Command Palette
Search for a command to run...
SKILL0: 컨텍스트 내 에이전트 강화 학습을 통한 스킬 내재화
SKILL0: 컨텍스트 내 에이전트 강화 학습을 통한 스킬 내재화
Zhengxi Lu Zhiyuan Yao Jinyang Wu Chengcheng Han Qi Gu Xunliang Cai Weiming Lu Jun Xiao Yueting Zhuang Yongliang Shen
초록
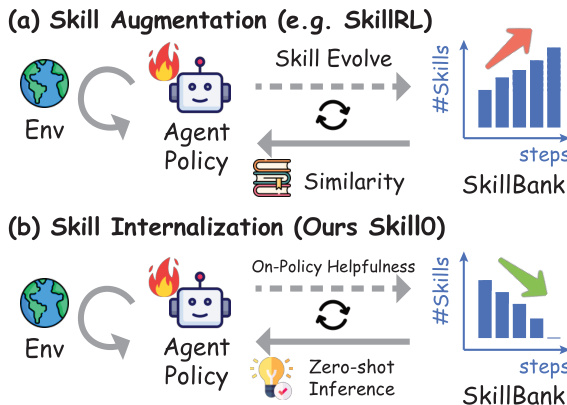
에이전트 스킬은 추론 시점에 에이전트가 동적으로 로드하는 절차적 지식과 실행 가능 자원의 구조화된 패키지로, LLM 에이전트를 강화하는 신뢰할 수 있는 메커니즘으로 자리 잡았습니다. 그러나 추론 시점의 스킬 증강은 근본적인 한계를 지닙니다: 검색 노이즈가 관련 없는 가이드를 유발하고, 주입된 스킬 콘텐츠는 상당한 토큰 오버헤드를 초래하며, 모델은 단순히 따르는 것 이상으로 해당 지식을 진정으로 습득하지 못합니다. 이에 우리는 스킬을 모델 파라미터 내부에 내재화하여, 런타임 스킬 검색 없이도 제로샷 (zero-shot) 자율적 행동을 가능하게 할 수 있는지 질문합니다. 본 논문에서는 스킬 내재화를 위해 설계된 인컨텍스트 강화학습 (in-context reinforcement learning) 프레임워크인 SKILL0 를 제안합니다. SKILL0 는 완전한 스킬 컨텍스트에서 시작하여 이를 점진적으로 제거하는 훈련 시 커리큘럼을 도입합니다. 스킬은 오프라인에서 카테고리별로 그룹화되고, 상호작용 이력과 함께 렌더링되어 컴팩트한 시각적 컨텍스트로 변환되며, 이를 통해 모델에 도구 호출 및 다턴 (multi-turn) 작업 완수 능력을 학습시킵니다. 이후 동적 커리큘럼 (Dynamic Curriculum) 은 각 스킬 파일의 온-폴리시 (on-policy) 유용성을 평가하여, 현재 정책이 여전히 혜택을 보는 스킬만을 선형적으로 감소하는 예산 내에서 유지하며, 에이전트가 완전히 제로샷 환경에서 작동하도록 합니다. 광범위한 에이전트 실험 결과, SKILL0 는 표준 RL 베이스라인 대비 ALFWorld 에서 +9.7%, Search-QA 에서 +6.6% 의 상당한 개선을 달성하면서도, 단계당 0.5k 토큰 미만의 매우 효율적인 컨텍스트를 유지하는 것을 확인했습니다. 관련 코드는 https://github.com/ZJU-REAL/SkillZero 에서 공개되어 있습니다.
One-sentence Summary
Researchers from Zhejiang University, Meituan, and Tsinghua University propose SKILL0, an in-context reinforcement learning framework that internalizes agent skills into model parameters via a dynamic curriculum. This approach eliminates runtime retrieval noise and token overhead, enabling efficient zero-shot autonomous behavior with significant performance gains on agentic benchmarks.
Key Contributions
- The paper introduces SKILL0, an in-context reinforcement learning framework that formulates skill internalization as an explicit training objective to transition agents from context-dependent execution to fully autonomous zero-shot behavior.
- A Dynamic Curriculum mechanism is presented to evaluate the on-policy helpfulness of each skill file, adaptively withdrawing guidance only when the current policy no longer benefits until the agent operates without any external skill context.
- Extensive experiments on ALFWorld and Search-QA demonstrate that the method achieves substantial performance improvements over standard RL baselines while maintaining an efficient context of fewer than 0.5k tokens per step.
Introduction
Large Language Model agents currently rely on inference-time skill augmentation, where structured behavioral primitives are retrieved and injected into the prompt to guide complex tasks. While effective, this approach suffers from retrieval noise that corrupts context, significant token overhead that limits scalability, and a fundamental dependency where competence resides in the prompt rather than the model itself. The authors propose SKILL0, the first reinforcement learning framework designed to internalize these skills directly into model parameters so that agents operate autonomously without external guidance at inference. They achieve this through In-Context Reinforcement Learning, which provides skill scaffolding during training rollouts and systematically removes it via a Dynamic Curriculum that withdraws support only when the policy no longer benefits from it.
Dataset
-
Dataset Composition and Sources: The authors evaluate their methods on two primary benchmarks: ALFWorld, a text-based game with 3,827 task instances across six household activity categories, and Search-based QA, which aggregates single-hop datasets (NQ, TriviaQA, PopQA) and multi-hop datasets (HotpotQA, 2Wiki, MuSiQue, Bamboogle).
-
Training Data Selection and Splitting: For ALFWorld, the training data follows the split from GiGPO, while Search-QA training draws specifically from NQ and HotpotQA to serve as in-domain data, leaving the remaining QA datasets for out-of-domain evaluation.
-
Training Configuration and Mixture: The Qwen2.5-VL series is trained for up to 180 steps using 4 H800 GPUs. The ALFWorld setup samples 16 tasks with 8 rollouts per prompt and a maximum length of 3,072 tokens, whereas the Search-QA setup samples 128 tasks per batch with a maximum length of 4,096 tokens.
-
Visual Context and Rendering Strategy: The authors construct visual context by rendering text in a monospace font with specific sizing and width constraints (10pt/392px for ALFWorld, 12pt/560px for Search-QA). They apply a semantic color coding scheme where task instructions appear in black, observations in blue, and actions or search queries in red to help the vision encoder distinguish between states, actions, and retrieved content.
-
Curriculum and Skill Initialization: A curriculum learning schedule is implemented with three stages and a validation subset of 1,000 examples. The SkillBank is initialized using skills from SkillRL to provide structured procedural knowledge for both environments.
Method
The authors introduce SKILL0, a framework designed to internalize agent skills into model parameters, enabling zero-shot autonomous behavior without runtime skill retrieval. Unlike traditional skill augmentation which accumulates skills and incurs token overhead, SKILL0 progressively withdraws external guidance. Refer to the framework diagram for a comparison between standard skill augmentation and the proposed skill internalization approach.
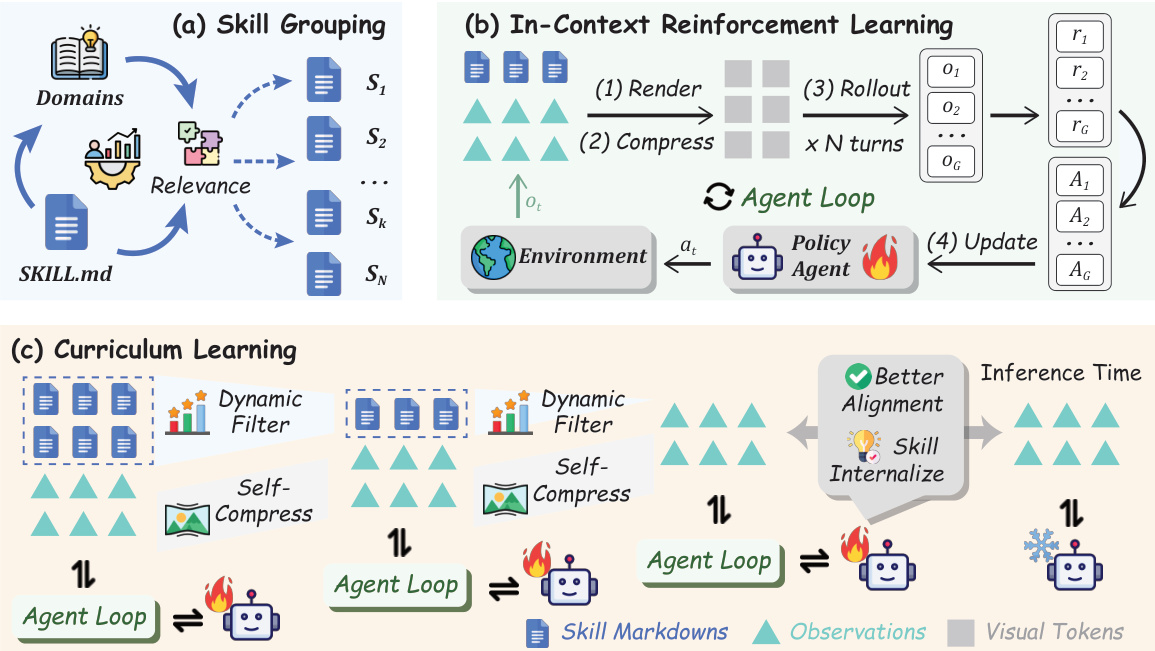
The overall architecture integrates skill grouping, in-context reinforcement learning, and adaptive curriculum learning. As shown in the figure below, the process begins with offline skill grouping where domains are mapped to relevant skill files. During the agent loop, textual interaction history and skills are rendered into a compact visual context. The curriculum learning component dynamically filters skills based on on-policy helpfulness, reducing the skill budget over time until the agent operates in a fully zero-shot setting.
To facilitate this process, the agent is instructed via specific prompts that define the task, history, and required output format. An example of the prompt structure used for search-based QA tasks is provided below.
 The prompt requires the agent to conduct reasoning, select an action such as calling a search engine or providing an answer, and specify the next image compression factor.
The prompt requires the agent to conduct reasoning, select an action such as calling a search engine or providing an answer, and specify the next image compression factor.
The training process utilizes In-Context Reinforcement Learning (ICRL) with a composite reward function that jointly optimizes task success and compression efficiency. The reward is defined as:
rtcomp={ln(ct),0,if Isucc(τ)=1,otherwise,r~t=rt+λ⋅rtcompwhere ct is the compression ratio and λ controls the trade-off. The training objective follows a PPO-style loss:
LSKILL0(θ)=τi∼πθold(q),q∼DE∑i=1G∣τi∣1i=1∑Gt=1∑∣τi∣clip(ri,t(θ),Ai,ϵ)−β⋅DKL[πθ∣∣πref]Adaptive curriculum learning manages the skill context by linearly decaying the skill budget M(s) at each stage s:
∣S(s)∣≤M(s)=⌈N⋅NS−1NS−s⌉This ensures the distribution shift of the policy remains smooth as the agent transitions from relying on external skills to operating independently.
Experiment
- Main performance experiments validate that SKILL0 significantly outperforms zero-shot, skill-augmented, and memory-augmented baselines on ALFWorld and Search-QA, demonstrating successful internalization of complex reasoning and tool-use behaviors into model parameters without relying on external prompts during inference.
- Training dynamics analysis confirms a clear skill internalization trend where models initially benefit from skill scaffolding but gradually achieve superior performance in skill-free settings as the curriculum reduces external support, proving the method learns robust internal knowledge rather than superficial prompt dependency.
- Ablation studies on skill budget and dynamic curriculum design reveal that a progressive annealing strategy with helpfulness-driven filtering is essential for stable learning, as static or unfiltered skill sets lead to performance collapse or over-reliance on prompts, while the proposed approach ensures effective knowledge transfer.
- Token efficiency evaluations show that SKILL0 achieves state-of-the-art results with substantially lower context token costs compared to text-based or skill-augmented methods, highlighting the efficiency gains from visual context modeling and skill internalization.
- Generalization tests on out-of-domain multi-hop datasets demonstrate that the approach maintains strong performance on unseen reasoning tasks without domain-specific adaptation, confirming its robustness and adaptability across diverse benchmarks.