Command Palette
Search for a command to run...
Make It Up: 일반화된 퓨샷 시맨틱 분할에서의 가짜 이미지와 실질적 이득
Make It Up: 일반화된 퓨샷 시맨틱 분할에서의 가짜 이미지와 실질적 이득
Guohuan Xie Xin He Dingying Fan Le Zhang Ming-Ming Cheng Yun Liu
초록
일반화된 소수샷 의미 분할 (Generalized Few-Shot Semantic Segmentation, GFSS) 은 주석 데이터가 극히 제한적인 상황에서 신종 (novel class) 의 외관 범위가 부족하다는 근본적인 한계에 직면해 있습니다. 확산 모델 (Diffusion models) 은 대규모로 신종 이미지를 합성할 수 있으나, 마스크 (mask) 가 없거나 신뢰할 수 없을 때 발생하는 불충분한 범위와 노이즈가 많은 감독 신호로 인해 실제 성능 향상은 종종 저해됩니다. 이에 본 논문은 신종 커버리지를 확장하면서 가짜 라벨 (pseudo-label) 의 품질을 동시에 개선하기 위해 설계된 생성 강화형 GFSS 프레임워크인 Syn4Seg 를 제안합니다. Syn4Seg 는 먼저 각 신종별로 임베딩 중복 제거를 수행한 프롬프트 뱅크 (prompt bank) 를 구축하여 프롬프트 공간의 커버리지를 극대화함으로써, 다양하면서도 클래스 일관성을 갖춘 합성 이미지를 생성합니다. 이어지지, 지지 (support) 정보에 기반한 가짜 라벨 추정을 위해 2 단계 정제 과정을 수행합니다. 첫 번째 단계에서는 일관성이 낮은 영역을 필터링하여 고정밀 시드 (seed) 를 확보하고, 두 번째 단계에서는 전역 (지지) 및 지역 (이미지) 통계를 결합한 이미지 적응형 프로토타입 (image-adaptive prototypes) 을 활용하여 불확실한 픽셀을 재라벨링합니다. 마지막으로, 고신뢰도 내부 영역을 덮어쓰지 않으면서도 윤곽의 충실도 (contour fidelity) 를 향상시키기 위해, 경계 대역 (boundary-band) 과 라벨이 없는 픽셀에 대해서만 제약이 적용된 SAM 기반 업데이트를 수행합니다. PASCAL-5i 및 COCO-20i 에서 수행된 광범위한 실험을 통해 1-shot 및 5-shot 설정 모두에서 일관된 성능 향상을 확인하였으며, 이는 신뢰할 수 있는 마스크와 정밀한 경계를 갖춘 GFSS 를 위한 확장 가능한 경로로서 합성 데이터의 중요성을 입증합니다.
One-sentence Summary
Researchers from Nankai University and Tianjin University of Technology propose Syn4Seg, a framework that leverages Stable Diffusion to generate diverse novel-class images and employs support-guided pseudo-label refinement with SAM-based boundary correction, significantly enhancing Generalized Few-shot Semantic Segmentation performance on PASCAL-5i and COCO-20i benchmarks.
Key Contributions
- The paper introduces Syn4Seg, a generation-enhanced framework that constructs an embedding-deduplicated prompt bank to synthesize diverse, class-consistent novel-class images, thereby expanding coverage and improving generalization in Generalized Few-shot Semantic Segmentation.
- An Adaptive Pseudo-label Enhancement mechanism is presented to refine synthetic masks through a two-stage process that filters low-consistency regions and relabels uncertain pixels using image-adaptive prototypes, resulting in higher-quality supervision.
- A SAM-based Boundary Refinement module is developed to update only boundary-band and unlabeled pixels, which produces sharp, spatially coherent contours and boosts segmentation performance as demonstrated by consistent improvements on PASCAL-5i and COCO-20i benchmarks.
Introduction
Generalized few-shot semantic segmentation (GFSS) aims to segment both base and novel classes in a single inference pass, a capability critical for scalable deployment where pixel-level annotations are scarce. However, prior approaches struggle because novel classes rely on limited manual support examples, leading to poor intra-class diversity and weak generalization, while existing attempts to use Diffusion models for data augmentation often suffer from redundant image generation and noisy or misaligned segmentation masks. To overcome these hurdles, the authors propose Syn4Seg, a framework that constructs an embedding-deduplicated prompt bank to ensure diverse and class-consistent synthetic images, followed by a two-stage pseudo-label refinement process and a SAM-based boundary update to deliver high-quality supervision for robust segmentation.
Method
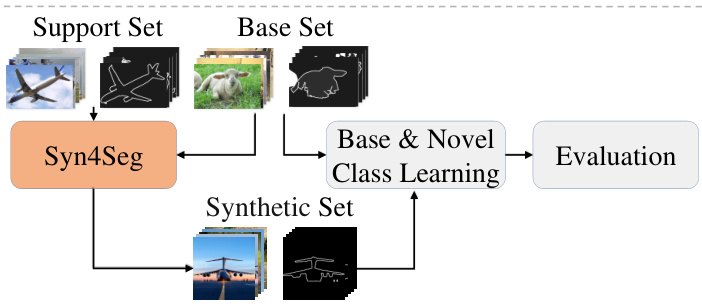
The authors propose the Syn4Seg framework to alleviate the shortage of novel class images in Generalized Few-Shot Segmentation (GFSS). The overall pipeline is illustrated in the framework diagram. The process begins with a Support Set and a Base Set. The Syn4Seg module synthesizes a Synthetic Set of novel class images. These synthetic images, along with the Base Set, are fed into a Base & Novel Class Learning module to train the final segmentation model, which is then evaluated.
To generate the synthetic images, the authors leverage High-quality Diverse Image Generation (HDIG). Direct use of class names often leads to limited diversity. HDIG addresses this by constructing a prompt set that is centered on the target class but semantically diverse. An iterative prompt generation strategy is employed where an agent generates candidate prompts. These prompts are encoded using the text encoder of Stable Diffusion 3.5-Large to ensure semantic alignment. A diversity threshold is applied to filter prompts based on cosine similarity. The maximum cosine similarity between the current candidate and existing entries is computed as: st,i=maxu∈Dt(i−1)φ~(pt,i)⊤u where φ~(p) is the normalized text embedding. A candidate prompt is accepted only if its similarity score is below a threshold λ, ensuring sufficient diversity. The accepted prompts are used to synthesize images. A qualitative comparison highlights the effectiveness of this approach, showing that HDIG produces images with substantially richer visual diversity while preserving class consistency compared to standard class-name prompts.
Once synthetic images are generated, the authors employ Adaptive Pseudo-label Enhancement (APE) to produce high-quality masks, as the initial masks from the GFSS network are often noisy. Refer to the detailed module diagram for the internal structure of APE. APE comprises two stages: Adaptive Pseudo-label Filtering (APF) and Adaptive Pseudo-label Relabeling (APR). In the APF stage, the method discards unreliable pseudo-labels by assessing the alignment between predicted regions and support prototypes. The prototype for novel class k is computed by averaging features over pixels labeled as k: μk=∑j∑p1[Mj(p)=k]1∑j∑p1[Mj(p)=k]fj(p) For a region r, the cosine similarity with the class prototype is calculated as s(r)=v^(r)⊤μ^k. If s(r)≥λ, the region is kept; otherwise, it is marked as free. In the APR stage, these free regions are adaptively relabeled using a blend of global support prototypes and image-local prototypes. The adaptive prototype for image x is given by: μ~k(x)=βμ^k+(1−β)μ^k(x) where β controls the influence of the global prototype. This ensures that the mask retains trustworthy labels while filling in uncertain areas with high-confidence predictions.
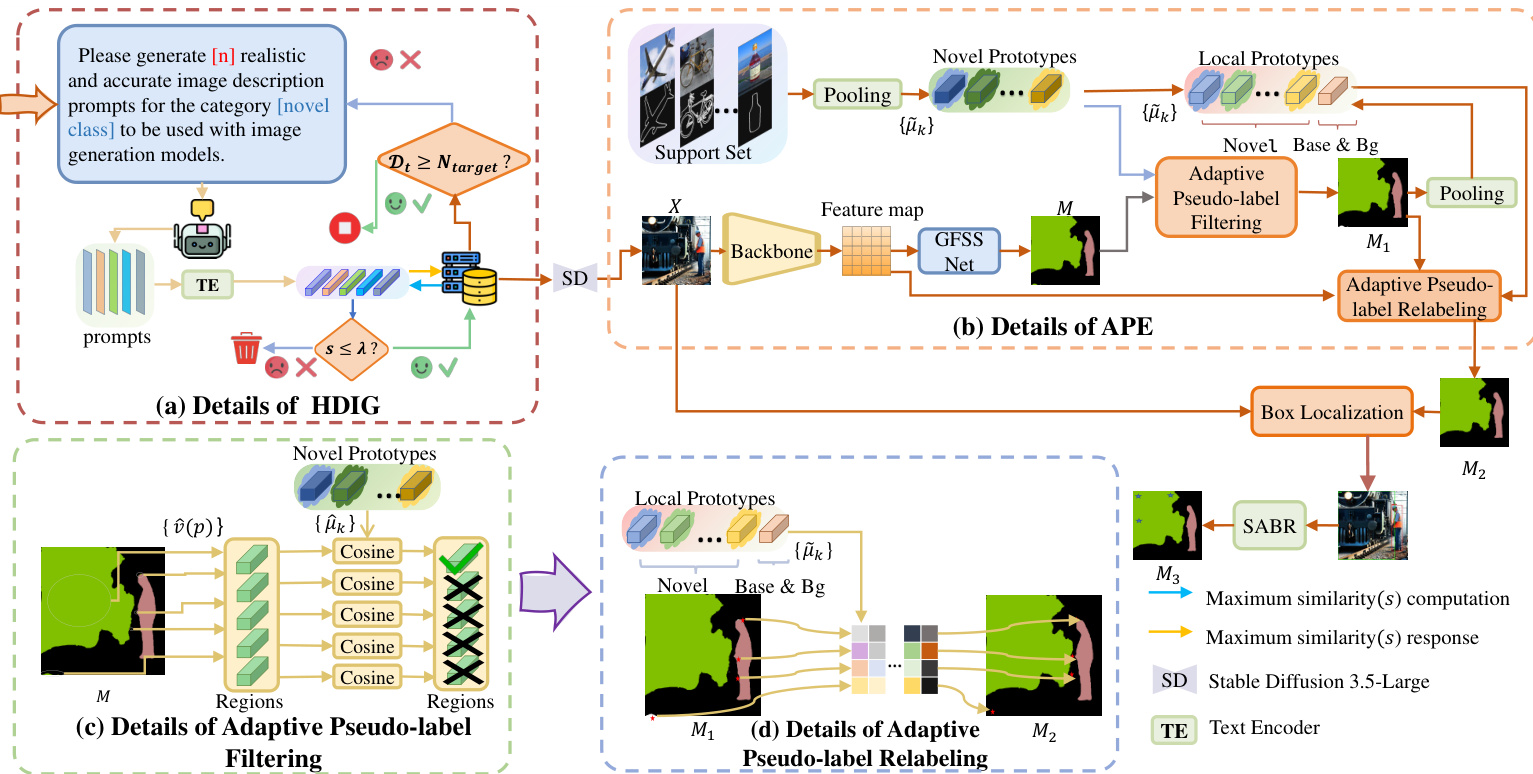
Finally, to address imprecise object boundaries, the authors apply SAM-based Boundary Refinement (SABR). This module utilizes the Segment Anything Model (SAM) to refine the mask boundaries. By identifying boundary pixels and computing tight bounding boxes, SAM is guided to produce binary foreground predictions. Updates are restricted to uncertain regions to prevent overwriting high-confidence interiors. This process yields the final training mask with substantially improved boundary fidelity, ready for downstream segmentation training.
Experiment
- Experiments on PASCAL-5i and COCO-20i benchmarks validate that the proposed Syn4Seg method significantly outperforms state-of-the-art approaches in both 1-shot and 5-shot settings, achieving superior mean and harmonic mIoU scores.
- Qualitative analysis demonstrates that the method generates more coherent and complete segmentation masks for novel classes while reducing fragmented predictions and spurious regions compared to existing techniques.
- Ablation studies confirm that enhancing image diversity through HDIG provides broader appearance cues, while the APE module improves mask precision by filtering misaligned regions and relabeling ambiguous areas.
- The inclusion of SABR effectively refines object boundaries and resolves local ambiguities, leading to the best overall segmentation consistency across base and novel classes.
- Hyperparameter analysis reveals that moderate values for prototype blending and thresholding optimize the balance between synthesized information and generalization, while the method remains robust to variations in boundary refinement parameters.
- Testing with a deeper ResNet-101 backbone shows consistent performance gains, indicating that stronger feature extraction benefits fine-grained detail capture without the method being overly dependent on backbone depth.