Command Palette
Search for a command to run...
ACES: 누가 테스트를 테스트하는가? 코드 Generation을 위한 Leave-One-Out AUC Consistency
ACES: 누가 테스트를 테스트하는가? 코드 Generation을 위한 Leave-One-Out AUC Consistency
Hui Sun Yun-Ji Zhang Zheng Xie Ren-Biao Liu Yali Du Xin-Ye Li Ming Li
초록
제시해주신 영문 기술 텍스트를 전문적인 기술 논문 스타일의 한국어로 번역해 드립니다. (요청하신 지침에 따라 번역 결과물은 한국어로 작성되었습니다.)[번역문]LLM이 생성한 test를 사용하여 LLM이 생성한 code candidate를 선택하는 과정은 test 자체의 오류 가능성 때문에 매우 까다롭습니다. 기존 방식들은 모든 test를 동일하게 취급하거나, 신뢰할 수 없는 test를 필터링하기 위해 임시방편적인 heuristic에 의존해 왔습니다. 그러나 test의 정확성을 판별하려면 어떤 code가 정답인지 알아야 하므로, 이는 순환 의존성(circular dependency) 문제를 야기합니다. 본 연구의 핵심 통찰은 test의 정확성을 판단할 필요가 없다는 것입니다. 즉, test의 투표 결과는 단순한 빈도(count)가 아닌 순위(rank)를 매겨야 합니다. 중요한 것은 얼마나 많은 code가 특정 test를 통과하느냐가 아니라, 해당 test가 정답 code와 오답 code를 얼마나 잘 구분(distinguish)할 수 있느냐 하는 점입니다. 우리는 leave-one-out evaluation 방식을 통해 이 순환 의존성을 해결합니다. 구체적으로는 하나의 test를 제외한 후, 나머지 모든 test에서 얻은 집계 점수를 바탕으로 code의 순위를 매깁니다. 그 다음, 제외되었던 test의 pass/fail 패턴이 이 순위와 일치하는지를 측정합니다. 우리는 이러한 일치 정도를 leave-one-out AUC (LOO-AUC)로 공식화하였으며, 기대 LOO-AUC가 각 test가 정답 code와 오답 code를 분리해내는 능력에 비례함을 증명했습니다.이를 바탕으로, 우리는 두 가지 상호 보완적인 변형 모델을 가진 ACES (AUC Consistency Scoring)를 제안합니다. ACES-C는 평균적인 test 품질에 대한 완화된 가정이 충족될 경우, 기대치 측면에서 oracle을 근사할 수 있음이 증명된 closed-form weight를 제공합니다. ACES-O는 이러한 가정을 배제하고 미분 가능한 LOO-AUC 목적 함수를 반복적으로 최적화합니다. 두 방식 모두 추가적인 연산 오버헤드가 거의 없는 binary pass matrix만을 사용하여 작동하며, 여러 code generation benchmark에서 SOTA(state-of-the-art) Pass@k 성능을 달성했습니다.
One-sentence Summary
Researchers from Nanjing University propose ACES, a scoring framework that addresses the circular dependency in evaluating LLM-generated code tests by utilizing leave-one-out AUC consistency to measure a test's ability to distinguish correct from incorrect code through two variants that provide either closed-form weights or iteratively optimized weights.
Key Contributions
- The paper introduces the leave-one-out AUC (LOO-AUC) mechanism, a formal criterion that identifies informative tests by measuring how well a held-out test's pass/fail pattern agrees with the aggregate ranking of code candidates.
- This work presents ACES (AUC ConsistEncy Scoring), a method that utilizes the LOO-AUC to weight tests based on their ability to distinguish correct code from incorrect code using only a binary pass matrix.
- The research provides two complementary variants, ACES-C, which uses closed-form weights to approximate an oracle under average test quality, and ACES-O, which employs iterative optimization of a differentiable LOO-AUC objective for more challenging tasks.
Introduction
To improve the reliability of code generation, researchers often use test-time computation to select the best candidates from a pool of LLM-generated solutions using execution-based feedback. However, a circular dependency exists because selecting correct code requires reliable tests, yet determining if a test is reliable typically requires knowing which code is correct. Existing methods often treat all tests as equally valid or rely on expensive heuristics and reinforcement learning to filter unreliable tests. The authors address this by proposing ACES (AUC Consistency Scoring), a method that identifies informative tests based solely on their ability to rank code candidates. By leveraging a leave-one-out AUC (LOO-AUC) metric, the authors can measure how well a test distinguishes between different code candidates without needing ground truth labels, providing a principled way to weight tests based on their discriminative power.
Dataset

The authors utilize three primary benchmarks to evaluate and generate code solutions: HumanEval, HumanEval+, and MBPP.
- Dataset Composition and Sources: The evaluation relies on standard coding datasets, specifically HumanEval, its augmented version HumanEval+, and MBPP.
- Prompting Strategy: To ensure consistent candidate solution generation, the authors implement a specific instruction following the MPSC protocol. The prompt instructs the model to act as a Python programmer, requiring it to implement function bodies based on provided declarations and docstrings without modifying existing code or providing additional explanations.
- Data Processing: The generation process uses a structured template where the docstring is injected into a predefined Python code block to guide the model toward precise implementations.
Method
The authors frame code ranking as a weighted voting problem over the pass matrix, where the goal is to assign weights to tests such that the induced ranking of candidate solutions optimizes performance metrics like Pass@k. The core of the approach lies in leveraging the internal consistency of tests to estimate their discriminative power without external supervision. This is achieved through the Leave-One-Out AUC (LOO-AUC) identity, which establishes a direct relationship between the observed consistency of a test with the ranking induced by the remaining tests and its latent discriminative power.
The framework begins by considering a programming problem for which an LLM generates n candidate solutions C={c1,…,cn} and m test cases T={t1,…,tm}. The execution results form a binary pass matrix B∈{0,1}n×m, where Bij=1 indicates that code ci passes test tj. The objective is to rank these codes based on their scores si(w)=∑j=1mwjBij, where w∈Δm is a weight vector over the tests. The authors show that this ranking is equivalent to a weighted voting problem, where each test tj casts a vote hj=Bc+,j−Bc−,j on a correct code c+ versus an incorrect code c−, and the score difference is the weighted sum of these votes.
To evaluate the quality of a test, the authors introduce the LOO-AUC metric. For a test tj, the LOO-AUC measures how well its pass/fail pattern agrees with the ranking produced by the scores from all other tests. This is formally defined as LOO−AUCj(w)=AUC(S(−j),B:,j), where S(−j) is the vector of scores computed by excluding test tj and B:,j is the vector of pass/fail outcomes for tj. The LOO-AUC identity (Theorem 3) proves that the expected value of this metric, minus 1/2, is proportional to the test's discriminative power δj=αj−βj, where αj and βj are the conditional pass rates for correct and incorrect codes, respectively. This identity is the theoretical foundation for the ACES method.
The ACES framework consists of two complementary methods for estimating these test weights. The first, ACES-C, is a closed-form, data-driven weighting scheme. It leverages the LOO-AUC identity to construct a quality score for each test. Under the assumption that the average discriminative power is positive and the test pool is large, the authors show that the leave-one-out ranking quality A(−j)(wunif)−1/2 is approximately constant across all tests. This allows them to derive a weight wj=max(0,LOO−AUCj(wunif)−1/2)⋅pj(1−pj), where pj is the empirical pass rate of test tj. This formulation effectively corrects for the bias introduced by the variance in pass rates, ensuring that tests with high consistency with the ranking are up-weighted, while those with low consistency (misleading tests) are down-weighted to zero. The second method, ACES-O, takes an optimization-based approach. It directly maximizes an objective function J(w)=∑j=1mwj(LOO−AUCj(w)−1/2), which is designed to increase the contribution of informative tests and decrease that of misleading ones. This optimization is performed via gradient ascent on a smooth logistic surrogate of the non-differentiable AUC, with weights parameterized via a softmax to ensure they remain in the simplex Δm. The optimization process benefits from a positive feedback loop, as improving the weights enhances the leave-one-out ranking, which in turn improves the LOO-AUC estimates and further refines the weights.
Experiment
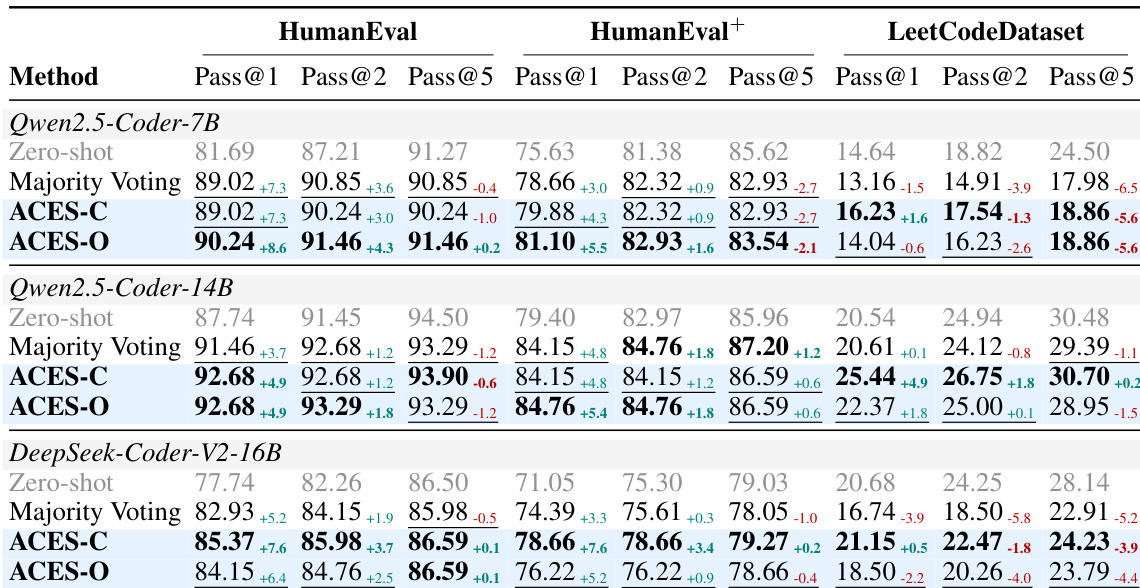
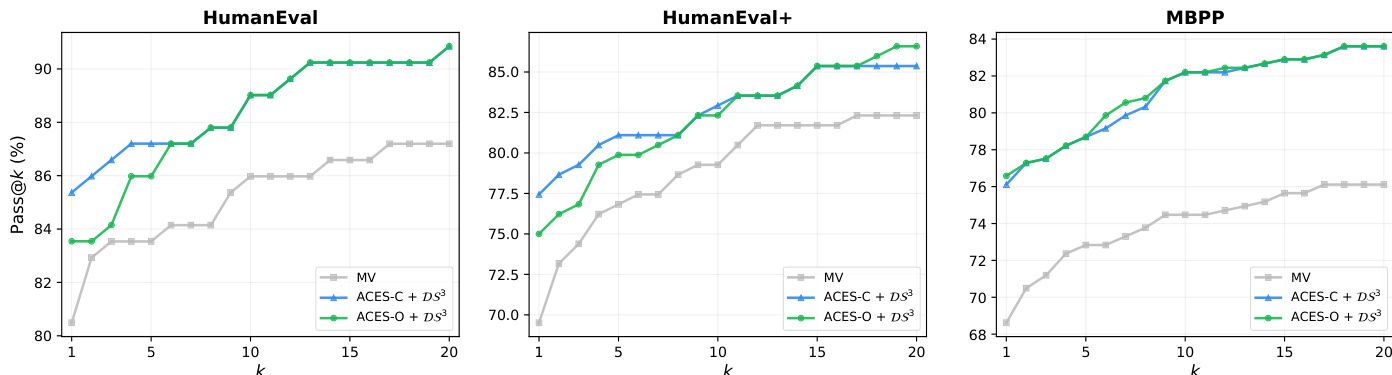
The proposed ACES methods are evaluated on HumanEval, HumanEval+, and MBPP benchmarks to validate their ability to distinguish informative from misleading tests using only a binary pass matrix. Results demonstrate that ACES-O serves as a superior standalone reranker, while ACES-C excels when integrated with static-analysis pre-filtering. Overall, the experiments confirm that principled test weighting significantly improves ranking quality, particularly in challenging scenarios where misleading tests are prevalent.
The authors evaluate ACES-C and ACES-O on code generation benchmarks, showing that both methods improve Pass@k performance over baselines using only the binary pass matrix. ACES-O achieves the best results among execution-only methods, while ACES-C excels when combined with pre-filtering, demonstrating complementary strengths. ACES-O achieves the best Pass@k among execution-only methods on all benchmarks ACES-C performs best when combined with pre-filtering, surpassing even methods using additional static signals The two ACES variants show complementary strengths, with ACES-O excelling in low-quality test regimes and ACES-C in high-quality ones
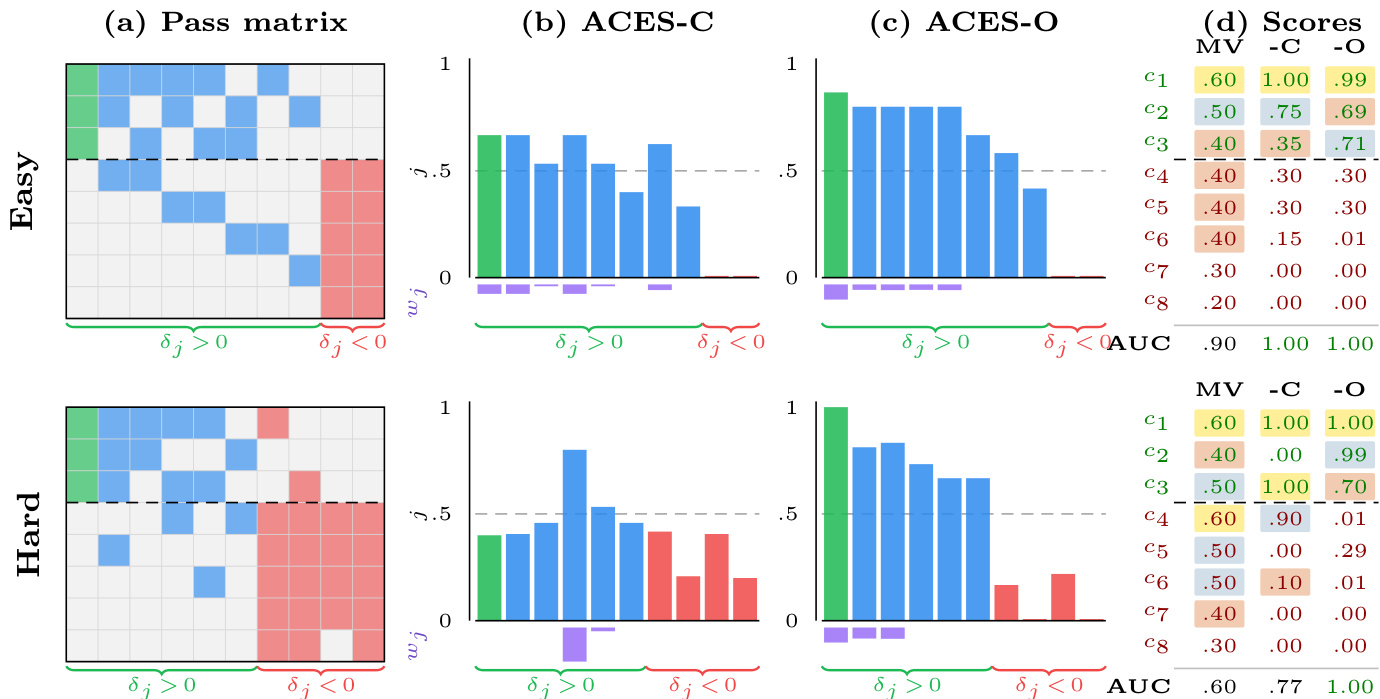
The authors analyze test weighting methods on binary pass matrices, showing how ACES-C and ACES-O improve ranking by identifying informative tests. In easy cases, uniform weighting is sufficient, but in hard cases with misleading tests, iterative optimization is essential for perfect ranking. ACES-C uses closed-form weights to improve ranking by focusing on informative tests ACES-O iteratively refines weights to recover informative tests when misleading tests are prevalent The methods show complementary strengths: ACES-C excels when the assumption holds, while ACES-O is more effective when it does not
The authors compare ACES variants with baselines on three code generation benchmarks, showing that ACES-O achieves the best Pass@k among execution-only methods, while ACES-C performs well when combined with static analysis. The results demonstrate that both methods improve over Majority Voting, with ACES-O providing greater gains when misleading tests are prevalent. ACES-O outperforms all execution-only methods on all benchmarks ACES-C excels when combined with static analysis Both ACES variants improve over Majority Voting, especially on harder benchmarks
The authors evaluate ACES-C and ACES-O on code generation benchmarks, showing that ACES variants outperform baselines using only the binary pass matrix. ACES-C improves over majority voting, and ACES-O achieves the best results among execution-only methods across all benchmarks. ACES variants surpass majority voting and other post-hoc methods using only the pass matrix. ACES-O achieves the best performance among execution-only methods on all benchmarks. ACES-C improves over majority voting, demonstrating the value of LOO-AUC-based weighting.
The authors evaluate ACES methods on code generation benchmarks, showing that ACES-O achieves the best Pass@k among execution-only methods across all benchmarks. When combined with static analysis, ACES improves over existing methods, with ACES-C performing better in regimes where the assumption of test quality is well satisfied. ACES-O leads all execution-only methods on all benchmarks, achieving the highest Pass@1 scores. Combining ACES with static analysis improves performance across all benchmarks, with ACES-C showing stronger gains when pre-filtering enhances test quality. ACES-C and ACES-O exhibit complementary strengths: ACES-C is robust with limited data, while ACES-O benefits from larger candidate pools and iterative refinement.
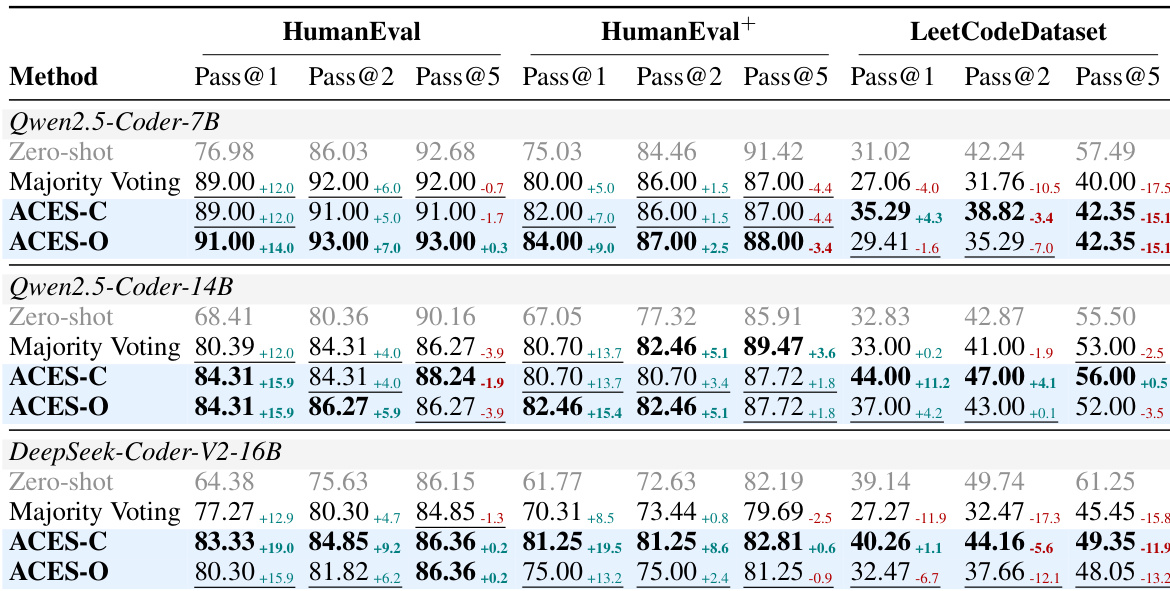
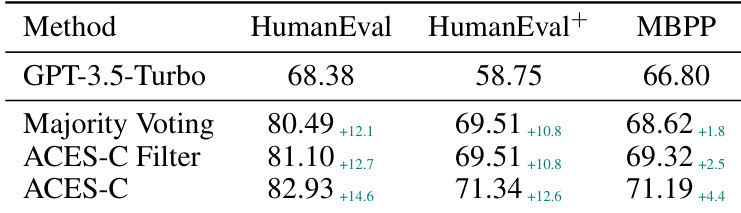
The authors evaluate the ACES-C and ACES-O methods on various code generation benchmarks to validate their ability to improve Pass@k performance using binary pass matrices. The experiments demonstrate that both variants outperform majority voting and other execution-only baselines by identifying more informative tests through specialized weighting schemes. While ACES-O excels in difficult scenarios containing misleading tests through iterative refinement, ACES-C shows superior performance when combined with static analysis or pre-filtering to enhance test quality.