Command Palette
Search for a command to run...
FlowInOne: Unifying Multimodal Generation as Image-in, Image-out Flow Matching
FlowInOne: Unifying Multimodal Generation as Image-in, Image-out Flow Matching
Junchao Yi Rui Zhao Jiahao Tang Weixian Lei Linjie Li Qisheng Su Zhengyuan Yang Lijuan Wang Xiaofeng Zhu Alex Jinpeng Wang
초록
멀티모달 생성(Multimodal generation)은 오랫동안 언어가 시각 정보를 지배하지만, 시각 정보 내에서 추론하거나 창조할 수는 없는 텍스트 중심의 pipeline에 의해 주도되어 왔습니다. 본 연구에서는 텍스트 설명, 공간 레이아웃(spatial layouts), 편집 지침(editing instructions)을 포함한 모든 모달리티를 하나의 통일된 시각적 표현으로 통합할 수 있는지 질문함으로써 기존의 패러다임에 도전합니다.본 논문에서는 멀티모달 생성을 순수하게 시각적인 flow로 재구성하여, 모든 입력을 visual prompt로 변환하고 단일 flow matching model에 의해 제어되는 깔끔한 image-in, image-out pipeline을 가능하게 하는 프레임워크인 FlowInOne을 제안합니다. 이러한 비전 중심(vision-centric)의 정식화는 cross-modal alignment 병목 현상, noise scheduling, 그리고 태스크별 아키텍처 분기를 자연스럽게 제거하며, text-to-image 생성, 레이아웃 가이드 편집(layout-guided editing), 시각적 지시 이행(visual instruction following)을 하나의 일관된 패러다임 아래 통합합니다.이를 지원하기 위해, 물리 법칙을 인지하는 힘의 역학(physics-aware force dynamics) 및 궤적 예측(trajectory prediction)을 포함한 다양한 태스크를 아우르는 500만 개의 visual prompt 쌍으로 구성된 대규모 데이터셋인 VisPrompt-5M을 도입합니다. 이와 더불어 지시 이행의 충실도(instruction faithfulness), 공간적 정밀도(spatial precision), 시각적 사실성(visual realism), 그리고 콘텐츠 일관성(content consistency)을 평가하는 엄격하게 큐레이션된 benchmark인 VP-Bench를 함께 선보입니다.광범위한 실험 결과, FlowInOne은 모든 통합 생성 태스크에서 state-of-the-art 성능을 달성하였으며, 오픈 소스 모델과 경쟁력 있는 상용 시스템을 모두 능가하였습니다. 이는 인지와 창조가 단일한 연속적 시각 공간 내에서 공존하는, 완전한 비전 중심 생성 모델링(vision-centric generative modeling)을 위한 새로운 토대를 마련합니다.
One-sentence Summary
By converting all inputs into visual prompts, FlowInOne unifies text-to-image generation, layout-guided editing, and visual instruction following into a single image-in, image-out flow matching paradigm that eliminates cross-modal alignment bottlenecks through the use of the VisPrompt-5M dataset and evaluation via the VP-Bench benchmark.
Key Contributions
- The paper introduces FlowInOne, a unified flow matching framework that reformulates multimodal generation as a vision-centric image-in, image-out paradigm. This approach converts all inputs into visual prompts to eliminate text encoders and modality-specific bridges, enabling a single model to handle text-to-image generation, layout-guided editing, and visual instruction following.
- This work presents VisPrompt-5M, a large-scale dataset consisting of 5 million visual prompt pairs that cover diverse tasks such as physics-aware force dynamics and trajectory prediction. The dataset provides supervision through continuous visual evolution, allowing for unified training and strong generalization across multiple generative tasks.
- The researchers developed VP-Bench, a curated evaluation benchmark designed to assess model performance across four key dimensions: instruction faithfulness, spatial precision, visual realism, and content consistency. Experiments using this benchmark demonstrate that FlowInOne achieves state-of-the-art performance, surpassing existing open-source and competitive commercial systems.
Introduction
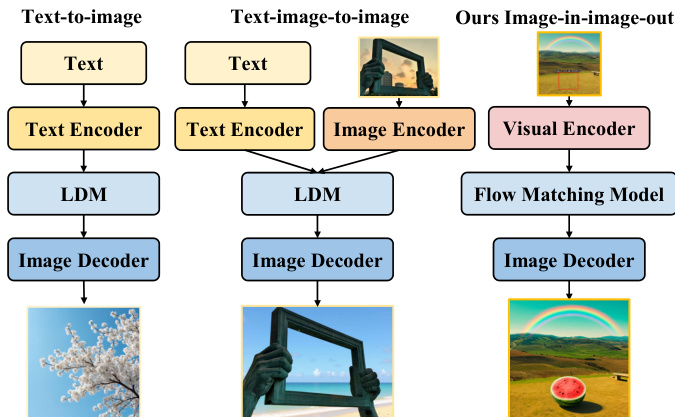
Multimodal generation currently relies on text-dominant pipelines where linguistic embeddings dictate visual output, creating a fundamental asymmetry where vision cannot reason or generate independently. These traditional architectures often suffer from cross-modal alignment bottlenecks and require complex, task-specific branches to handle different types of conditioning. The authors leverage a vision-centric approach called FlowInOne to reformulate multimodal generation as a pure image-in, image-out pipeline. By converting all inputs, including text and spatial layouts, into visual prompts and using a single flow matching model, they unify text-to-image generation, layout-guided editing, and visual instruction following into one continuous visual space.
Dataset
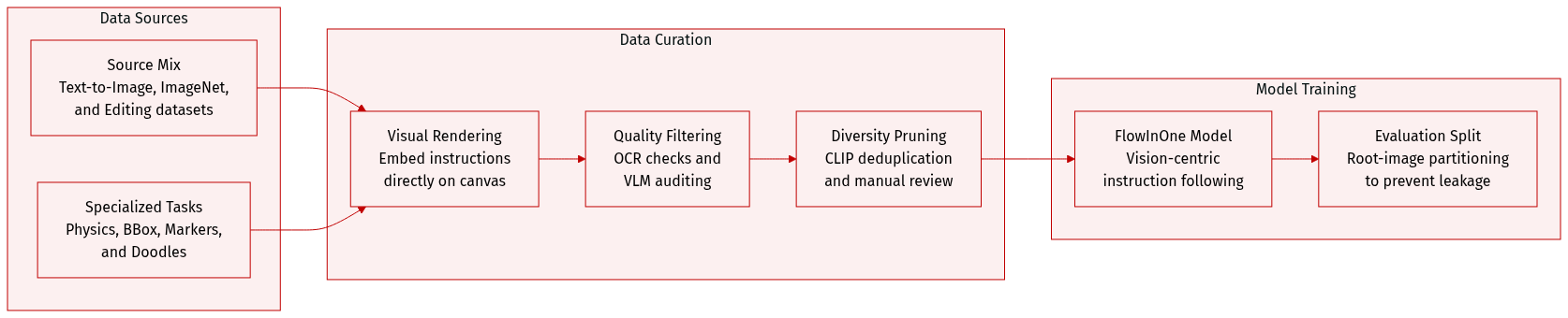
The authors developed VisPrompt-5M, a large-scale dataset of approximately 5 million image-to-image pairs designed to enable a unified vision-centric instruction-following paradigm. Instead of using separate text channels, the authors embed all instructions, such as text, bounding boxes, or arrows, directly onto the input image canvas.
Dataset Composition and Sources The dataset is organized into eight task categories grouped into three major capabilities:
- Fundamental Generation: Includes Text-to-Image (2M pairs from text-to-image-2M) and Class-to-Image (860K high-quality ImageNet subset) to establish basic semantic-to-visual mapping.
- Unified Image Editing: The largest component, covering semantic operations, attribute changes, and structural tasks. Sources include GPT-Image-Edit, Pico-Banana, UnicEdit (yielding 1.6M filtered semantic pairs), and PixWizard (315K structured pairs for tasks like inpainting and depth-to-image).
- Physics Understanding: A specialized subset for motion and dynamics, including Trajectory Understanding (1.5K Blender-rendered pairs) and Force Understanding (leveraging the Force Prompting dataset).
- Specialized Geometric Editing: Includes Text Bounding Box Editing (24K high-quality pairs synthesized via Qwen3-VL), Visual Marker Editing (250K pairs using arrow annotations), and Doodles Editing (1K high-fidelity pairs derived from web images).
Processing and Quality Control The authors implemented a rigorous multi-stage pipeline to ensure high data fidelity:
- Visual Instruction Rendering: For text-based tasks, instructions are rendered onto the canvas with randomized fonts, sizes, colors, and positions to prevent typographical overfitting.
- OCR-based Verification: An OCR engine checks the legibility of rendered text, discarding pairs with high Character Error Rates (CER).
- VLM-based Auditing: Advanced Multimodal Large Language Models (e.g., Qwen3-VL) act as judges to verify semantic alignment, spatial precision (e.g., checking if objects match bounding boxes), and visual realism.
- Diversity Deduplication: The authors use CLIP embeddings and cosine similarity thresholds to prune redundant concepts and prevent mode collapse.
- Manual Inspection: For highly complex tasks like Doodles Editing, the authors perform manual curation to ensure absolute structural alignment and the absence of generative artifacts.
Data Usage and Leakage Prevention The dataset is used to train the FlowInOne model under a purely vision-centric paradigm. To ensure the integrity of the VP-Bench evaluation, the authors implemented a strict two-fold leakage prevention protocol:
- Root-Image Partitioning: The dataset is split based on underlying unedited base images rather than individual instruction pairs, ensuring the model never sees the benchmark backgrounds or layouts.
- Visual Deduplication: The authors use CLIP embeddings to perform feature-level filtering, aggressively discarding any training pairs that exhibit high visual similarity to the benchmark images.
Method
The authors leverage a flow matching framework to model image generation as a continuous transport process within a shared latent space, eliminating the need for complex noise scheduling and explicit conditioning branches. The core of the approach is a unified visual encoding strategy that integrates textual instructions and diverse visual cues directly onto the image canvas, thereby preserving spatial layouts and structural priors without relying on cross-modal alignment modules. This unified image is processed by a SigLIP Vision Transformer to extract patch-level semantic features, which are then projected into the target embedding space via an MLP projector. The resulting fused representation, Xfuse, encapsulates both textual semantics and visual geometry.
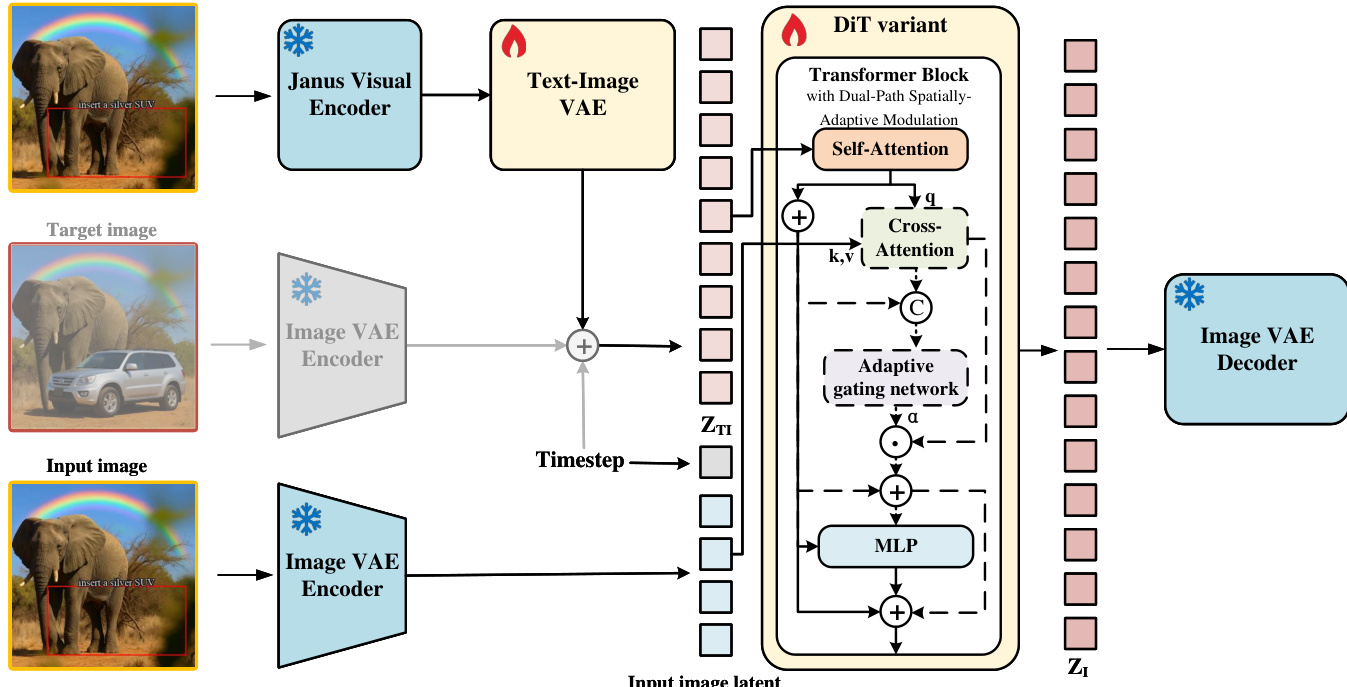
As shown in the figure below, the architecture employs a Dual-Path Spatially-Adaptive Modulation mechanism within a DiT variant to balance structural preservation and instruction adherence. The process begins with the input image and visual instruction being encoded into a shared latent space. The visual instruction is first processed by a Janus Visual Encoder and a Text-Image VAE, while the target and input images are encoded by a frozen Image VAE. These latent representations, ZTI and ZI, serve as the source and target distributions for the flow matching process.
During training, the model learns a time-dependent velocity field vθ(zt,t) by minimizing the Mean Squared Error (MSE) against the ground-truth velocity vt∗, which is derived from the linear interpolation zt=tz1+(1−(1−σmin)t)z0. Inference involves solving the Ordinary Differential Equation dtdzt=vθ(zt,t) from t=0 to t=1, deterministically evolving the visual instruction latent into the final target image.
The Dual-Path Spatially-Adaptive Modulation mechanism is designed to dynamically compensate for the missing structural manifold. For text-to-image generation, the model bypasses the cross-attention layer to prevent irrelevant noise, ensuring the generation trajectory strictly follows the text semantics. For image editing, a source image is mapped into the latent space, and a structural increment ΔHstruct is computed via cross-attention. A lightweight adaptive gating network predicts a token-level weight vector Λ, which controls the infiltration of the structural manifold. The final layer output is integrated via a conditional formulation, where the modulation term is activated only for editing tasks, effectively mitigating editing conflicts and reducing evolution error.
Experiment
The researchers evaluated FlowInOne using the curated VP-Bench benchmark, employing Vision-Language Models and human experts to assess instruction faithfulness, content consistency, visual realism, and spatial precision. Comparative experiments demonstrate that the model achieves state-of-the-art performance in the image-in, image-out paradigm, particularly excelling in fine-grained spatial control and physical reasoning compared to both open-source and commercial baselines. Ablation studies further confirm that joint training and spatially-adaptive modulation are critical for unifying diverse generation and editing tasks within a single framework.
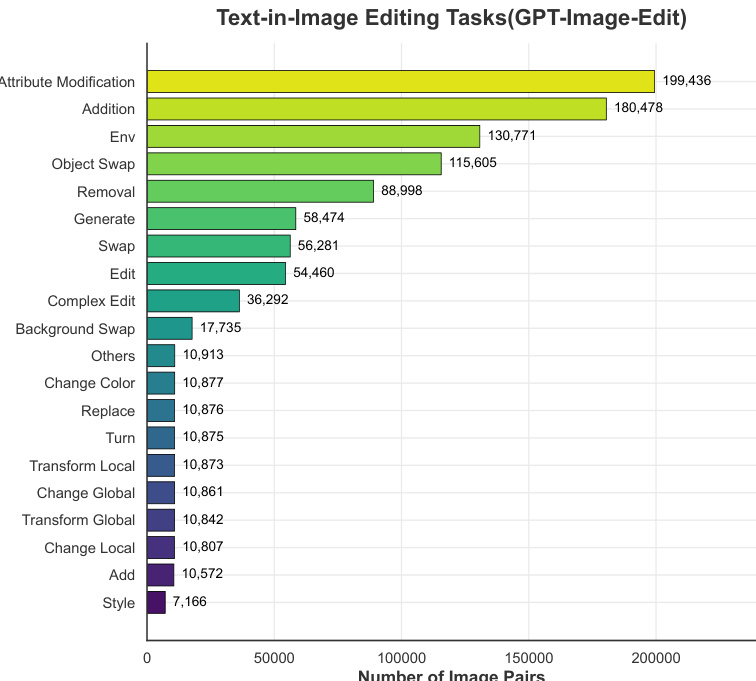
The bar chart shows the number of image pairs across various text-in-image editing tasks, with attribute modification and addition being the most frequent categories. The data indicates a significant imbalance, where a few task types dominate the dataset while others have considerably fewer instances. Attribute modification and addition are the most common text-in-image editing tasks. A majority of tasks have fewer than 20,000 image pairs. The dataset is highly imbalanced, with several categories having significantly fewer samples than others.
The the the table shows retention rates across different visual editing categories, with the primary rejection reasons and the corresponding VLM/OCR filtering methods used. The retention rate varies significantly by category, indicating differences in task difficulty and model performance. Retention rates differ across editing categories, with text-in-image editing showing the highest retention. Primary rejection reasons vary by category, including semantic inconsistency and geometric misalignment. Different VLM/OCR filtering methods are used for each category to assess specific failure modes.

The the the table outlines the composition of a benchmark dataset, detailing the primary sources and the number of initial and curated pairs for various task categories. The dataset covers fundamental generation and editing tasks, with the total size of the curated dataset being approximately 5.36 million pairs. The dataset includes diverse task categories such as text-to-image generation and various forms of image editing. Sources for the dataset range from large-scale text-to-image datasets to specialized collections for specific editing tasks. The total number of curated pairs across all categories is approximately 5.36 million.

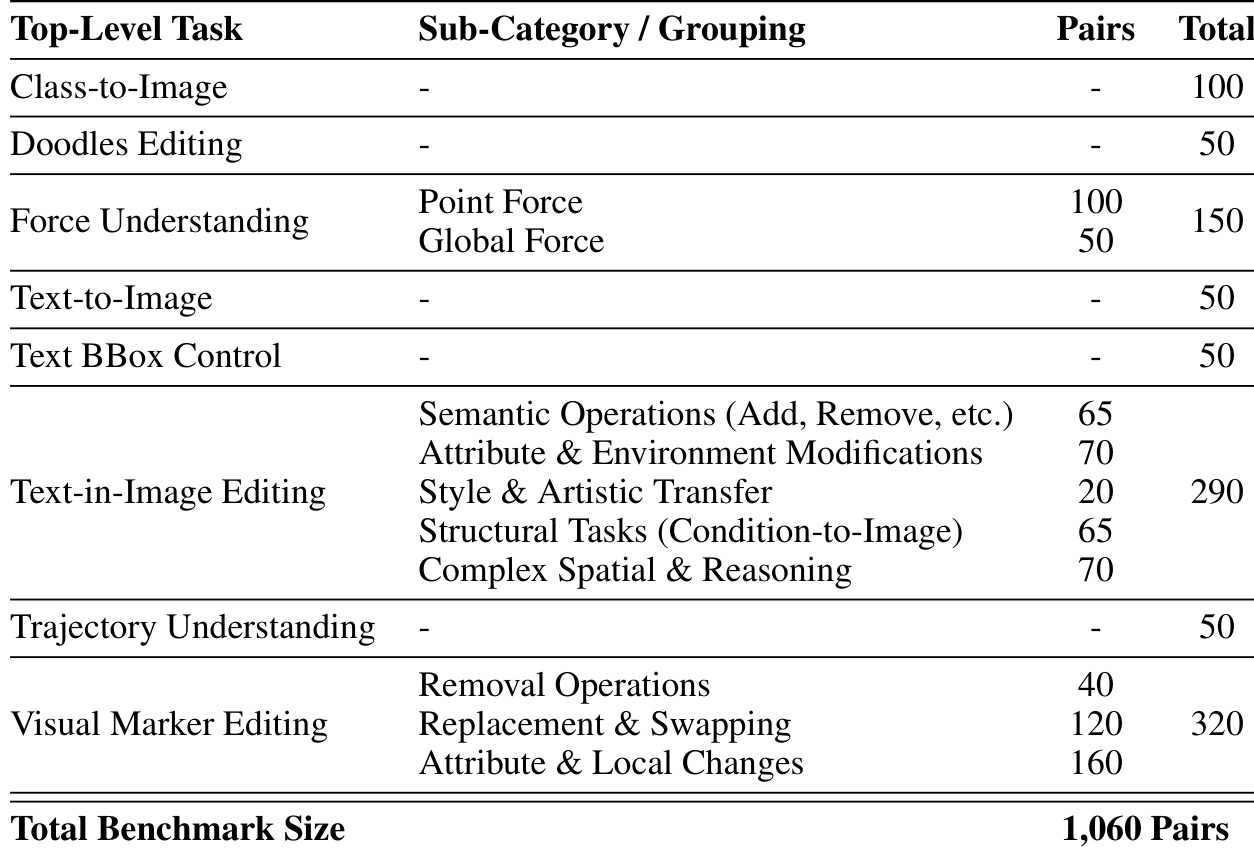
The the the table outlines the structure of the VP-Bench benchmark, detailing its top-level tasks and sub-categories with corresponding pair counts. It shows a diverse range of visual instruction tasks, including text-to-image, text-in-image editing, and spatial reasoning, with the total benchmark size comprising 1,060 pairs. The benchmark includes diverse visual instruction tasks such as text-to-image and text-in-image editing. Text-in-image editing is the largest category with 290 pairs, covering various sub-tasks. The total benchmark size is 1,060 pairs, with tasks distributed across different categories.
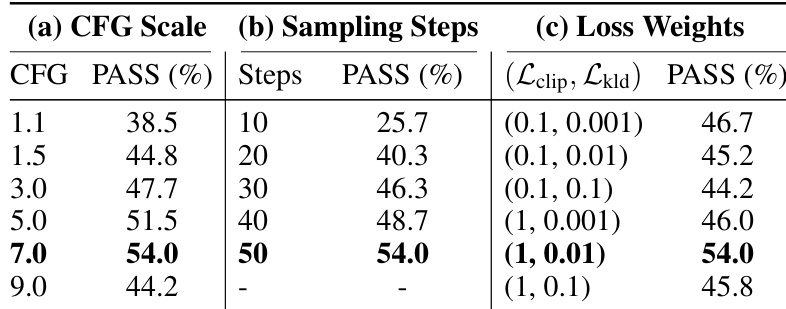
The study evaluates the impact of different hyperparameters on model performance, showing that optimal settings yield the highest pass rate. Performance varies significantly with changes in CFG scale, sampling steps, and loss weights, with specific configurations achieving peak results. Pass rate peaks at a CFG scale of 7 and 50 sampling steps. Performance declines with excessively high CFG scale or low sampling steps. Optimal loss weights balance CLIP alignment and KL divergence penalties.
The evaluation examines the composition and quality of the VP-Bench benchmark, alongside an ablation study to optimize model performance. The analysis reveals a highly imbalanced task distribution dominated by attribute modification and highlights that retention rates vary across editing categories due to specific semantic and geometric challenges. Furthermore, the hyperparameter study demonstrates that model success depends on finding a precise balance between sampling steps, CFG scale, and loss weights.