Command Palette
Search for a command to run...
MDPBench: 실전 시나리오에서의 다국어 문서 파싱을 위한 벤치마크
MDPBench: 실전 시나리오에서의 다국어 문서 파싱을 위한 벤치마크
Zhang Li Zhibo Lin Qiang Liu Ziyang Zhang Shuo Zhang Zidun Guo Jiajun Song Jiarui Zhang Xiang Bai Yuliang Liu
초록
본 연구에서는 다국어 디지털 및 사진 문서 파싱(document parsing)을 위한 최초의 벤치마크인 Multilingual Document Parsing Benchmark (MDPBench)를 소개합니다. 문서 파싱 기술은 비약적인 발전을 이루었으나, 지금까지는 소수의 주요 언어로 구성된 깨끗한 디지털 형식의 잘 정돈된 페이지에만 거의 독점적으로 집중되어 왔습니다. 다양한 문자 체계와 저자원 언어(low-resource languages)를 아우르는 디지털 및 사진 문서에 대해 모델의 성능을 평가할 수 있는 체계적인 벤치마크는 존재하지 않았습니다.MDPBench는 17개 언어, 다양한 문자 체계 및 다양한 촬영 조건을 포괄하는 3,400개의 문서 이미지를 포함하고 있습니다. 또한, 전문가 모델 라벨링(model labeling), 수동 수정, 그리고 인간 검증(human verification)으로 이어지는 엄격한 pipeline을 통해 생성된 고품질의 annotation을 제공합니다. 공정한 비교를 보장하고 데이터 누수(data leakage)를 방지하기 위해, 본 연구에서는 공개(public) 및 비공개(private) 평가 스플릿(split)을 별도로 유지합니다.오픈 소스 및 폐쇄형(closed-source) 모델 모두를 대상으로 진행한 포괄적인 평가 결과, 매우 놀라운 사실이 밝혀졌습니다. 폐쇄형 모델(특히 Gemini3-Pro)은 비교적 견고한 성능을 보이는 반면, 오픈 소스 대안 모델들은 특히 비라틴(non-Latin) 문자 체계와 실제 환경에서 촬영된 사진 문서에서 심각한 성능 저하를 보였습니다. 구체적으로 사진 문서에서는 평균 17.8%, 비라틴 문자 체계에서는 14.0%의 성능 하락이 관찰되었습니다. 이러한 결과는 언어와 조건에 따른 상당한 성능 불균형을 드러내며, 보다 포용적이고 실제 배포 가능한(deployment-ready) 파싱 시스템을 구축하기 위한 구체적인 방향성을 제시합니다.
One-sentence Summary
The researchers introduce MDPBench, the first benchmark for multilingual digital and photographed document parsing, which utilizes a dataset of 3,400 images across 17 languages to reveal that while closed-source models like Gemini3-Pro remain relatively robust, open-source models suffer significant performance collapses on non-Latin scripts and photographed documents.
Key Contributions
- The paper introduces MDPBench, the first benchmark designed to evaluate multilingual document parsing across both digital and photographed documents.
- This work provides a dataset of 3,400 high-quality images spanning 17 languages and diverse scripts, which were annotated through a rigorous pipeline involving expert model labeling, manual correction, and human verification.
- Extensive evaluations of open-source and closed-source models reveal significant performance gaps, specifically showing that open-source models experience an average performance drop of 17.8% on photographed documents and 14.0% on non-Latin scripts.
Introduction
Efficient document parsing is essential for digitizing information, yet current research focuses almost exclusively on clean, digitally born documents in a few dominant languages. Existing benchmarks fail to account for the complexities of real-world scenarios, such as diverse scripts, low-resource languages, and the visual distortions found in photographed documents. To address these gaps, the authors introduce MDPBench, the first comprehensive benchmark for multilingual digital and photographed document parsing. The dataset consists of 3,400 high-quality images spanning 17 languages and various photographic conditions, providing a rigorous framework to evaluate how models handle non-Latin scripts and imperfect real-world captures.
Dataset
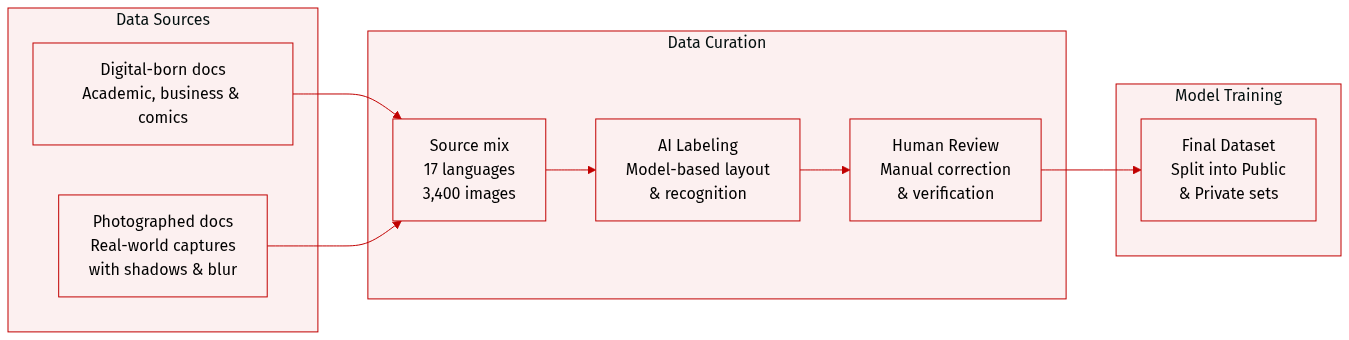
-
Dataset Composition and Sources: The authors introduce MDPBench, a benchmark consisting of 3,400 document images across 17 languages. The dataset includes digital-born documents sourced from academic papers, business reports, educational materials, handwritten notes, historical archives, newspapers, and complex text-image documents like comics. It also incorporates challenging Chinese and English documents from OmniDocBench.
-
Subset Details:
- Digital-born Subset: Contains 850 curated images spanning 17 languages. These were selected for diversity in layout complexity and visual elements such as formulas, tables, and charts, following a manual review to filter out low-quality or trivial samples.
- Photographed Subset: Created by transforming digital documents into real-world images through printing or screen capture. This subset includes indoor and outdoor captures with various degradations, such as physical deformations (bending and wrinkling), diverse camera angles (oblique and inverted), moiré patterns, reflections, shadows, and uneven illumination.
- Public and Private Splits: To prevent benchmark overfitting, the authors divide the data into a public subset for community download and a private subset for secure evaluation via an official website.
-
Data Processing and Annotation:
- Multi-stage Annotation Pipeline: The authors employ a rigorous "annotation-correction-verification" workflow.
- Expert Model Labeling: Layout detection is performed using dots.ocr and PaddleOCR-VL. Text, table, and formula blocks are cropped based on bounding boxes. Recognition is then performed by three models (PaddleOCR-VL, dots.ocr, and Qwen3VL). The final initial annotation is selected based on the highest average similarity (using NED for text/formulas and TEDS for tables) among the models. If similarity falls below 0.7, Gemini-3-pro is used to ensure reliability.
- Manual Correction and Verification: Annotators manually correct layout coordinates, element types, and reading order. An independent reviewer then verifies the corrected documents, returning any errors to the original annotator for iterative revision.
-
Evaluation Strategy: The authors use a page-level aggregation strategy to prevent imbalanced element distributions (like formulas or tables) from disproportionately affecting multilingual scores. Metrics are calculated per page and then averaged. Evaluation ignores page components such as headers, footers, and page numbers. Specific metrics include Normalized Edit Distance (NED) for text, CDM for formulas, and Tree-Edit-Distance-based Similarity (TEDS) for tables.
Experiment
The MDPBench evaluates a diverse range of document parsing models, including general vision-language models and specialized pipeline systems, across 17 languages and various document formats. The experiments validate model robustness against real-world challenges such as photographed documents, complex layouts, and non-Latin scripts. Findings reveal that while proprietary models generally outperform open-source alternatives, all methods suffer significant performance drops when handling photographed images or low-resource languages. Furthermore, models frequently struggle with language-specific nuances, including incorrect reading orders for right-to-left scripts, visual confusion in Cyrillic characters, and hallucinations in unspaced text.
The authors evaluate multiple document parsing models on a multilingual benchmark, comparing their performance across different languages and document types. Results show significant differences between proprietary and open-source models, with notable challenges in parsing photographed documents and non-Latin scripts. Proprietary models outperform open-source models across all evaluation metrics. Performance degrades significantly on photographed documents compared to digital-born ones. Models exhibit lower accuracy on non-Latin-script languages and struggle with language-specific reading orders.

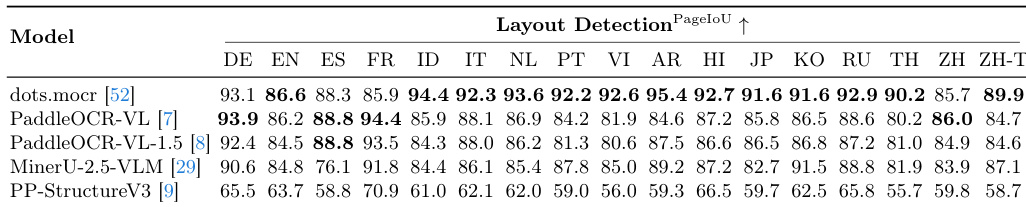
The authors evaluate multiple models on layout detection using MDPBench, focusing on performance across various languages. Results show that dots.mocr achieves the highest overall accuracy, with strong performance in many languages, while other models exhibit varying degrees of effectiveness depending on language and image type. dots.mocr achieves the highest overall layout detection accuracy across multiple languages Performance varies significantly across languages, with some models showing strong results in certain scripts and weaker ones in others Models exhibit differences in handling different languages, indicating language-specific biases in training data
The the the table compares several document parsing benchmarks, highlighting differences in language coverage, image types, and photograph conditions. MDPBench stands out with broader language support and a focus on photographed documents under diverse real-world conditions. MDPBench includes more languages and a wider range of photograph conditions compared to other benchmarks. Most existing benchmarks focus on digital-born documents, while MDPBench emphasizes photographed and real-world scenarios. MDPBench features a larger number of document images and includes diverse photographic challenges such as background variation and camera orientation.

The authors evaluate various document parsing models on a multilingual benchmark that includes both digital and photographed documents. Results show significant performance gaps between proprietary and open-source models, with notable declines on photographed documents and non-Latin-script languages. Proprietary models outperform open-source models, particularly in photographed document scenarios. Performance drops substantially on photographed documents and non-Latin-script languages across all models. Models exhibit language-specific errors, including issues with reading order, hallucinations, and incorrect segmentation.
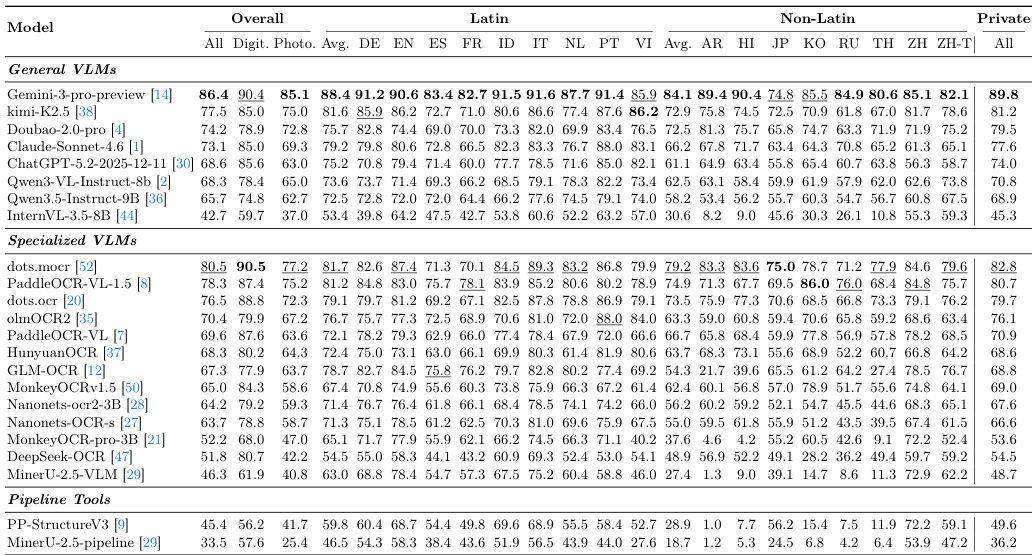
The authors evaluate various document parsing models using MDPBench, a multilingual benchmark designed to test performance across diverse image types and real-world photographic conditions. The experiments reveal that proprietary models generally outperform open-source alternatives, though all models struggle with non-Latin scripts and photographed documents compared to digital-born ones. Ultimately, the results highlight significant challenges in handling language-specific reading orders and complex photographic environments.