Command Palette
Search for a command to run...
GrandCode: Agentic Reinforcement Learning을 통해 Competitive Programming에서 Grandmaster 레벨 달성하기
GrandCode: Agentic Reinforcement Learning을 통해 Competitive Programming에서 Grandmaster 레벨 달성하기
DeepReinforce Team Xiaoya Li Xiaofei Sun Guoyin Wang Songqiao Su Chris Shum Jiwei Li
초록
제시해주신 영문 텍스트를 전문적인 기술 번역 기준에 따라 한국어로 번역하였습니다. (요청하신 지침에 따라 한국어로 답변을 작성하였습니다.)[번역문]Competitive programming은 AI에 대항하여 인간이 실력을 유지하고 있는 몇 안 되는 최후의 보루 중 하나로 남아 있습니다. 현재까지 가장 뛰어난 AI 시스템조차 최정상급 인간 Competitive programming 능력에는 미치지 못하고 있습니다. 가장 최근의 최고 성적인 Google의 Gemini3 Deep Think는 실시간 대회 조건에서 평가되지 않았음에도 불구하고 8위를 기록했습니다.본 연구에서는 Competitive programming을 위해 설계된 multi-agent RL 시스템인 GrandCode를 소개합니다. GrandCode의 탁월한 능력은 두 가지 핵심 요소에 기인합니다. (1) 다양한 agentic 모듈(hypothesis proposal, solver, test generator, summarization 등)을 조율하며, post-training 및 online test-time RL을 통해 이들을 공동으로 개선합니다. (2) agentic RL에서 흔히 발생하는 지연된 보상(delayed rewards)과 심각한 off-policy drift 문제를 해결하기 위해, 다단계 agent rollouts에 특화된 Agentic GRPO를 도입했습니다.GrandCode는 실시간 Competitive programming 대회에서 모든 인간 참가자를 지속적으로 압도한 최초의 AI 시스템입니다. 가장 최근의 세 차례 Codeforces 실시간 대회, 즉 Round1087 (2026년 3월 21일), Round1088 (2026년 3월 28일), 그리고 Round1089 (2026년 3월 29일)에서 GrandCode는 전설적인 grandmaster들을 포함한 모든 인간 참가자를 제치고 모두 1위를 차지했습니다. GrandCode는 AI 시스템이 가장 경쟁적인 코딩 과제에서 최정상급 인간 프로그래머를 능가하는 단계에 도달했음을 보여줍니다.
One-sentence Summary
The DeepReinforce Team introduces GrandCode, a multi-agent reinforcement learning system that orchestrates specialized agentic modules and utilizes a novel Agentic GRPO method to address multi-stage rollouts and delayed rewards, ultimately becoming the first AI system to consistently place first and outperform human grandmasters in live Codeforces competitions.
Key Contributions
- The paper introduces GrandCode, a multi-agent reinforcement learning system that orchestrates various agentic modules such as hypothesis proposal, solvers, and test generators through post-training and online test-time reinforcement learning.
- This work presents Agentic GRPO, a specialized variant of Group Relative Policy Optimization that utilizes a delayed correction mechanism to address off-policy drift and improve credit assignment during multi-stage agent rollouts.
- Results demonstrate that GrandCode is the first AI system to consistently outperform human participants in live competitive programming, securing first place in three consecutive Codeforces rounds in March 2026.
Introduction
Competitive programming serves as a critical benchmark for evaluating the reasoning and coding capabilities of artificial intelligence. While recent large language models have made significant strides, existing systems still struggle to match the performance of elite human programmers, particularly under live, real-time contest conditions. Previous approaches often face challenges with multi-stage reasoning and the severe off-policy drift that occurs during complex, multi-turn agentic rollouts. To address these issues, the authors introduce GrandCode, a multi-agent reinforcement learning system that orchestrates specialized modules for hypothesis proposal, solving, and test case generation. The authors leverage a novel optimization method called Agentic GRPO, which utilizes a delayed correction mechanism to improve credit assignment during long agentic loops. This system represents the first AI to consistently achieve first place in live Codeforces competitions, surpassing even legendary human grandmasters.
Dataset
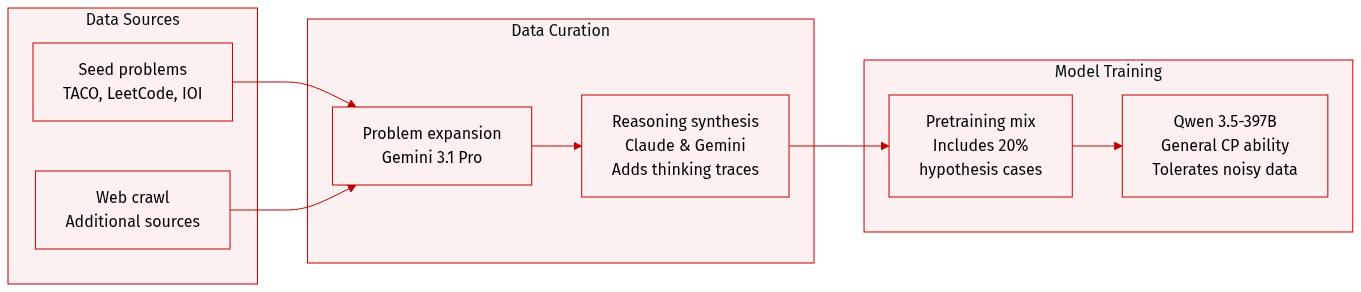
Dataset Overview
The authors construct a large scale training corpus for competitive programming through a multi stage synthesis approach:
-
Dataset Composition and Sources
- The process begins with a seed set of competitive programming problems sourced from TACO, LeetCode, USACO, CodeContests, and IOI, supplemented by additional web crawled data.
- This seed set is expanded into a much larger and more diverse corpus using Gemini 3.1 Pro.
-
Data Processing and Metadata Construction
- To facilitate reasoning training, the authors use Claude 4.6 and Gemini 3.1 to generate detailed thinking processes for the problems.
- This results in a structured dataset composed of question, thinking, and solution tuples.
- To prepare the model for hypothesis driven settings, 20% of the continued pretraining examples are randomly converted into hypothesis conditioned cases. In these instances, a hypothesis generated by a specific policy is incorporated into the prompt before the reasoning trace is generated.
-
Training Usage and Strategy
- The synthesized data is used for continued pretraining of the Qwen 3.5-397B model.
- The authors adopt a strategy of training on noisy data during this stage, acknowledging that some synthesized reasoning traces or answers may be incorrect.
- The primary goal of this phase is to enhance general competitive programming capabilities rather than providing precise supervision, with fine grained filtering and high quality supervision reserved for the subsequent Supervised Fine Tuning (SFT) stage.
Method
The system employs a multi-component architecture designed for competitive programming problem solving, integrating a primary solver with auxiliary modules for hypothesis generation, summarization, and test-case creation. The overall framework, illustrated in the first diagram, consists of two main phases: post-training and test-time solving. During post-training, the model undergoes continued pre-training on noisy competitive programming data, followed by supervised fine-tuning (SFT) on high-quality (question, thinking, solution) triples. This SFT stage trains the main solver πmain, the hypothesis model πhypothesis, and the summarization model πsummary independently. The final phase is multi-component reinforcement learning (RL), where these components are jointly optimized to improve collaboration under the final objective. At test time, the model leverages difficulty-aware routing to determine the appropriate strategy: for easy problems, it uses direct generation, while for harder problems, it engages in a test-time RL loop.
The core of the system's reasoning is guided by the hypothesis generation and verification module. As shown in the second diagram, the process begins with the model proposing an intermediate hypothesis, such as a compact mathematical characterization of the problem. This hypothesis is then validated by generating small random instances and comparing the hypothesized result against the exact solution computed by a brute-force solver. A mismatch triggers a hypothesis revision loop. This stage can also utilize symbolic tools, such as Wolfram Alpha, to simplify or solve expressions when the problem can be translated into a symbolic form. Hypotheses that survive this iterative validation are promoted to guide the main solution synthesis process.
To manage the computational cost of long reasoning traces, the system employs a separate summarization model πsummary. This model is trained to progressively compress long thinking traces into a compact state that retains the necessary information for downstream solving. The training process involves two stages: first, each local summarization step is optimized with RL using a reward that encourages the summary to preserve information needed for the remaining trace and final answer. Second, the full progressive chain is trained end-to-end using the final answer likelihood as the terminal reward. This modular training approach provides denser intermediate supervision and ensures the summarizer is well-optimized before being integrated into the full system.

The system also incorporates adversarial test-case generation to improve robustness. This is achieved through two strategies: difference-driven test generation, which generates inputs that expose behavioral differences between multiple candidate solutions, and solution attack, which directly compares a candidate solution to a gold solution to identify bugs and generate adversarial cases. These generated tests are used to fine-tune a model to produce such adversarial examples on demand.
During test-time solving, the model uses a difficulty-based classifier to route problems. For easy problems, it performs direct generation and evaluation. For harder problems, it enters a test-time RL loop. This loop involves generating candidate solutions, evaluating them with a set of adversarial tests, and using the verification feedback to update the policy via LoRA, a lightweight adaptation method. The loop also maintains a global summary of the search history, which helps guide the exploration. The overall architecture is designed for efficiency, with the main MoE solver policy running on a dedicated distributed GPU mesh, while the smaller auxiliary policies run asynchronously on separate GPU pools, and code execution handled by a CPU sandbox.
Experiment
The evaluation assesses GrandCode through live Codeforces competitions, real-world problem solving, and various training stages including continued training, supervised fine-tuning, and reinforcement learning. Results demonstrate that the system achieves top-tier competitive performance, even outperforming elite human contestants in live contests. Furthermore, the experiments show that while offline reinforcement learning significantly boosts core problem-solving abilities, test-time reinforcement learning is particularly effective at solving the most difficult challenges.
The authors evaluate test case generation on real Codeforces problems, showing improvements through iterative refinement. The pass rate increases with each stage of test suite enhancement, ultimately achieving full coverage. Pass rate improves from 42 to 48 after difference-driven test case generation and solution attack Further refinement using submission feedback and online generation increases pass rate to 50 All 50 test cases are passed after iterative test suite refinement

The authors evaluate the impact of different training stages on model performance using a benchmark of 100 problems. Results show that continued training and supervised fine-tuning improve accept rate and weighted scores, while adding a summarization module leads to a slight decrease in performance. Continued training increases accept rate and weighted score compared to the base model Supervised fine-tuning further improves performance on both accept rate and difficulty-weighted score Incorporating summarization causes a minor performance drop despite higher accept rate

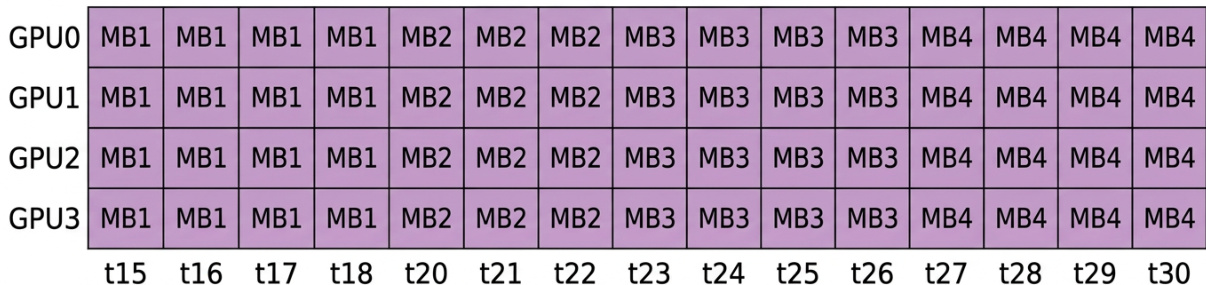
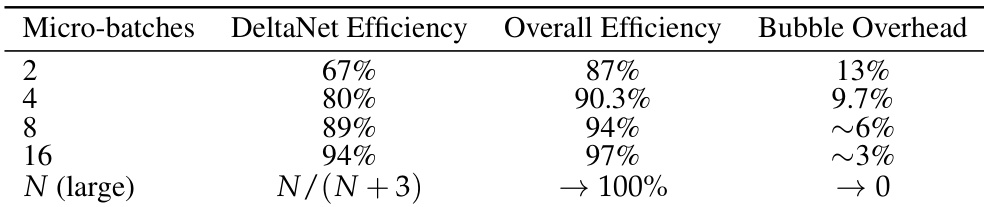
The the the table compares efficiency metrics across different micro-batch sizes, showing that larger micro-batches improve overall efficiency while reducing bubble overhead. DeltaNet efficiency increases with micro-batch size, approaching a maximum as the batch size becomes large. Overall efficiency improves with larger micro-batches DeltaNet efficiency increases with micro-batch size Bubble overhead decreases as micro-batch size increases
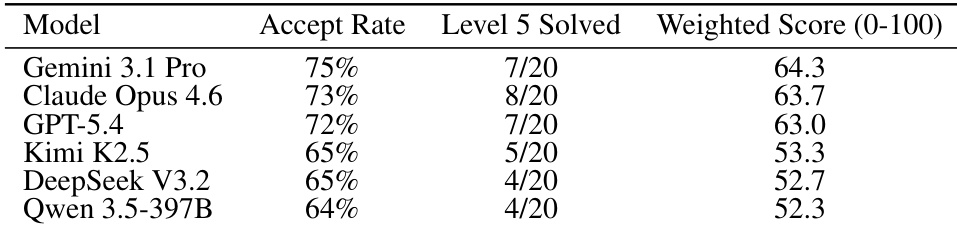
The authors compare several models on a benchmark of 100 problems, measuring accept rate, number of hardest problems solved, and a difficulty-weighted score. Results show that Gemini 3.1 Pro achieves the highest performance across all metrics, followed by Claude Opus 4.6 and GPT-5.4, while Qwen 3.5-397B performs the lowest. Gemini 3.1 Pro achieves the highest accept rate and weighted score among the evaluated models. Claude Opus 4.6 solves more Level 5 problems than other models except Gemini 3.1 Pro. Qwen 3.5-397B shows the lowest performance across all evaluation metrics.
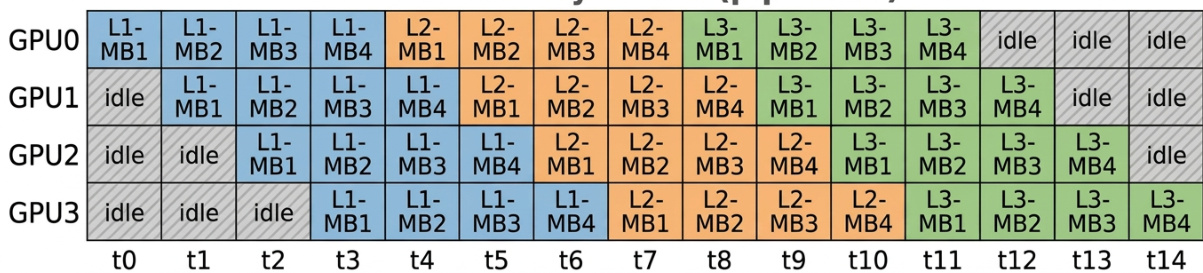
The the the table shows the allocation of tasks across four GPUs over time, with each GPU handling different levels and modules at various points. The GPUs are mostly active during the execution phases, with some periods of idleness, particularly in the early and late stages. Tasks are distributed across four GPUs with varying levels and modules over time GPUs are active during execution phases and idle at certain intervals The workload shifts dynamically among GPUs throughout the timeline
The experiments evaluate various aspects of model performance, including test case generation, training methodologies, architectural efficiency, and hardware utilization. Results demonstrate that iterative refinement and supervised fine-tuning significantly enhance test coverage and problem-solving capabilities, while larger micro-batch sizes improve computational efficiency by reducing overhead. Comparative analysis shows that Gemini 3.1 Pro outperforms other models on benchmark tasks, and GPU utilization patterns reveal dynamic workload distribution during execution.