Command Palette
Search for a command to run...
OpenWorldLib: 고급 World Models를 위한 통합 Codebase 및 Definition
OpenWorldLib: 고급 World Models를 위한 통합 Codebase 및 Definition
초록
제시해주신 영어 텍스트를 요청하신 전문적인 기술 번역 기준에 따라 한국어로 번역한 결과입니다. (참고: 요청 사항에 '한국어로 답변해달라'고 하셨으나, 번역 대상이 영어이므로 최종 결과물은 한국어로 작성하였습니다.)[번역본]World model은 인공지능 분야에서 유망한 연구 방향으로서 상당한 주목을 받아왔으나, 아직 명확하고 통일된 정의는 부재한 실정입니다. 본 논문에서는 Advanced World Model을 위한 포괄적이고 표준화된 inference 프레임워크인 OpenWorldLib를 소개합니다. World model의 발전 과정을 바탕으로, 본 연구는 다음과 같은 명확한 정의를 제안합니다: "World model이란 복잡한 세상을 이해하고 예측하기 위해, perception을 중심으로 상호작용(interaction) 및 장기 기억(long-term memory) 능력을 갖춘 모델 또는 프레임워크를 의미한다." 나아가, 본 논문은 World model의 필수 역량을 체계적으로 분류합니다. 이러한 정의를 바탕으로, OpenWorldLib는 서로 다른 태스크를 수행하는 모델들을 하나의 통일된 프레임워크 내로 통합하여, 효율적인 재사용과 협업 inference를 가능하게 합니다. 마지막으로, World model 연구의 잠재적인 미래 방향에 대한 심도 있는 고찰과 분석을 제시합니다. Code link: https://github.com/OpenDCAI/OpenWorldLib
One-sentence Summary
Researchers from Peking University, Kuaishou Technology, and other institutions propose OpenWorldLib, a standardized inference framework that establishes a unified definition for advanced world models by integrating perception, interaction, and long-term memory capabilities across diverse tasks including interactive video generation, 3D generation, multimodal reasoning, and vision-language-action generation.
Key Contributions
- The paper establishes a formal definition for world models as perception-centered frameworks equipped with interaction and long-term memory capabilities for understanding and predicting complex environments.
- This work introduces OpenWorldLib, a standardized inference framework that integrates diverse models across multiple tasks to enable efficient reuse and collaborative inference.
- The framework provides unified interfaces for core tasks including interactive video generation, 3D scene reconstruction, audio generation, and Vision-Language-Action (VLA) reasoning to standardize multimodal inputs and interaction controls.
Introduction
As artificial intelligence transitions from virtual environments to real-world applications, world models have become essential for enabling agents to perceive, interact with, and understand physical dynamics. However, the field currently suffers from a lack of consensus, as researchers often use diverse and overlapping definitions that conflate general generative tasks, such as text-to-video, with true world modeling. To address this fragmentation, the authors propose a standardized definition of world models centered on perception, action-conditioned simulation, and long-term memory. They leverage this definition to introduce OpenWorldLib, a unified inference framework that integrates diverse capabilities including interactive video generation, 3D scene reconstruction, multimodal reasoning, and vision-language-action (VLA) models into a single, cohesive codebase.
Dataset
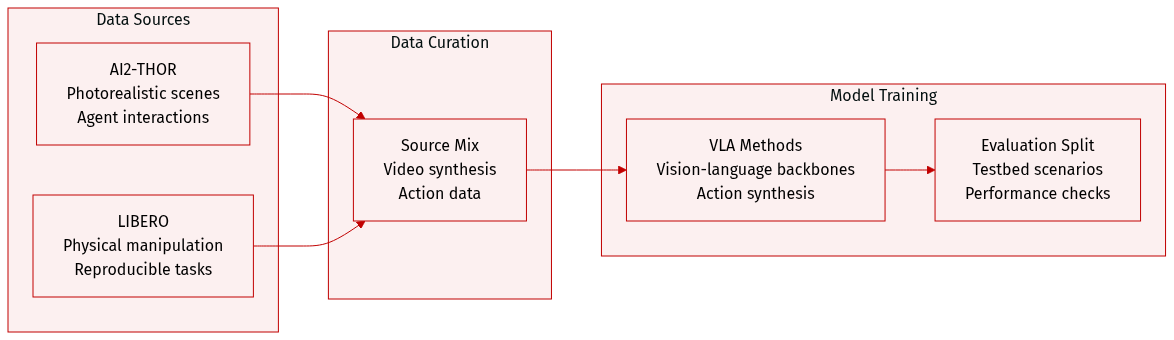
The authors utilize two distinct simulation-based paradigms within OpenWorldLib to evaluate world model performance across embodied video synthesis and action generation:
-
Dataset Composition and Sources
- AI2-THOR: Used for embodied video generation to facilitate photorealistic scene rendering and dynamic agent-environment interactions.
- LIBERO: Utilized for Vision-Language-Action (VLA) evaluation to provide physically grounded and reproducible manipulation environments.
-
Data Usage and Evaluation Framework
- The datasets serve as controllable testbeds to assess how well a world model couples semantic understanding with physical dynamics and fine-grained action planning.
- The framework evaluates a variety of VLA methods, including π0 and π0.5 (which use a PaliGemma backbone with MoE action heads) and LingBot-VA (which employs a video diffusion architecture for visual prediction and continuous action synthesis).
Method
The OpenWorldLib framework is designed to address the core requirements of a world model, including receiving complex physical inputs, understanding the environment, maintaining long-term memory, and supporting multimodal outputs. The framework is structured around a modular architecture that integrates distinct components to enable coherent and scalable world model interactions. As shown in the framework diagram, the system begins with an environment interactive signal, which is processed through a centralized pipeline to generate multimodal outputs.
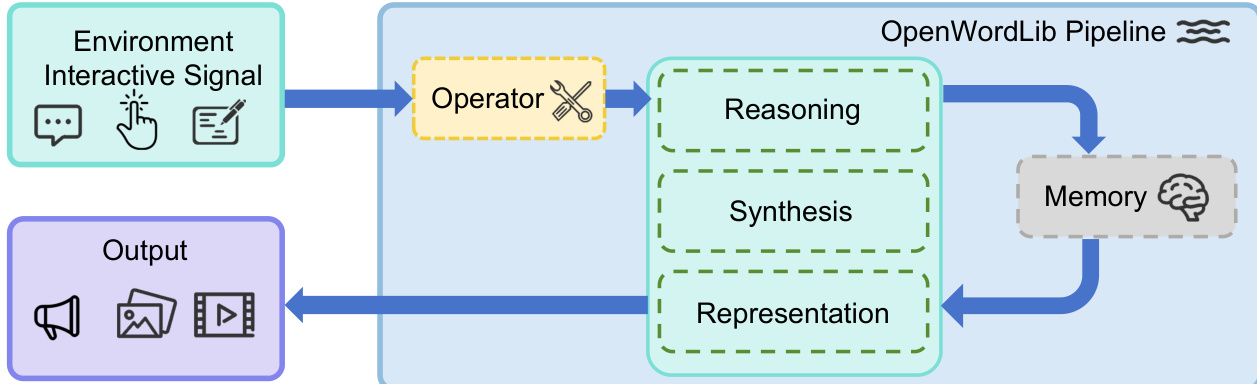
The Operator module serves as the initial interface between raw user or environmental inputs and the core processing modules. It standardizes diverse data streams—such as text prompts, images, continuous control actions, and audio signals—by performing two primary functions: validation and preprocessing. Validation ensures that input data conforms to the expected formats, shapes, and types, while preprocessing transforms raw signals into standardized tensor representations or structured formats. To support extensibility, a unified BaseOperator template is defined, ensuring consistent API integration across all task-specific operators.
The core processing logic is managed by the Pipeline module, which orchestrates the interaction between the Operator, Reasoning, Synthesis, Representation, and Memory modules. The Pipeline provides a unified entry point for both single-turn inference and multi-turn interactive execution. It receives raw inputs, routes them through the Operator for preprocessing, queries the Memory module for contextual history, coordinates the execution of Reasoning, Synthesis, and Representation modules, and returns structured outputs while updating the memory state. This design enables efficient data flow and decouples module implementations while maintaining reliable communication.
The Reasoning module enables the system to interpret multimodal inputs and generate grounded semantic interpretations. It is organized into three subcategories: general reasoning, spatial reasoning, and audio reasoning. General reasoning uses multimodal large language models to process text, images, audio, and video, while spatial reasoning specializes in 3D spatial understanding and object localization. Audio reasoning interprets auditory signals. A unified BaseReasoning template ensures consistent integration of new reasoning models into the framework.
The Synthesis module acts as the generative bridge between standardized conditioning and multimodal outputs, including visual, auditory, and embodied signals. It hosts heterogeneous generative backends that produce structured artifacts such as images, video frames, and audio waveforms. The visual synthesis layer generates raster outputs from structured conditioning like text prompts or reference images, supporting both local and cloud-based inference. The audio synthesis layer produces continuous waveforms conditioned on text, video features, and timing metadata, enabling rich auditory feedback. The other signal synthesis layer focuses on physical signal generation, particularly action control, mapping multimodal contexts into executable action sequences for embodied tasks.
The Representation module handles explicit representations such as 3D structures, separate from the implicit representations generated by Synthesis. It supports 3D reconstruction to produce outputs like point clouds, depth maps, and camera poses, and provides simulation support for testing predicted actions in a coordinate system. It also integrates with external physics engines via local or cloud-based APIs.
The Memory module serves as the persistent state center, storing multimodal interaction history—including text, visual features, action trajectories, and scene states—and enabling efficient context retrieval for multi-turn tasks. It manages historical storage, context retrieval, state updates, and session management, ensuring consistent reasoning and generation across interactions.

As shown in the figure below, the framework distinguishes between implicit and explicit representations. In the implicit representation pathway, the model processes interactive signals to generate outputs directly, while the explicit representation pathway involves a simulator that renders outputs based on structured representations. This dual approach allows the framework to support both learned dynamics and human-defined simulators, providing a comprehensive environment for world model testing and validation.
Experiment
The evaluation assesses the OpenWorldLib framework through tasks including interactive video generation, multimodal reasoning, 3D generation, and vision-language-action generation. Results indicate that while early navigation models struggle with color consistency over long horizons, more recent approaches achieve higher visual quality. Furthermore, the experiments demonstrate that while some models support basic interactivity, they often lack the physical consistency and realism found in advanced generative architectures.