Command Palette
Search for a command to run...
Diffusion Transformer 에서 풍부한 다양성을 위한 문맥 공간 내 온더플라이 반발
Diffusion Transformer 에서 풍부한 다양성을 위한 문맥 공간 내 온더플라이 반발
Omer Dahary Benaya Koren Daniel Garibi Daniel Cohen-Or
초록
현대적인 텍스트-이미지 (T2I) 확산 모델은 뛰어난 의미론적 정렬 (semantic alignment) 을 달성했으나, 주어진 프롬프트 (prompt) 에 대해 시각적 해답이 좁은 범위로 수렴하는 심각한 다양성 부재 문제를 안고 있습니다. 이러한 전형성 편향 (typicality bias) 은 광범위한 생성 결과를 요구하는 창의적 응용 분야에 있어 주요 과제로 대두됩니다. 우리는 현재 다양성 확보를 위한 접근법에서 근본적인 트레이드오프를 확인했습니다. 즉, 모델 입력을 수정하려면 생성 경로의 피드백을 통합하기 위해 비용이 많이 드는 최적화가 필요하다는 점입니다. 반면, 공간적으로 고정된 중간 잠재 공간 (intermediate latents) 에 개입하는 것은 형성 중인 시각적 구조를 교란시켜 아티팩트 (artifacts) 를 유발하는 경향이 있습니다.본 논문에서는 확산 Transformer 에서 풍부한 다양성을 달성하기 위한 새로운 프레임워크로서 맥락 공간 (Contextual Space) 내에서의 반발 (repulsion) 적용을 제안합니다. 다중 모드 어텐션 채널에 개입하여 Transformer 의 순전파 (forward pass) 도중 실시간으로 반발을 적용함으로써, 텍스트 조건부 (text conditioning) 가 생성된 이미지 구조와 결합되는 블록 간에 개입을 주입합니다. 이를 통해 구성이 고정되기 전이지만 구조적 정보가 반영된 이후에 안내 궤적 (guidance trajectory) 을 재조정할 수 있습니다.실험 결과는 맥락 공간 내 반발이 시각적 충실도 (visual fidelity) 나 의미론적 준거 (semantic adherence) 를 희생하지 않으면서도 현저히 풍부한 다양성을 생성함을 입증합니다. 더 나아가 본 방법은 계산 오버헤드가 매우 작을 뿐만 아니라, 기존 궤적 기반 개입이 일반적으로 실패하는 최신 'Turbo' 및 증류 (distilled) 모델에서도 효과적으로 작동한다는 점에서 독보적인 효율성을 보입니다.
One-sentence Summary
Researchers from Tel Aviv University and Snap Research propose Contextual Space repulsion, a framework that injects on-the-fly diversity into Diffusion Transformers by intervening in multimodal attention channels. This technique overcomes typicality bias in models like Flux-dev by steering generative intent before visual commitment, delivering rich variety with minimal computational overhead.
Key Contributions
- The paper introduces a Contextual Space repulsion framework that applies on-the-fly intervention within the multimodal attention channels of Diffusion Transformers to steer generative intent after structural information emerges but before composition is fixed.
- This method injects repulsion between transformer blocks where text conditioning is enriched with emergent image structure, allowing the model to explore diverse paths while preserving samples within the learned data manifold to avoid visual artifacts.
- Experiments on the COCO benchmark across multiple DiT architectures demonstrate that the approach produces significantly richer diversity without sacrificing visual fidelity or semantic adherence, even in efficient "Turbo" and distilled models where traditional interventions fail.
Introduction
Modern Text-to-Image diffusion models excel at semantic alignment but often suffer from typicality bias, converging on a narrow set of visual solutions that limits their utility for creative applications. Prior attempts to restore diversity face a critical trade-off: upstream methods that modify inputs require costly optimization to incorporate structural feedback, while downstream interventions on image latents often disrupt the formed visual structure and introduce artifacts. The authors leverage the Contextual Space within Diffusion Transformers to apply on-the-fly repulsion during the forward pass, intervening in multimodal attention channels where text conditioning is enriched with emergent image structure. This approach redirects the guidance trajectory after the model is structurally informed but before the composition is fixed, achieving rich diversity with minimal computational overhead while preserving visual fidelity and semantic adherence.
Method
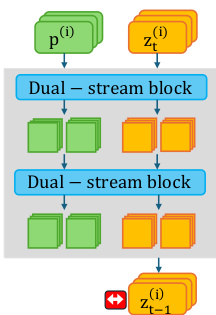
The authors leverage the inherent structure of Multimodal Diffusion Transformers (DiTs) to introduce a novel intervention strategy for generative diversity. Unlike U-Net architectures that rely on static text embeddings, DiTs facilitate a bidirectional exchange between text features fT and image features fI within Multimodal Attention (MM-Attention) blocks. As shown in the framework diagram, the standard processing flow involves dual-stream blocks where text prompts p(i) and noisy latents zt(i) are processed to generate the next state zt−1(i).
The core difficulty with existing methods lies in the timing and location of the repulsion. Upstream methods act on uninformed noise, while downstream methods act on a rigid latent manifold. The authors identify the Contextual Space, formed by the enriched text tokens f^T(l) after MM-Attention, as an effective environment for diversity interventions because it is structurally informed yet conceptually flexible.
To achieve this, the authors adopt a particle guidance framework that treats a batch of samples as interacting particles. However, unlike prior work that applies guidance to the image latents zt, as illustrated in the figure below where repulsion is applied to the output latent, the proposed method applies repulsive forces directly to the Contextual Space tokens f^T.
By enforcing distance between batch samples in this space, the model's high-level planning is steered before it commits to a specific visual mode. As shown in the figure below, the intervention is applied within the transformer blocks, indicated by the red arrows on the contextual stream, allowing for the manipulation of generative intent without requiring backpropagation through the model layers.
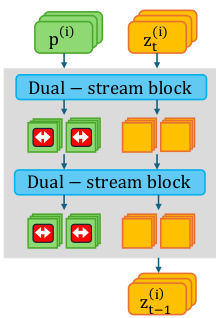
The updated state of the contextual tokens for a sample i after each iteration is given by:
f^T,i(l)′=f^T,i(l)+Mη∇f^T,i(l)Ldiv({f^T,j(l)}j=1B)where η is the overall repulsion scale and Ldiv is a diversity loss defined over the batch. To maintain diversity throughout the trajectory, this repulsion is applied across all transformer MM-blocks, specifically restricted to the first few timesteps where guidance signals are strongest.
For the diversity objective, the authors utilize the Vendi Score, which provides a principled way to measure the effective number of distinct samples in a batch. This is computed by analyzing the eigenvalues of a similarity matrix constructed from flattened contextual vectors. The Contextual Space encodes global semantic intent shared across the batch, making diversity objectives based on batch-level similarity more appropriate. As shown in the figure below, this approach allows for diverse interpolations and extrapolations while maintaining semantic alignment in the Contextual Space, preventing the semantic collapse typically induced by standard guidance.

Experiment
- Interpolation and extrapolation experiments in the Contextual Space versus VAE Latent Space demonstrate that the Contextual Space enables smooth semantic transitions and maintains high visual fidelity, whereas the Latent Space suffers from structural blurring and artifacts due to spatial misalignment.
- Qualitative evaluations across Flux-dev, SD3.5-Turbo, and SD3.5-Large architectures show that the proposed method generates diverse compositions and styles without the visual artifacts common in downstream latent interventions or the semantic drift seen in some upstream baselines.
- Quantitative analysis reveals a superior trade-off between semantic diversity and image quality, with the method achieving higher human preference and prompt alignment scores while incurring significantly lower computational overhead than optimization-based approaches.
- Ablation studies confirm that intervening in the Contextual Space is more effective than in image token spaces, as it allows for varied global compositions without the spatial rigidity that leads to local texture artifacts.
- Integration tests on image editing models validate that the approach generalizes beyond text-to-image generation, producing diverse yet coherent edits while preserving the original image integrity.