that decouples the processing of visual and textual tokens. As shown in the figure below, the MoT architecture employs modality-specific Query-Key-Value (QKV) and Feed-Forward Network (FFN) parameters, allowing for modality-adaptive computation. This design enables significant improvements in visual performance while mitigating the degradation of language capabilities that often results from heavy visual training.
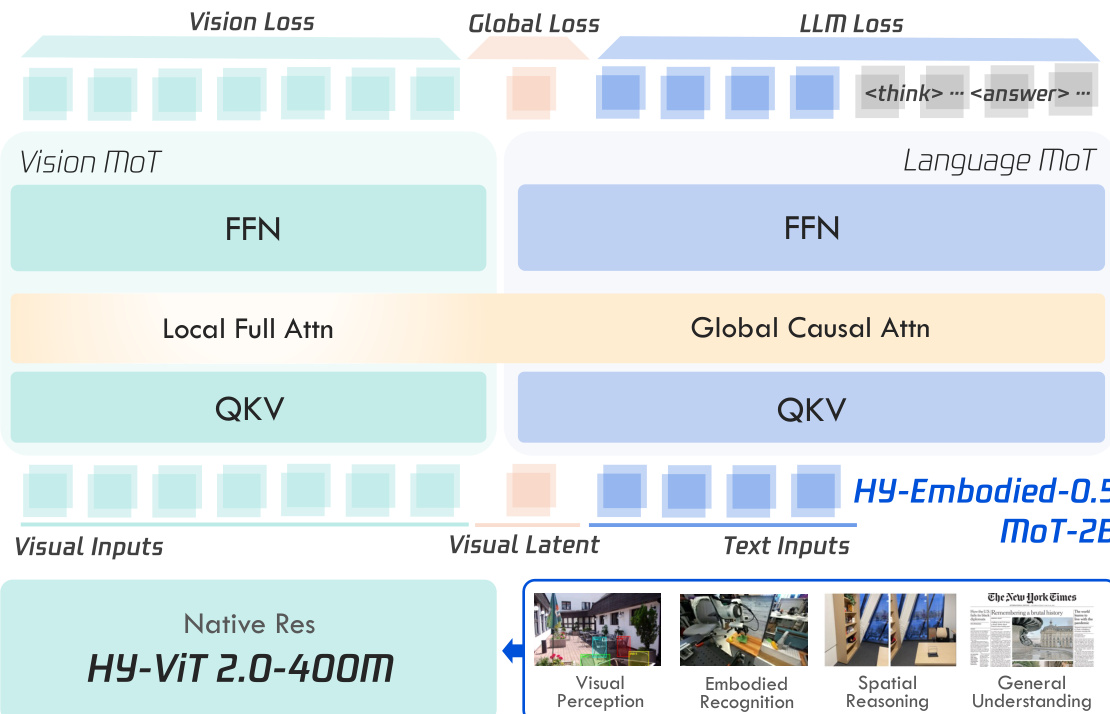
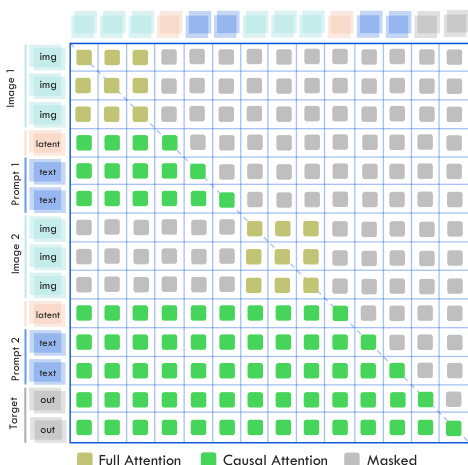
The MoT design is further enhanced with modality-specific attention mechanisms. The authors introduce a distinct local full-attention mechanism for visual tokens, which is more suitable for the bidirectional nature of visual data compared to the unidirectional attention used for text. This is complemented by a global causal attention mechanism for text tokens. The attention computation for the MoT is illustrated in the figure below, where the distinct attention patterns for visual and text tokens are visualized under actual interleaved multi-modal sequences. This modality-specific attention is crucial for effective visual modeling.
To further improve visual modeling, the authors introduce a visual next-code prediction task. This task uses a discrete visual representation generated by a larger ViT as supervision, where an MLP module predicts the discrete code of the next image patch. This provides stronger supervision signals for the vision branch. Additionally, inspired by latent thinking and vision registers, the model appends dedicated, learnable visual latent tokens to the end of each visual input sequence. These tokens are supervised during pre-training using the global features from a large ViT, which helps to connect visual and textual content and enhance the model's overall perceptual capacity. The training pipeline, as depicted in the figure below, is structured into two sequential stages: large-scale pre-training and a targeted mid-training phase. The pre-training stage establishes foundational visual-linguistic alignment over a massive multimodal corpus, while the mid-training stage explicitly enhances complex reasoning capabilities for embodied applications.
The training strategy employs a multi-objective loss function during pre-training, combining a standard LLM loss, a vision loss for the next-code prediction task, and a global loss to align the visual latent tokens with the overall image semantics. The vision loss is formulated as a cross-entropy loss over the predicted logits from the vision branch, while the global loss is defined as the negative cosine similarity between the mapped hidden states of the latent token and the global CLS feature from the teacher ViT. The total loss is the sum of these three objectives. In subsequent mid-training and fine-tuning stages, only the standard autoregressive language loss is optimized. The training recipe involves a cold-start supervised fine-tuning (SFT) phase, followed by an embodied reinforcement learning (RL) stage and an iterative self-evolving training paradigm based on rejection sampling fine-tuning (RFT). Finally, a large-to-small on-policy distillation stage transfers the refined reasoning behaviors from the large model to the compact deployment model.
Experiment
The models are evaluated across 22 diverse benchmarks covering visual perception, 3D spatial comprehension, and embodied agency, as well as through real-world robot control tasks. The results demonstrate that the HY-Embodied-0.5 series achieves state-of-the-art performance, particularly excelling in fine-grained spatial reasoning and complex task planning. Even the compact 2B variant maintains high competitiveness with much larger models, suggesting that the embodied-centric architecture and specialized training effectively balance efficiency with advanced reasoning capabilities.
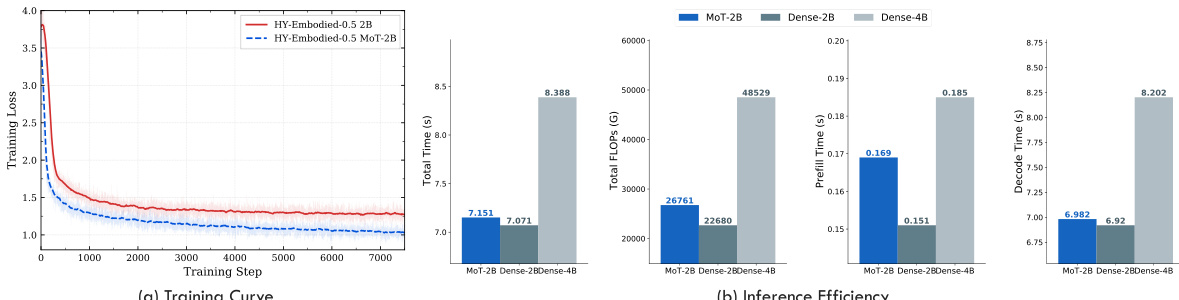
The authors evaluate the efficiency of the Mixture-of-Tokens (MoT) architecture compared to standard dense transformers. Results show that MoT achieves faster convergence during training while maintaining comparable inference speed and efficiency. The model demonstrates improved training dynamics without introducing significant overhead in inference time. MoT architecture converges faster than dense transformers during training MoT achieves comparable inference speed to dense models with minimal overhead MoT reduces training loss more effectively while maintaining efficient inference time
The authors evaluate HY-Embodied-0.5 MoT-2B on a suite of benchmarks covering embodied and spatial understanding. Results show the model achieves strong performance across most tasks, particularly in spatial reasoning, and remains competitive against larger models despite its compact size. HY-Embodied-0.5 MoT-2B achieves top performance on most embodied and spatial benchmarks, demonstrating strong spatial reasoning capabilities. The model outperforms larger baselines on several tasks, indicating its effectiveness is not solely due to scale. Results on real-robot tasks show high success rates, with significant improvements over baseline models in complex manipulation scenarios.
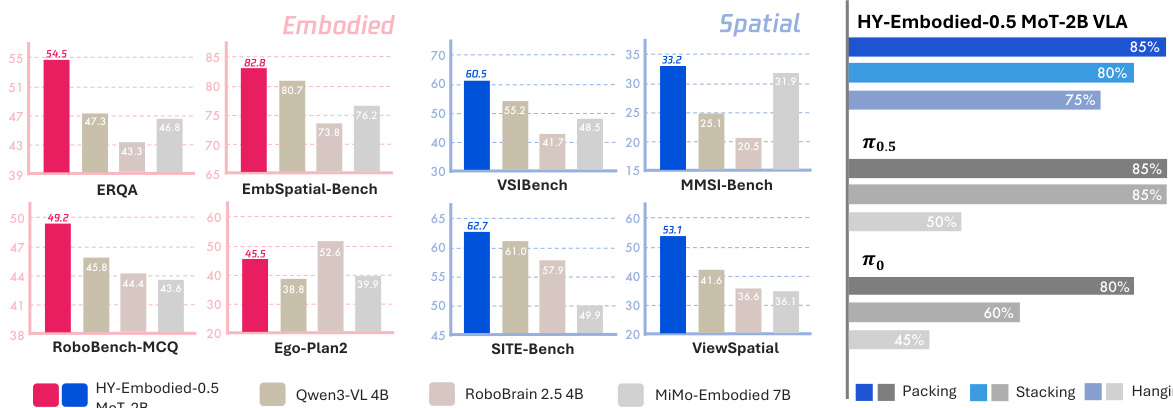
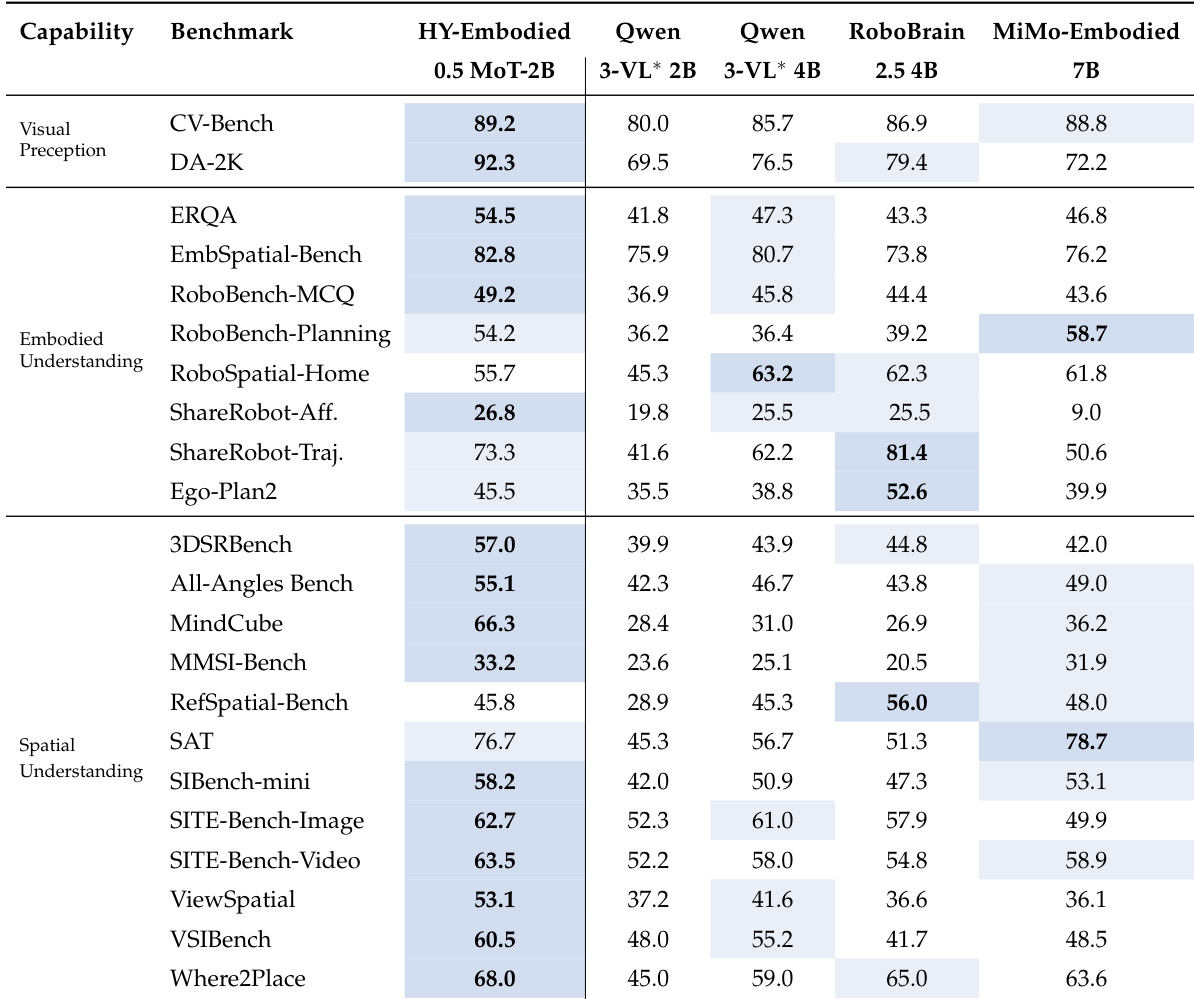
The authors evaluate HY-Embodied-0.5 MoT-2B on a suite of 22 benchmarks covering visual perception, embodied understanding, and spatial understanding. Results show that the model achieves the best performance on most tasks, particularly excelling in spatial understanding and demonstrating strong capabilities in embodied reasoning despite its compact size. HY-Embodied-0.5 MoT-2B achieves the best performance on most benchmarks, especially in spatial understanding tasks. The model demonstrates strong and consistent performance across visual perception, embodied understanding, and spatial reasoning. HY-Embodied-0.5 MoT-2B outperforms larger baseline models, indicating that its gains come from design choices rather than scale alone.
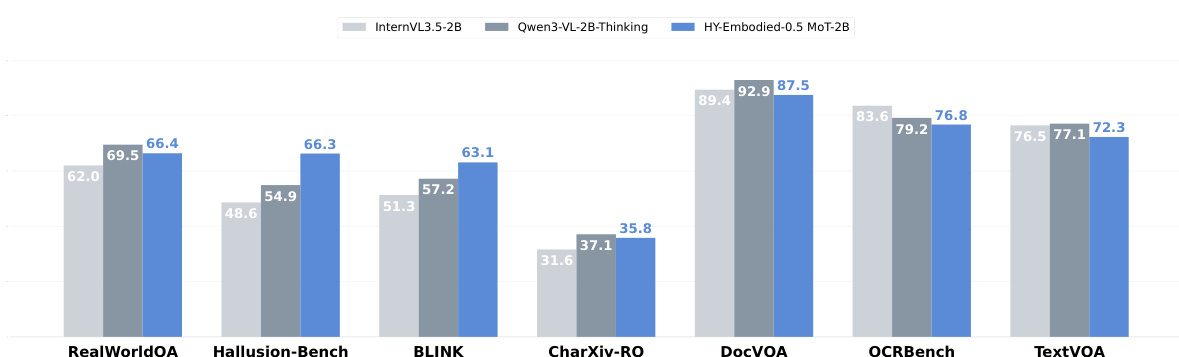
The authors compare HY-Embodied-0.5 MoT-2B with size-matched general VLMs on a set of general visual understanding benchmarks. Results show that the model maintains competitive performance across diverse tasks, demonstrating that its specialized design for embodied reasoning does not compromise its general visual capabilities. HY-Embodied-0.5 MoT-2B achieves competitive performance on general visual understanding benchmarks compared to size-matched general VLMs. The model performs well on tasks requiring visual knowledge, hallucination mitigation, and text-centric reasoning. Despite being optimized for embodied and spatial reasoning, the model maintains strong performance on general visual tasks.
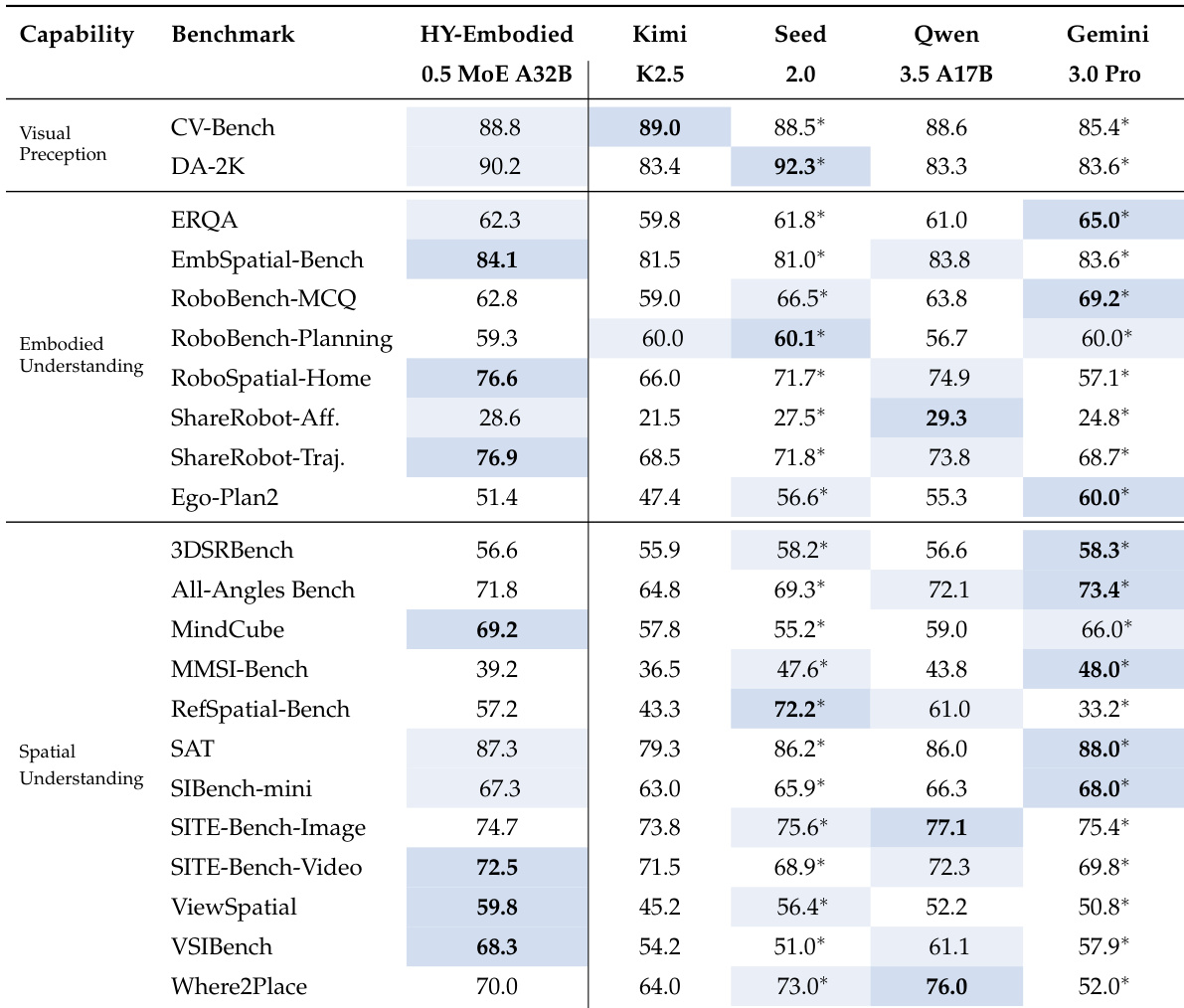
The the the table compares the performance of HY-Embodied-0.5 MoE A32B against several state-of-the-art models across a range of benchmarks categorized into visual perception, embodied understanding, and spatial understanding. The results show that HY-Embodied-0.5 MoE A32B achieves top scores on multiple tasks, particularly excelling in spatial understanding benchmarks. The model demonstrates strong performance across all categories, often outperforming larger models, which suggests that its advantages stem from architectural and training design rather than scale alone. HY-Embodied-0.5 MoE A32B achieves the highest scores on several benchmarks, particularly in spatial understanding, indicating strong spatial reasoning capabilities. The model outperforms larger models like Gemini 3.0 Pro and Kimi K2.5 on most tasks, suggesting that its performance is not solely due to model size. HY-Embodied-0.5 MoE A32B shows competitive results across visual perception and embodied understanding tasks, demonstrating a balanced and robust capability profile.
The authors evaluate the Mixture-of-Tokens (MoT) architecture through efficiency comparisons and extensive benchmarking across embodied, spatial, and general visual understanding tasks. The results demonstrate that the MoT architecture enables faster training convergence with minimal inference overhead while providing superior spatial reasoning and embodied capabilities compared to larger models. Furthermore, the specialized design maintains strong general visual performance, proving that the model's effectiveness stems from architectural innovations rather than scale alone.