Command Palette
Search for a command to run...
LLM 기반 다화자 음성 인식을 위한 게이트드 크로스 어텐션 어댑터를 활용한 2 단계 음향 적응
LLM 기반 다화자 음성 인식을 위한 게이트드 크로스 어텐션 어댑터를 활용한 2 단계 음향 적응
Hao Shi Yuan Gao Xugang Lu Tatsuya Kawahara
초록
대형 언어 모델(LLM) 은 두 화자 자동 음성 인식 (ASR) 에서 직렬화된 출력 학습 (SOT) 을 위한 강력한 디코더로 작용하나, 세 화자가 혼합된 것과 같은 까다로운 조건에서는 성능이 현저히 저하됩니다. 주요 한계점은 현재 시스템이 음향 증거를 투영된 접두사 (projected prefix) 를 통해서만 주입한다는 점인데, 이는 정보 손실이 발생할 수 있으며 LLM 입력 공간과 완벽하게 정렬되지 않아 디코딩 과정에서 미세한 수준의 그라운딩 (grounding) 을 제공하지 못합니다. 이러한 한계를 해결하는 것은, 특히 세 화자 혼합 환경에서 견고한 다화자 ASR 을 구현하는 데 중요합니다. 본 논문은 화자 인식형 음향 증거를 디코더에 명시적으로 주입함으로써 LLM 기반 다화자 ASR 을 개선합니다. 먼저, Connectionist Temporal Classification(CTC) 에서 유도된 접두사 프롬프팅 (prefix prompting) 을 재검토하고 음향 정보가 점진적으로 증가하는 세 가지 변형을 비교 분석합니다. 여기서 사용되는 CTC 정보는 기존 연구에서 제안된 직렬화 CTC(serialized CTC) 를 통해 획득합니다. 음향이 풍부한 프롬프트는 SOT 전용 베이스라인보다 우수한 성능을 보이지만, 접두사 조건부 입력만으로는 세 화자 혼합 환경에서 충분하지 않습니다. 이에 따라 경량 게이트형 잔차 교차 어텐션 어댑터 (gated residual cross-attention adapter) 를 제안하고, 저랭크 어댑트 (LoRA) 를 기반으로 한 2 단계 음향 적응 프레임워크를 설계합니다. 1 단계에서는 자기 어텐션 서브레이어 이후에 게이트형 교차 어텐션 어댑터를 삽입하여 음향 임베딩을 외부 메모리로 안정적으로 주입합니다. 2 단계에서는 파라미터 효율적인 LoRA 를 활용하여 교차 어텐션 어댑터와 사전 학습된 LLM 의 자기 어텐션 프로젝션 모두를 정제함으로써, 제한된 데이터 하에서도 대규모 백본의 견고성을 향상시킵니다. 학습된 업데이트는 추론 시 기본 가중치에 병합됩니다. 깨끗한 조건과 잡음 조건 하에서 Libri2Mix/Libri3Mix 데이터셋에 대한 실험 결과는 일관된 성능 향상을 보여주며, 특히 세 화자 설정에서 두드러진 개선 효과를 확인했습니다.
One-sentence Summary
Authors from IEEE-affiliated institutions propose a two-stage acoustic adaptation framework for LLM-based multi-talker ASR that injects talker-aware evidence via gated cross-attention adapters and LoRA refinement, significantly improving robustness in challenging three-talker mixtures where standard prefix prompting fails.
Key Contributions
- The paper introduces a systematic comparison of three Connectionist Temporal Classification (CTC)-derived prefix variants with increasing acoustic content to evaluate their effectiveness in providing explicit guidance for Large Language Model (LLM) decoders in multi-talker settings.
- A lightweight gated residual cross-attention adapter is proposed to inject talker-aware acoustic embeddings as external memory after the self-attention sub-layer, enabling dynamic access to fine-grained acoustic evidence at every decoding step.
- A two-stage acoustic adaptation framework utilizing low-rank updates (LoRA) is presented to refine both the cross-attention adapters and pretrained LLM self-attention projections, with experiments on Libri2Mix and Libri3Mix demonstrating consistent performance gains, particularly in challenging three-talker mixtures.
Introduction
Large Language Models (LLMs) serve as powerful decoders for Serialized Output Training in multi-talker Automatic Speech Recognition, yet their performance drops significantly when handling complex three-talker mixtures. Prior approaches rely on projecting acoustic evidence into a static prefix, which often results in lossy representations that fail to provide the fine-grained grounding needed to disentangle densely interleaved speech streams. To address this, the authors propose a two-stage acoustic adaptation framework that injects talker-aware acoustic evidence directly into the LLM decoder using a lightweight gated residual cross-attention adapter. They further refine both the adapter and the LLM's self-attention projections with parameter-efficient LoRA updates, ensuring stable training and robust performance even under limited data conditions.
Dataset
-
Dataset Composition and Sources: The authors evaluate their models on LibriMix, a benchmark for overlapped-speech recognition built upon the LibriSpeech corpus. Additive noise for noisy conditions is sampled from the WHAM! corpus.
-
Subset Details:
- Libri2Mix: Synthesized from the train-clean-100, train-clean-360, dev-clean, and test-clean subsets of LibriSpeech using official scripts and standard ESPnet offset settings for two-talker configurations. The training set contains approximately 270 hours of speech, while the development and test sets each contain about 11 hours.
- Libri3Mix: Generated using custom offset files to ensure diverse onset-time configurations for three-talker mixtures. The training set comprises approximately 186 hours of speech, with development and test sets holding about 11 hours each.
-
Usage in Model Training: The authors follow the official LibriMix protocol to generate both Libri2Mix and Libri3Mix mixtures. These datasets serve as the primary evaluation benchmark, with the training splits used for model optimization and the development and test splits for performance assessment.
-
Processing and Metadata: The team utilized official LibriMix scripts to synthesize clean mixtures and applied specific offset files to control talker onset times. While standard settings were used for two-talker scenarios, custom offset files were constructed for three-talker mixtures to increase configuration diversity, with these files scheduled for release after the review period.
Method
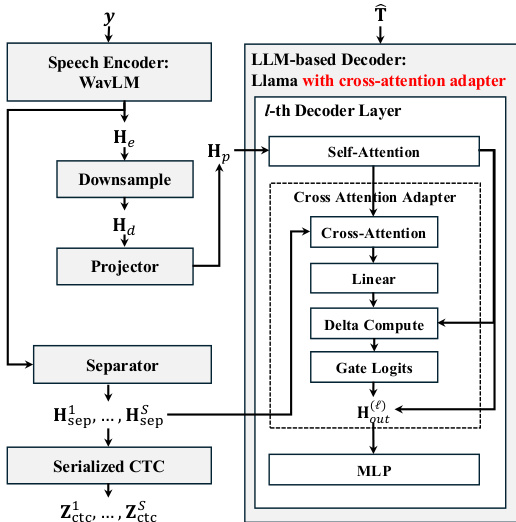
The authors propose a framework for LLM-based multi-talker ASR that integrates acoustic evidence directly into the decoder. The system consists of a speech encoder, a separator for talker-specific streams, and an LLM decoder enhanced with a cross-attention adapter.
Refer to the framework diagram for the overall architecture. The input waveform y is processed by a Speech Encoder (WavLM) to produce frame-level representations He. These features undergo temporal reduction via downsampling to Hd and are projected to the LLM hidden dimension Hp. Simultaneously, a Separator module processes the encoder output to generate S talker-specific streams Hsep1,…,HsepS, which are also used for Serialized CTC supervision.
The LLM-based Decoder, based on Llama, incorporates a specialized Cross Attention Adapter within each decoder layer. As shown in the figure below, the adapter is inserted after the Self-Attention sub-layer. It takes the hidden states from self-attention as queries and the projected acoustic memory as keys and values. The adapter computes a context vector which is then processed through a Linear layer and a Delta Compute block. A Gate Logits mechanism controls the residual update, ensuring that the acoustic information is injected without disrupting the pre-trained language representations.
The training process follows a two-stage adaptation strategy designed to balance semantic initialization with robust acoustic conditioning. The pipeline and motivations for each stage are illustrated in the figure below.
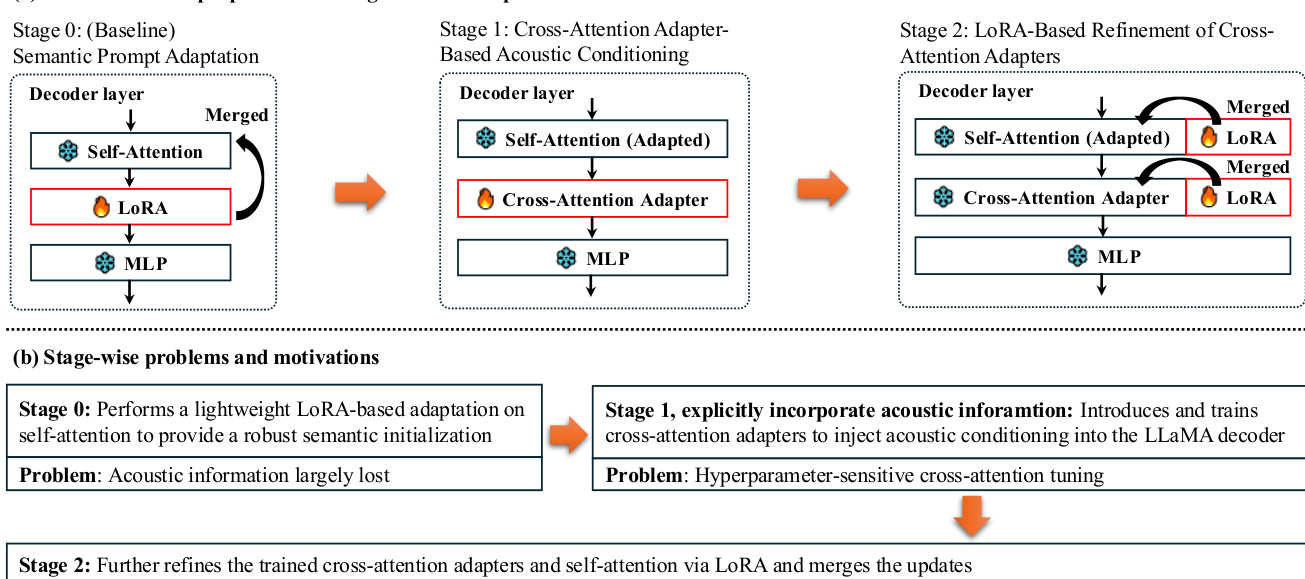
Stage 0 serves as a baseline where the LLM decoder is adapted using LoRA on the self-attention projections. This provides a robust semantic initialization without explicit acoustic injection. Stage 1 introduces the gated cross-attention adapter to explicitly incorporate acoustic information. This stage trains the adapter to inject talker-aware acoustic evidence into the decoder via a gated residual update. However, training these adapters can be hyperparameter-sensitive. To address this, Stage 2 applies LoRA-based refinement to both the cross-attention adapters and the self-attention projections. This refinement strengthens the adaptation capacity and improves robustness under limited data. Finally, the learned low-rank updates are merged into the base weights, resulting in a model with no additional parameters at inference time.
Experiment
- LLM-based systems significantly improve performance on two-talker mixtures by leveraging semantic priors but struggle with three-talker scenarios due to insufficient context resolution in static prefix conditioning.
- Acoustic-rich prefixes outperform text-only prompts by providing better constraints for LLM decoding, yet one-shot prefixing alone remains inadequate for fine-grained talker assignment in heavily overlapped speech.
- Decoder-side acoustic injection via cross-attention yields substantial gains in three-talker conditions by enabling step-wise access to acoustic memory, whereas naive stacked cross-attention can degrade performance in easier two-talker settings due to over-conditioning.
- Gated cross-attention adaptation offers more stable and effective acoustic conditioning than naive stacking by regulating injection levels and preserving pretrained language representations, though it still lags behind serialized CTC alignment in the most challenging regimes.
- Stage-2 LoRA refinement enhances robustness and reduces hyperparameter sensitivity, with joint refinement of cross-attention adapters and self-attention projections consistently delivering the best overall results, particularly for 3B-scale backbones.
- The proposed method achieves a clear advantage over existing pipelines in three-talker settings, and larger LLM decoders consistently outperform models trained from scratch even when using serialized CTC references.