Command Palette
Search for a command to run...
잠재 공간: 기초, 진화, 메커니즘, 능력 및 전망
잠재 공간: 기초, 진화, 메커니즘, 능력 및 전망
초록
잠재 공간 (latent space) 은 언어 기반 모델의 고유한 기반 (substrate) 으로 급속히 부상하고 있습니다. 현대 시스템은 여전히 명시적 토큰 수준의 생성 (explicit token-level generation) 을 통해 주로 이해되지만, 최근 증가하는 연구들은 많은 핵심 내부 프로세스가 인간이 읽을 수 있는 언어적 흔적보다는 연속적인 잠재 공간에서 더 자연스럽게 수행됨을 보여줍니다. 이러한 전환은 언어적 중복성, 이산화 병목 현상, 순차적 비효율성, 그리고 의미 손실과 같은 명시적 공간 계산의 구조적 한계에 의해 주도됩니다. 본 논문은 언어 기반 모델에서의 잠재 공간에 관한 통합적이고 최신의 연구 지형을 제시하는 것을 목표로 합니다. 우리는 본 논문을 기초 (Foundation), 진화 (Evolution), 메커니즘 (Mechanism), 능력 (Ability), 그리고 전망 (Outlook) 의 다섯 가지 순차적 관점으로 구성하였습니다. 먼저 잠재 공간의 범위를 명확히 하고, 이를 명시적 공간 또는 언어적 공간, 그리고 생성형 시각 모델에서 일반적으로 연구되는 잠재 공간과 구분합니다. 이어 초기 탐색적 시도부터 현재 대규모 확장까지의 분야 진화 과정을 추적합니다. 기술적 지형을 체계화하기 위해 메커니즘과 능력이라는 상호 보완적 관점을 통해 기존 연구를 분석합니다. 메커니즘 관점에서는 아키텍처 (Architecture), 표현 (Representation), 계산 (Computation), 최적화 (Optimization) 의 네 가지 주요 발전 흐름을 규명합니다. 능력 관점에서는 잠재 공간이 추론 (Reasoning), 계획 (Planning), 모델링 (Modeling), 지각 (Perception), 기억 (Memory), 협업 (Collaboration), 그리고 구체화 (Embodiment) 에 이르는 광범위한 능력 스펙트럼을 어떻게 지원하는지 제시합니다. 기존 연구의 통합을 넘어, 우리는 주요 열린 과제들을 논의하고 미래 연구의 유망한 방향을 제시합니다. 본 논문이 기존 연구를 위한 참고 자료일 뿐만 아니라, 차세대 지능을 위한 일반적인 계산 및 시스템 패러다임으로서 잠재 공간을 이해하는 토대가 되기를 기대합니다.
One-sentence Summary
Researchers from National University of Singapore, Fudan University, Tsinghua University, and other leading institutions propose a unified survey on latent space in language-based models, introducing a two-dimensional taxonomy of mechanisms and abilities to consolidate fragmented literature and guide future research in reasoning, perception, and embodied AI.
Key Contributions
- The paper introduces a unified survey framework organized around five sequential perspectives—Foundation, Evolution, Mechanism, Ability, and Outlook—to consolidate fragmented literature on latent space in language-based models.
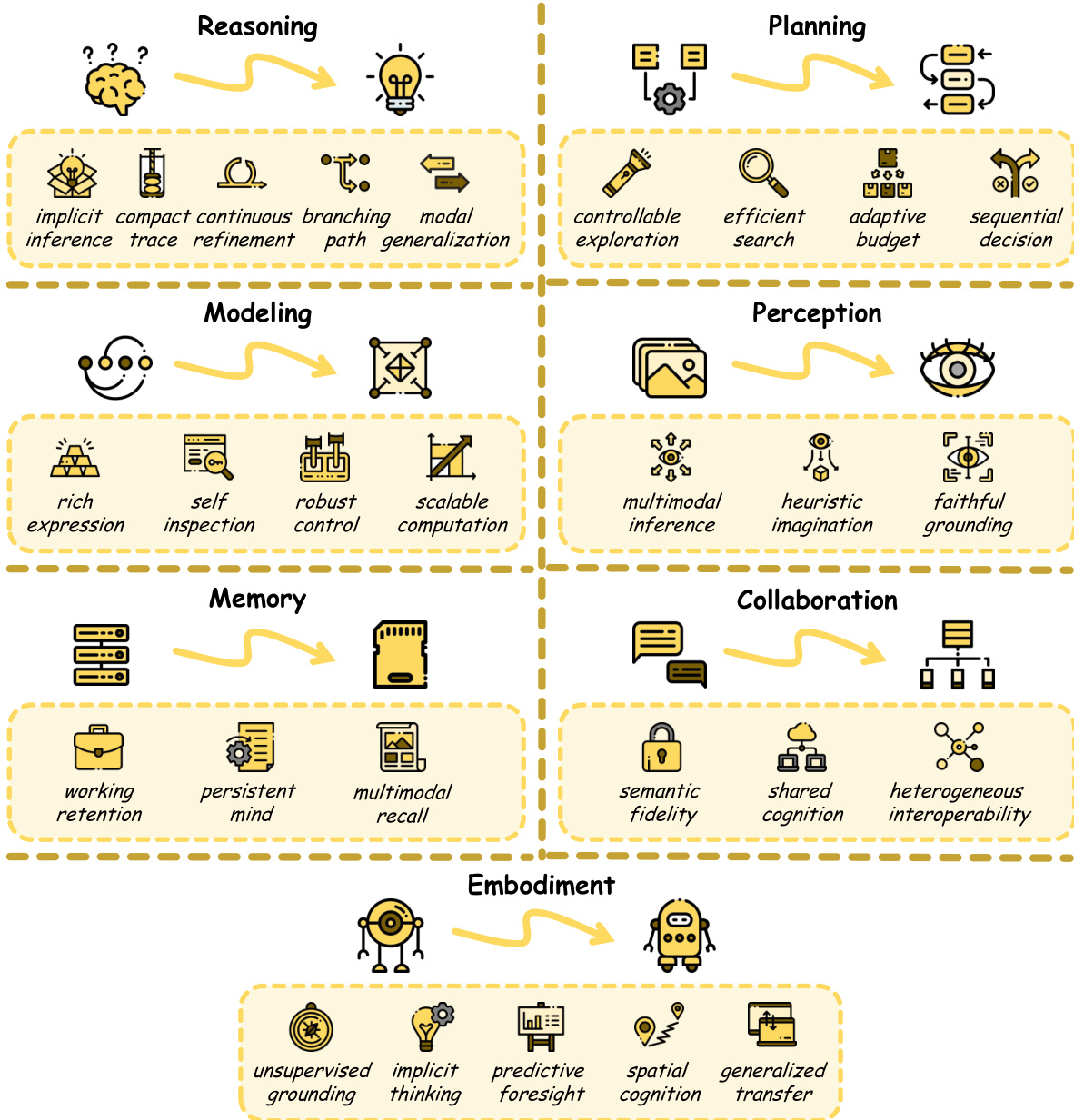
- This work presents a comprehensive technical taxonomy that classifies existing methods into four mechanism categories (Architecture, Representation, Computation, Optimization) and seven ability domains (Reasoning, Planning, Modeling, Perception, Memory, Collaboration, Embodiment).
- The study delineates the conceptual scope of latent space by distinguishing it from explicit token-level generation and visual generative models, while outlining open challenges and future research directions for next-generation intelligence.
Introduction
Language-based models are increasingly shifting from explicit token-level generation to continuous latent space as a native computational substrate, driven by the need to overcome linguistic redundancy, discretization bottlenecks, and sequential inefficiencies inherent in verbal traces. Prior research has largely remained fragmented across specific tasks like latent reasoning or visual understanding, lacking a unified framework to classify the diverse mechanisms and capabilities emerging in this field. The authors address this gap by providing a comprehensive survey that organizes the landscape into five sequential perspectives and introduces a two-dimensional taxonomy based on technical mechanisms and functional abilities to guide future research.
Method
The authors propose a unified framework to categorize how latent space is instantiated and operationalized within modern language-based systems. This mechanism-oriented taxonomy organizes diverse approaches along four complementary axes: Architecture, Representation, Computation, and Optimization. As illustrated in the framework diagram, these dimensions collectively define the design space for latent-space methods, clarifying how latent variables are constructed, processed, and refined.
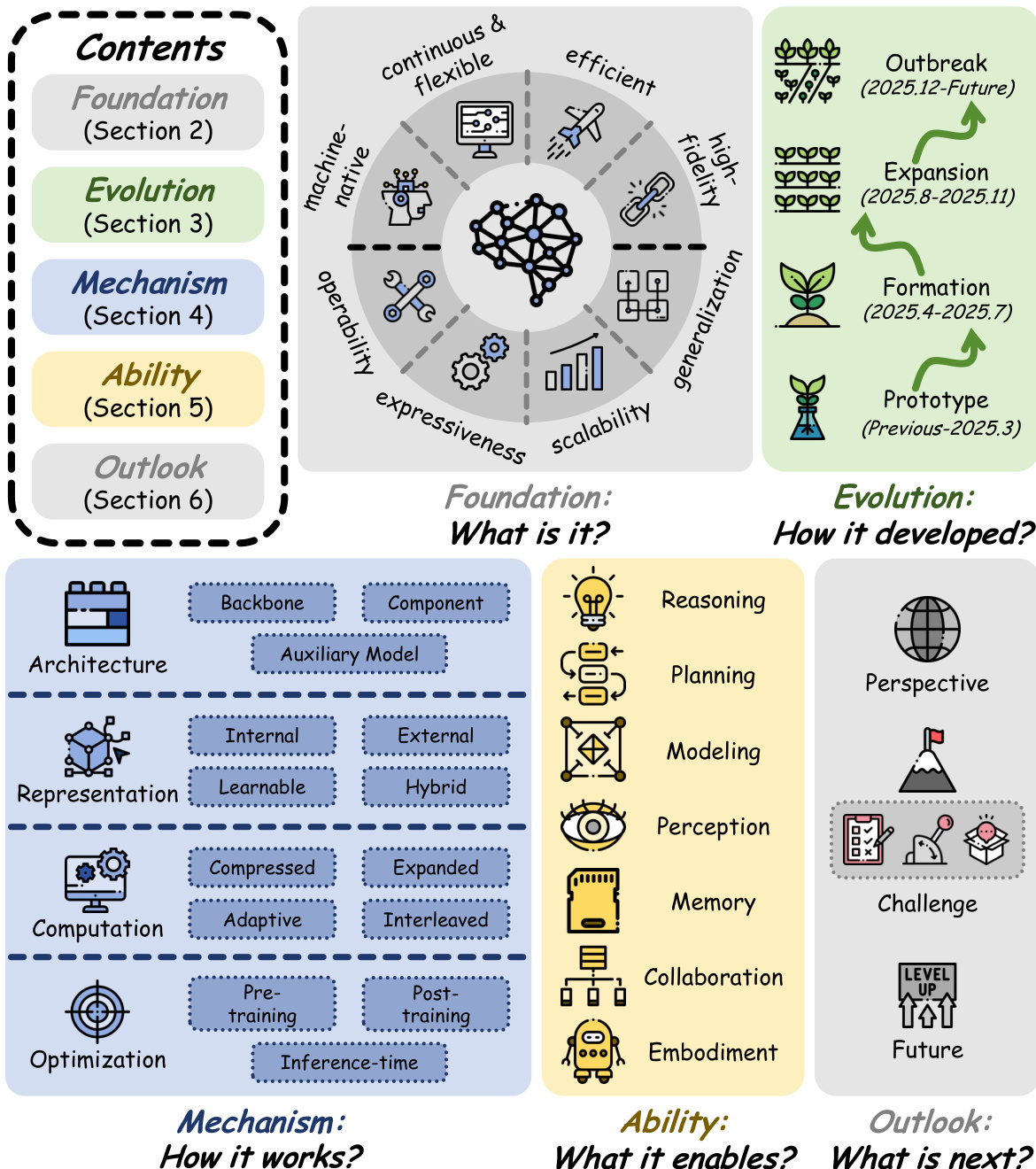
The architectural axis characterizes the structural role of latent space in the model. Methods are classified into three categories based on where latent computation is embedded. First, Backbone-based approaches endow the main model with native latent capacity through recurrent, looping, or recursive structures, making latent operation a primitive of the architecture itself. Second, Component-based methods preserve the original backbone but augment it with functional modules that construct, transform, store, or retrieve latent representations. Third, Auxiliary Model-based paradigms utilize an extra model to provide supervision signals or intermediate features to guide or supplement the host model. The taxonomy of representative works across these architectural choices is detailed in the grid diagram.

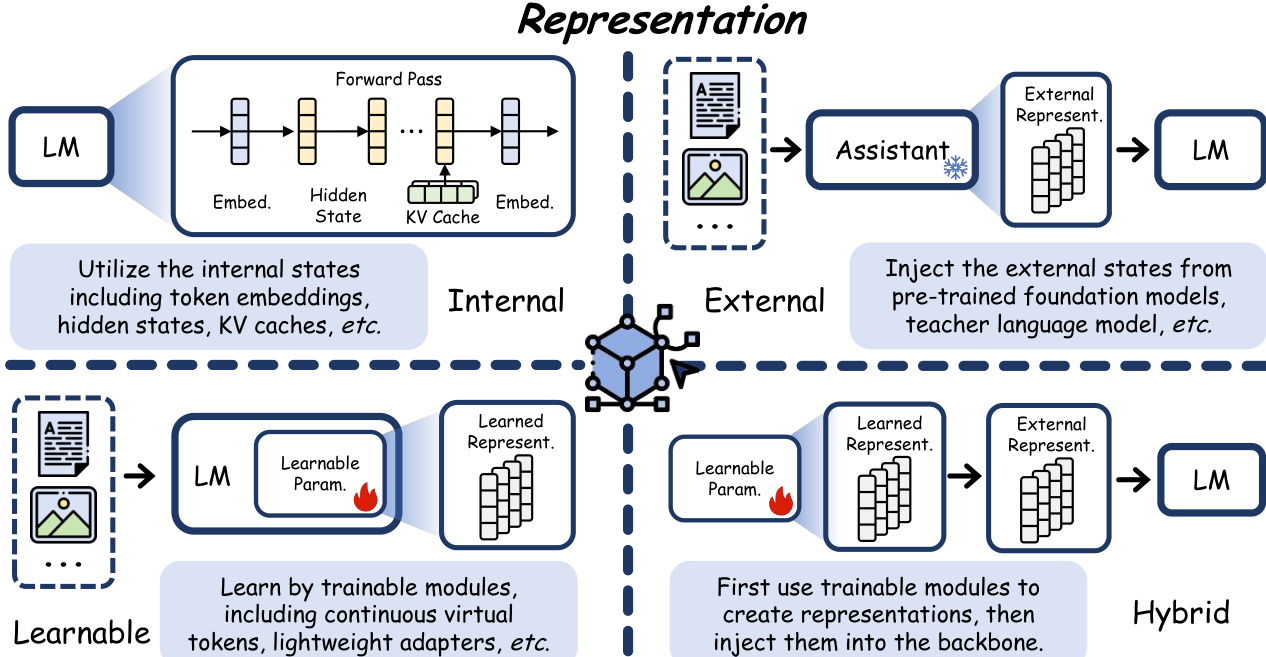
The representation axis describes the form of latent variables, distinguishing how information is encoded and integrated. Internal representations operate directly on activations produced during the backbone's forward pass, such as token embeddings or hidden states, without introducing additional parameters. External representations are derived from a structurally independent auxiliary system and injected into the backbone as conditioning inputs. Learnable representations are constructed by dedicated trainable modules embedded directly into the backbone and optimized end-to-end. Hybrid representations combine the Learnable and External paradigms by first using trainable modules to create specialized representations, then injecting them as exogenous signals. The schematic diagram illustrates these four sub-types and their data flow.
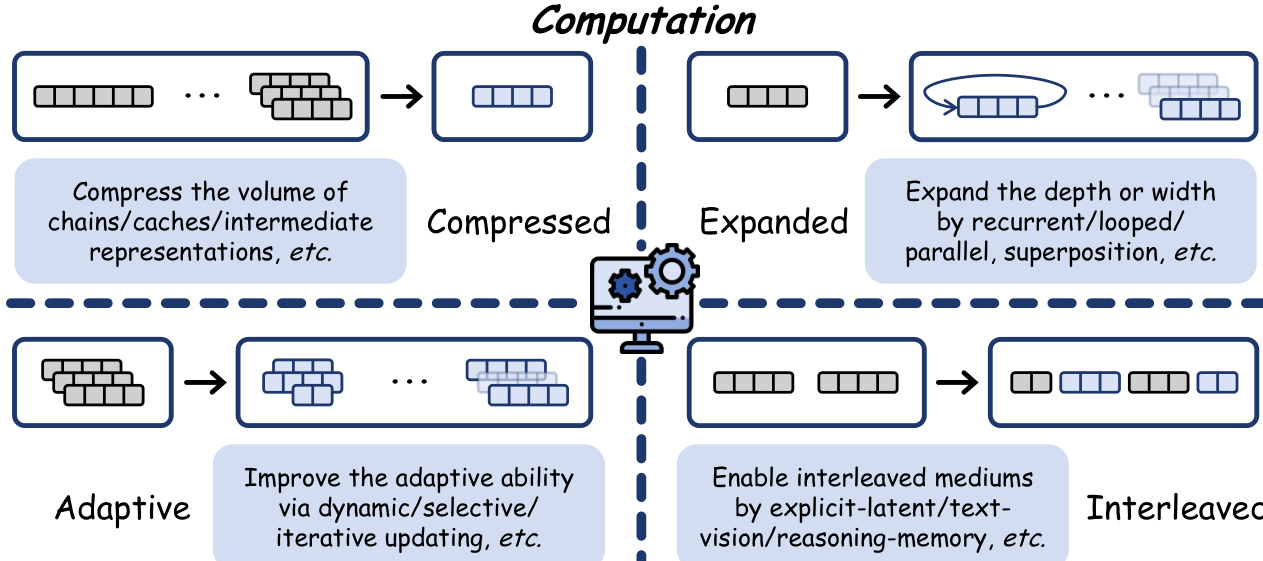
The computation axis captures how the latent space participates in information processing. Compressed computation reduces the volume of explicit traces or internal states to enhance efficiency while preserving expressiveness. Expanded computation increases effective capacity by extending latent processes along depth or width dimensions, such as through recurrent or parallel designs. Adaptive computation allocates resources dynamically based on input complexity, balancing capacity and efficiency flexibly. Interleaved computation bridges heterogeneous generation media, alternating between discrete tokens and continuous latents to combine explicit interpretability with implicit power. The corresponding schematic outlines these four computational strategies.
The optimization axis focuses on when and how latent space is induced, aligned, or refined. Pre-training methods start with a randomly initialized model and train it from scratch to enable native latent-level abilities. Post-training enhances the ability of pre-trained models using diverse supervision signals and objectives to learn the latent space. Inference-time methods focus on the manipulation of latent states during test time, allowing for dynamic adjustment without modifying model weights. The overview table summarizes the supervision, objective, and scenarios for each optimization stage.
Experiment
- A comparative analysis was conducted between the latent space and traditional explicit (verbal) space to clarify the unique characteristics of the latent representation.
- The experiment validates a paradigm shift in the representational properties and functional capabilities of language models when utilizing latent space versus explicit space.