Command Palette
Search for a command to run...
Generative World Renderer
Generative World Renderer
Zheng-Hui Huang Zhixiang Wang Jiaming Tan Ruihan Yu Yidan Zhang Bo Zheng Yu-Lun Liu Yung-Yu Chuang Kaipeng Zhang
초록
실제 세계 시나리오에 생성형 역 및 순방향 렌더링을 확장하는 것은 기존 합성 데이터셋의 제한된 사실성과 시간적 일관성으로 인해 병목 현상을 겪고 있습니다. 이러한 지속적인 도메인 간격 (domain gap) 을 해소하기 위해, 우리는 시각적으로 복잡한 AAA 게임에서 선별한 대규모 동적 데이터셋을 제안합니다. 새로운 듀얼 스크린 스티칭 (dual-screen stitched) 캡처 방식을 활용하여, 다양한 장면, 시각 효과 및 환경 (악천후 및 모션 블러 변형 포함) 에서 동기화된 RGB 와 5 개 G-buffer 채널에 대한 400 만 장의 연속 프레임 (720p/30 FPS) 을 추출했습니다. 본 데이터셋은 역방향 렌더링을 획기적으로 발전시켜, 야생 환경 (in-the-wild) 에서 견고한 기하학 및 재질 분해를 가능하게 하고, 고품질 G-buffer 기반 비디오 생성을 촉진합니다. 또한, 정답 (ground truth) 이 없는 상황에서 역 렌더링의 실제 성능을 평가하기 위해, 의미론적, 공간적, 시간적 일관성을 측정하는 새로운 VLM 기반 평가 프로토콜을 제안합니다. 실험 결과, 본 데이터를 통해 미세 조정 (fine-tuning) 된 역 렌더링 모델은 타 데이터셋에 대한 우수한 일반화 능력과 제어 가능한 생성 성능을 보였으며, 제안한 VLM 평가는 인간의 판단과 높은 상관관계를 나타냈습니다. 본 툴킷과 결합된 순방향 렌더러는 텍스트 프롬프트를 통해 G-buffer 를 활용하여 AAA 게임의 스타일을 편집할 수 있게 합니다.
One-sentence Summary
Researchers from Alaya Studio and multiple universities introduce a large-scale dataset from AAA games to bridge the realism gap in bidirectional rendering. By providing synchronized RGB and G-buffer frames, this work enables robust inverse rendering and high-fidelity G-buffer-guided video generation, surpassing prior methods limited by synthetic data scarcity.
Key Contributions
- The paper introduces a scalable G-buffer acquisition pipeline that renders multi-channel data to a unified canvas via hardware-accelerated capture, enabling temporally synchronized recording without modifying the game engine.
- A fine-tuned video inverse rendering model is presented that leverages motion-augmented training on game data to achieve state-of-the-art accuracy in depth, normal, albedo, and material parameter estimation on both synthetic and real-world benchmarks.
- The work demonstrates a practical game editing application by adapting a text-to-video model to accept G-buffers as conditional inputs, allowing users to manipulate lighting and environmental effects through text prompts during inference.
Introduction
No source text was provided to summarize. Please supply the abstract or body snippet of the research paper so I can generate the background summary with the required technical context, limitations, and contributions.
Dataset
-
Dataset Composition and Sources The authors curate a large-scale, dynamic dataset from two visually complex AAA games: Cyberpunk 2077 and Black Myth: Wukong. This collection bridges the domain gap between synthetic and real-world data by providing 4 million continuous frames at 720p resolution and 30 FPS. The dataset uniquely pairs synchronized RGB video with five high-fidelity G-buffer channels (depth, normals, albedo, metallic, and roughness) across diverse environments, including urban and natural scenes under varying weather conditions like rain, fog, and snow.
-
Key Details for Each Subset
- Cyberpunk 2077 Subset: Captured using semi-automated driving setups with long-range waypoints to generate continuous trajectories with variable speeds, alongside walking sequences for indoor coverage. This subset features a higher proportion of metallic surfaces and balanced luminance, reflecting its urban, metal-rich themes.
- Black Myth: Wukong Subset: Derived from exploration sequences in completed save files, deliberately avoiding combat to focus on diverse environmental traversal. This subset contains more high-roughness regions and lower luminance values, consistent with its natural, shadowed outdoor settings.
- Filtering Rules: The authors exclude clips where both the scene content and camera remain static throughout the sequence. Frames with excessively low luminance are also removed to ensure quality.
-
Data Usage in the Model The dataset serves as the primary supervision signal for training bidirectional rendering models, specifically fine-tuning Diffusion-based architectures for both inverse rendering (material decomposition) and forward rendering (G-buffer-guided video generation). The authors utilize the data to improve cross-dataset generalization and temporal coherence, enabling models to handle long-tail complexities such as volumetric effects and rapid motion. A novel VLM-based evaluation protocol is employed to assess semantic, spatial, and temporal consistency where traditional metrics fall short.
-
Processing and Construction Strategies
- Capture Pipeline: The team uses a non-intrusive dual-screen stitched capture method that intercepts the rendering pipeline at the graphics API level via ReShade, avoiding decompilation or asset extraction.
- Normal Reconstruction: Since only world-space normals are reliably available, the authors reconstruct camera-space normals from the depth buffer using inverse projection and finite differences.
- Channel Decoupling: To prevent compression artifacts, material channels like metallic and roughness are decoupled and rendered into spatially distinct screen regions before capture.
- Motion Blur Synthesis: While the engine captures sharp canonical RGB frames, the authors synthesize motion-blurred variants offline using RIFE for frame interpolation and linear domain averaging to better match real-world imaging conditions.
- Metadata Annotation: An LLM (Qwen3-VL) analyzes sampled frames to generate categorical labels for texture, weather, scene type (indoor/outdoor), and motion dynamics for each clip.
Method
The proposed framework consists of three distinct stages: Curation, Analysis, and Post-Processing. In the initial Curation stage, the authors address the high cost of directly exporting multi-channel G-buffers by implementing a synchronized multi-screen recording strategy. Instead of relying on expensive storage bandwidth or GPU-to-CPU readback, the system shades target buffers to the screen and records them via hardware-accelerated capture. To maintain strict temporal synchronization across all six channels, a mosaic compositing strategy is employed where buffers are rendered onto a unified canvas.
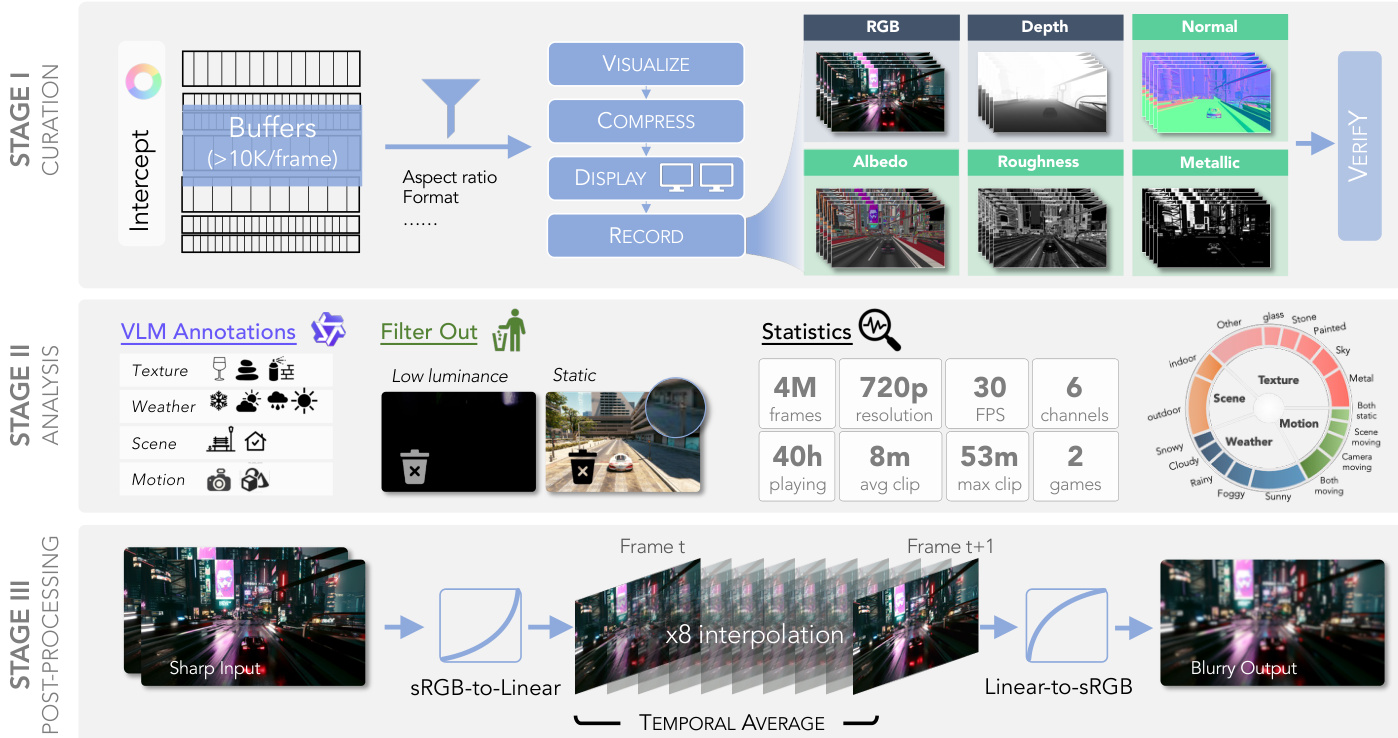
As illustrated in the framework diagram, this process allows for the capture of RGB, Depth, Normal, Albedo, Roughness, and Metallic channels simultaneously. A verification step follows, where metallic maps are evaluated based on semantic correctness, appearance quality, and temporal consistency to ensure material plausibility. To overcome display resolution limits, the setup stitches two 2K monitors, enabling recording at an effective 720p resolution per channel while preserving the intended aspect ratio through center-cropping.
The pipeline then proceeds to the Analysis stage, where data quality is ensured through automated filtering and annotation. VLMs are leveraged to annotate frames based on texture, weather, scene, and motion attributes. Frames exhibiting low luminance or static content are filtered out to maintain dataset diversity and quality. Statistical analysis confirms the collection of 4M frames at 30 FPS, covering various environmental conditions and motion types.
Finally, the Post-Processing stage generates motion blur effects to simulate real-world camera capture. The process begins with converting sharp input frames from sRGB to linear space. The system then performs 8x interpolation between consecutive frames, denoted as Frame t and Frame t+1, followed by a temporal average operation. The resulting data is converted back from linear to sRGB space to produce the final blurry output, effectively synthesizing motion blur without requiring physical camera movement.
Experiment
- Real-scene evaluation using Vision-Language Models (VLMs) validates that the proposed dataset improves generalization for material prediction in complex, ground-truth-free environments by leveraging global context and temporal reasoning.
- Quantitative benchmarks on synthetic datasets (Black Myth: Wukong and Sintel) demonstrate that fine-tuning on the new dataset yields superior performance in depth, normal, and albedo estimation compared to existing DiffusionRenderer baselines.
- Qualitative analysis confirms the method effectively disentangles intrinsic scene properties, producing cleaner albedo maps and robust material predictions that resist atmospheric disruptions like smoke and volumetric scattering.
- Ablation studies reveal that motion augmentation during training significantly enhances temporal stability and reduces artifacts in videos with strong motion blur.
- Relighting experiments show that the improved G-buffers enable off-the-shelf forward renderers to generate illumination-consistent novel views, proving the efficacy of the data-centric approach.
- Game editing evaluations indicate that using high-quality G-buffers as conditional inputs achieves a better balance between editability and visual fidelity than RGB-derived or stochastic editing baselines, allowing for seamless integration of complex atmospheric effects.