Command Palette
Search for a command to run...
Token Warping 이 MLLMs 로 하여금 근접한 관점에서 관찰하도록 돕습니다
Token Warping 이 MLLMs 로 하여금 근접한 관점에서 관찰하도록 돕습니다
Phillip Y. Lee Chanho Park Mingue Park Seungwoo Yoo Juil Koo Minhyuk Sung
초록
멀티모달 대규모 언어 모델 (MLLM) 이 픽셀이 아닌 토큰을 왜곡 (warping) 하면 인근 시점에서 장면이 어떻게 보이는지 이해하는 데 도움이 될까요? MLLM 은 시각적 추론에서 우수한 성능을 보이지만, 시점 변화에 여전히 취약합니다. 이는 픽셀 단위 왜곡이 작은 깊이 오차에 매우 민감하며 종종 기하학적 왜곡을 유발하기 때문입니다. 인간 시점 변환의 기초가 부분 수준의 구조적 표현이라는 정신적 이미지 (mental imagery) 이론에 착안하여, ViT 기반 MLLM 의 이미지 토큰이 시점 변화에 효과적인 기반 (substrate) 으로 기능하는지 검토하였습니다. 순방향 및 역방향 왜곡을 비교한 결과, 대상 뷰에 조밀한 그리드를 정의하고 각 그리드 포인트에 해당하는 원본 뷰 토큰을 검색하는 역방향 토큰 왜곡 (backward token warping) 이 시점 이동 하에서 더 큰 안정성을 확보하고 의미적 일관성 (semantic coherence) 을 더 잘 보존하는 것으로 나타났습니다. 제안한 ViewBench 벤치마크에 대한 실험 결과, 토큰 수준 왜곡은 MLLM 이 인근 시점에서 신뢰할 수 있게 추론할 수 있게 하여, 픽셀 단위 왜곡 접근법, 공간적으로 파인튜닝된 MLLM, 생성적 왜곡 방법을 포함한 모든 베이스라인을 일관되게 능가함을 입증했습니다.
One-sentence Summary
Researchers from KAIST propose backward token warping, a technique that enables multimodal large language models to reason about nearby viewpoints by retrieving source tokens instead of warping pixels. This approach avoids geometric distortions and outperforms existing baselines on the new ViewBench benchmark.
Key Contributions
- The paper introduces backward token warping as a method to transform image tokens for viewpoint changes, which defines a dense grid on the target view and retrieves corresponding source-view tokens to maintain stability and semantic coherence.
- This work presents ViewBench, a new benchmark designed to evaluate multimodal large language models on spatial reasoning tasks involving viewpoint shifts, providing a standardized framework for assessing performance in this domain.
- Experiments demonstrate that the proposed token-level warping approach consistently outperforms pixel-wise warping, spatially fine-tuned models, and generative warping methods while requiring minimal inference-time computation.
Introduction
Multimodal Large Language Models (MLLMs) are critical for spatial reasoning in autonomous agents, yet they struggle to understand how a scene appears from a nearby viewpoint. Prior approaches relying on pixel-wise warping are highly sensitive to depth estimation errors, often introducing severe geometric distortions that degrade semantic coherence, while object-centric methods fail to capture fine-grained spatial details. To address these challenges, the authors propose token warping, a technique that transforms image tokens rather than pixels to simulate viewpoint shifts. They demonstrate that backward token warping, which retrieves source-view tokens for a dense target grid, provides a robust and computationally efficient substrate for viewpoint transformation that outperforms existing fine-tuned models and generative warping baselines.
Dataset
-
Dataset Composition and Sources: The authors construct ViewBench using real-world indoor scans from ScanNet, which provides dense RGB-D frames, ground-truth depth, camera poses, and intrinsics. They leverage the MultiSPA data engine to sample image pairs from adjacent viewpoints with controlled overlapping fields of view.
-
Key Details for Each Subset: The benchmark is divided into three subsets based on task type and annotation style, all filtered to ensure questions rely only on regions visible in both source and target views:
- ViewBench-Text: Contains 571 samples where two co-visible points are annotated with alphabet labels (A/B) to test binary left-right spatial reasoning.
- ViewBench-Shape: Includes 744 samples using simple geometric symbols (e.g., triangles, stars) for similar spatial reasoning tasks.
- ViewBench-Object: Comprises 300 samples where a red circular marker indicates a specific location for open-ended object description tasks.
-
Data Usage and Processing: The authors use these subsets to evaluate MLLMs on two primary tasks: view-conditioned spatial reasoning and target-view object description. They filter pairs to maintain an overlap ratio between 5% and 35% to ensure views are neither identical nor disjoint, and they specifically select point pairs where the left-right spatial relationship flips between the source and target viewpoints.
-
Cropping, Metadata, and Construction Strategy: The construction pipeline involves computing the Intersection over Union (IoU) of visible 3D point sets to determine overlap ratios and binning pairs to mitigate long-tail distribution biases. For point annotation, the authors project 3D world points into both camera frames to verify co-visibility and ensure sufficient pixel separation (at least 50 pixels) in the target view. They render specific visual markers (text, shapes, or red circles) onto the source images and generate instructions that describe the relative pose change, requiring the model to simulate the target viewpoint to answer correctly.
Method
The authors introduce a framework for enabling Multi-Modal Large Language Models (MLLMs) to perform spatial reasoning under viewpoint changes by utilizing image tokens as the primary unit for geometric transformation. This approach, known as Token Warping, allows the model to simulate mental imagery by transforming visual representations from a source viewpoint to a target viewpoint.
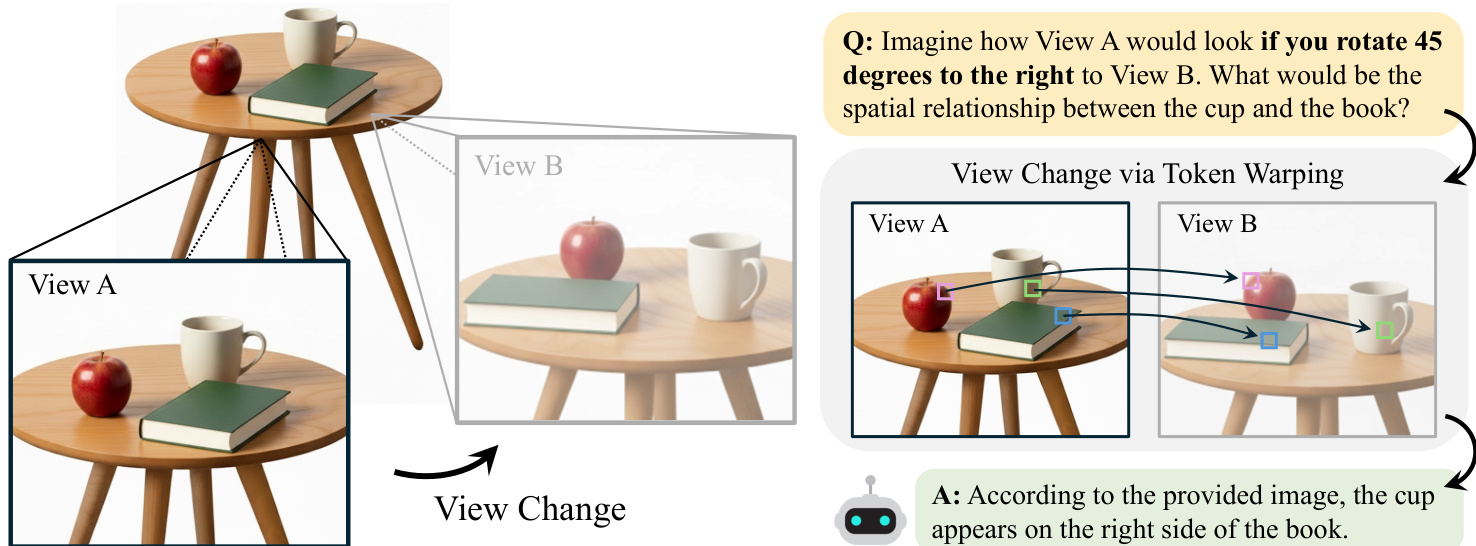
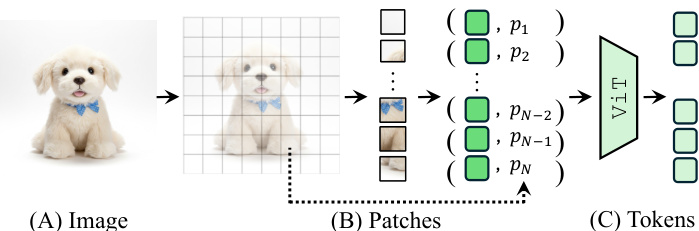
Image Tokenization The foundation of this method lies in how images are represented within ViT-based MLLMs. An input image I is partitioned into a fixed grid of non-overlapping patches. Each patch is processed by a shallow encoder and a vision encoder (e.g., ViT) to produce a sequence of image tokens. These tokens function as perceptual atoms, encoding both semantic content and positional information at the patch level.
The authors posit that these tokens provide an optimal granularity for viewpoint transformation. Object-level representations are too coarse and sacrifice spatial details, while pixel-level representations are too sensitive to geometric noise. Image tokens retain rich visual detail while remaining robust to local perturbations introduced during warping.
Warping Strategy To transform the scene to a new viewpoint, the system must map tokens from the source image to the target view. The authors compare pixel-wise warping with token warping. Pixel-wise warping retrieves individual pixels for target coordinates, but the subsequent patchification of the warped image often introduces local distortions that confuse the MLLM. In contrast, token warping retrieves intact tokens from the source view, preserving semantic consistency.
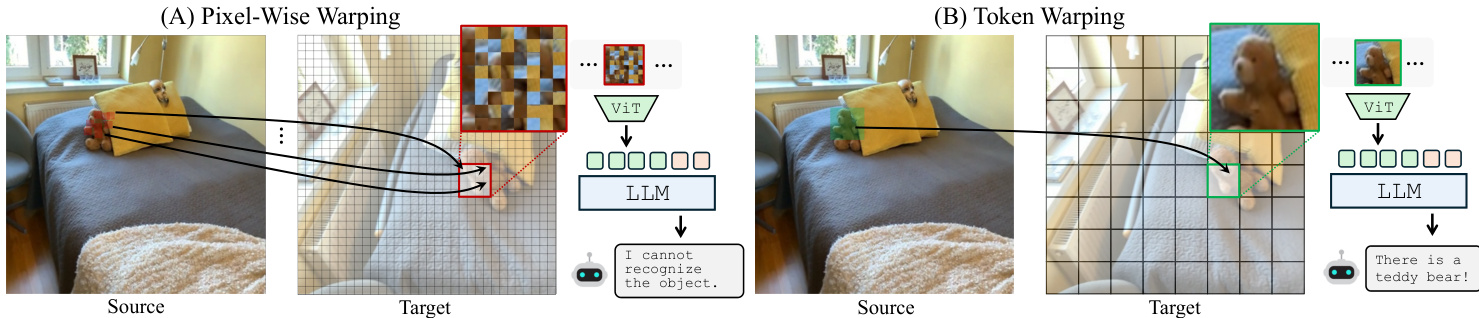
The implementation primarily uses backward warping. Instead of projecting source tokens forward (which can result in sparse, irregular distributions), the system defines a dense, regular grid in the target view and fetches corresponding tokens from the source image via a target-to-source mapping fT→S. This ensures the input to the MLLM remains a dense, regular grid, consistent with its training distribution.
Token Fetching Mechanisms A critical design choice involves how to fetch tokens from the source image at the mapped coordinates, which often fall between the original grid centers. The authors explore two strategies: Nearest Fetching and Adaptive Fetching.
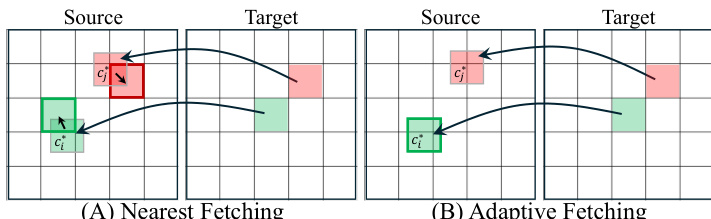
In Nearest Fetching, the system selects the existing source patch whose center is closest to the mapped coordinate in Euclidean distance. This approach is efficient as it reuses the original fixed-grid patchification. Adaptive Fetching involves re-patchifying the source image to crop patches centered exactly at the mapped coordinates. While Adaptive Fetching is more precise, experiments indicate that Nearest Fetching performs comparably, making it a practical and efficient choice.
View-Conditioned Reasoning The method is applied to tasks requiring the model to infer spatial relationships or describe objects from a novel perspective. The model receives a source image and a question about the scene as it would appear from a target viewpoint.

This setup evaluates the model's ability to handle view changes robustly, such as determining if an object is to the left or right of another from a different angle, or describing object properties visible in the warped target view. By leveraging token warping, the system effectively transfers perceptual information across viewpoints without the degradation associated with pixel-level manipulation.
Experiment
- A position noise sensitivity test demonstrates that MLLM token representations are highly robust to positional perturbations, significantly outperforming pixel-based baselines and validating tokens as stable units for simulating viewpoint changes.
- Experiments on ViewBench for view-conditioned spatial reasoning and target-view object description show that backward token warping consistently outperforms forward token warping, pixel-wise warping, and specialized MLLMs fine-tuned for spatial tasks.
- Qualitative analysis reveals that pixel-wise warping introduces severe visual artifacts and hallucinations, whereas token warping preserves local semantics and coherent structures, enabling accurate reasoning even under extreme viewpoint shifts and occlusion.
- Robustness evaluations confirm that the performance advantages of token warping persist when using estimated geometry from off-the-shelf depth and pose models rather than ground-truth data.
- A geometry-based oracle analysis verifies that the underlying warping pipeline is highly accurate, indicating that remaining performance gaps are due to MLLM perception limits rather than geometric errors.