Command Palette
Search for a command to run...
DataFlex: 대규모 언어 모델의 데이터 중심 동적 훈련을 위한 통합 프레임워크
DataFlex: 대규모 언어 모델의 데이터 중심 동적 훈련을 위한 통합 프레임워크
초록
데이터 중심 학습(Data-centric training)은 모델 파라미터 최적화뿐만 아니라 최적화 과정 중 훈련 데이터의 선택, 구성, 가중치 부여를 동시에 최적화함으로써 대규모 언어 모델(LLM)의 성능을 향상시킬 수 있는 유망한 방향으로 부상하고 있습니다. 그러나 기존 데이터 선택, 데이터 혼합 최적화, 데이터 재가중치 기법들은 종종 서로 격리된 코드베이스에서 개발되어 인터페이스가 일관되지 않아 재현성 확보, 공정한 비교, 실용적인 통합을 저해하고 있습니다. 본 논문에서는 LLaMA-Factory 를 기반으로 구축된 통합된 데이터 중심 동적 학습 프레임워크인 DataFlex 를 제안합니다. DataFlex 는 샘플 선택, 도메인 혼합 조정, 샘플 재가중치라는 세 가지 주요 동적 데이터 최적화 패러다임을 지원하면서도 원래의 학습 워크플로우와 완전히 호환됩니다. 또한 확장 가능한 트레이너 추상화 및 모듈형 컴포넌트를 제공하여 표준 LLM 학습에 대한 플러그인 형태의 대체를 가능하게 하며, 임베딩 추출, 추론(Inference), 그라디언트 계산과 같은 모델 의존적 핵심 연산을 통합합니다. 아울러 DeepSpeed ZeRO-3 를 포함한 대규모 설정도 지원합니다. 우리는 다양한 데이터 중심 기법들을 대상으로 포괄적인 실험을 수행했습니다. 동적 데이터 선택은 Mistral-7B 와 Llama-3.2-3B 모두에서 정적 전체 데이터 학습 대비 MMLU 성능을 일관되게 향상시켰습니다. 데이터 혼합의 경우, DoReMi 와 ODM 은 SlimPajama 에서 Qwen2.5-1.5B 를 6B 토큰 및 30B 토큰 규모로 사전 학습시킬 때 기본 비율 대비 MMLU 정확도와 코퍼스 수준의 퍼플렉시티(Perplexity) 를 모두 개선했습니다. 또한 DataFlex 는 기존 구현 대비 일관된 런타임 개선을 달성했습니다. 이러한 결과는 DataFlex 가 LLM 의 데이터 중심 동적 학습을 위한 효과적이고 효율적이며 재현 가능한 인프라를 제공함을 입증합니다.
One-sentence Summary
Researchers from Peking University and Shanghai Artificial Intelligence Laboratory present DATAFLEX, a unified framework built on LLaMA-Factory that integrates data selection, mixture optimization, and reweighting into a single dynamic training paradigm, enabling scalable, reproducible large language model optimization with superior performance over static baselines.
Key Contributions
- The paper introduces DATAFLEX, a unified framework built on LLaMA-Factory that supports dynamic sample selection, domain mixture adjustment, and sample reweighting through extensible trainer abstractions and modular algorithm components.
- This work unifies common model-dependent operations such as embedding extraction, model inference, and gradient computation while maintaining full compatibility with large-scale training settings like DeepSpeed ZeRO-3.
- Experiments demonstrate that the framework achieves consistent performance gains over static training and default data proportions across multiple backbones and datasets, while also delivering runtime improvements over original method-specific implementations.
Introduction
Large language model training is increasingly shifting toward data-centric approaches that optimize data selection, mixture, and weighting alongside model parameters to improve efficiency and performance. However, prior work suffers from significant fragmentation, as existing methods are often isolated in separate codebases with inconsistent interfaces that hinder reproducibility, fair comparison, and integration into scalable pipelines. The authors leverage the widely adopted LLaMA-Factory to introduce DATAFLEX, a unified framework that standardizes data-centric dynamic training by supporting selection, mixture adjustment, and reweighting through modular trainer abstractions. This system unifies shared model-dependent operations like embedding extraction and gradient computation while remaining compatible with large-scale training setups such as DeepSpeed ZeRO-3, enabling both systematic research evaluation and practical deployment.
Dataset
-
Dataset Composition and Sources: The authors utilize SlimPajama, a large-scale deduplicated English pretraining corpus derived from RedPajama. This dataset aggregates seven text domains: CommonCrawl (CC), C4, GitHub, Book, ArXiv, Wikipedia, and StackExchange (SE).
-
Subset Details and Filtering: Two subsets are employed to evaluate training budgets at different token scales: SlimPajama-6B and SlimPajama-30B. Both subsets are randomly sampled to strictly preserve the natural token-level domain proportions of the original corpus, which are CommonCrawl (54.1%), C4 (28.7%), GitHub (4.2%), Book (3.7%), ArXiv (3.4%), Wikipedia (3.1%), and StackExchange (2.8%). These natural proportions serve as the default baseline mixture and the initial weights for dynamic optimization methods.
-
Training Usage and Mixture Ratios: The authors train Qwen2.5 models from scratch with random initialization to isolate the effects of data mixture strategies. The baseline uses a static mixer with default SlimPajama proportions. The DoReMi method follows a three-step procedure where a reference model and proxy model are trained to compute per-domain excess losses, resulting in optimized static weights for the target model that notably increase high-quality domains like Book and Wikipedia while reducing CommonCrawl dominance. The Online Data Mixing (ODM) approach dynamically adjusts domain weights during a single training pass using the Exp3 multi-armed bandit algorithm without a separate reference model.
-
Processing and Configuration Details: All experiments train for one full epoch with a linear learning rate decay and a 5% warmup ratio. The Qwen tokenizer is applied to all models, and a fixed random seed of 42 is used. Training runs utilize BFloat16 mixed precision, DeepSpeed ZeRO Stage-3 for memory efficiency, and FlashAttention-2 for attention computation. The 6B-token experiments run on a single node with 8 GPUs, while the 30B-token experiments scale to 4 nodes with 32 H20 GPUs in total.
Method
The authors propose DATAFLEX, a unified data-centric dynamic training framework designed to treat data as a first-class optimization variable. The system is built upon LLaMA-Factory and is structured into three primary layers to support dynamic control over data selection, mixture, and weighting.
Refer to the framework diagram for the high-level architecture. The Base Layer, labeled as (a), is inherited directly from LLaMA-Factory, providing standard infrastructure for model management, data processing, and optimizers. It also integrates parallel optimization strategies such as DeepSpeed and FSDP to ensure scalability.
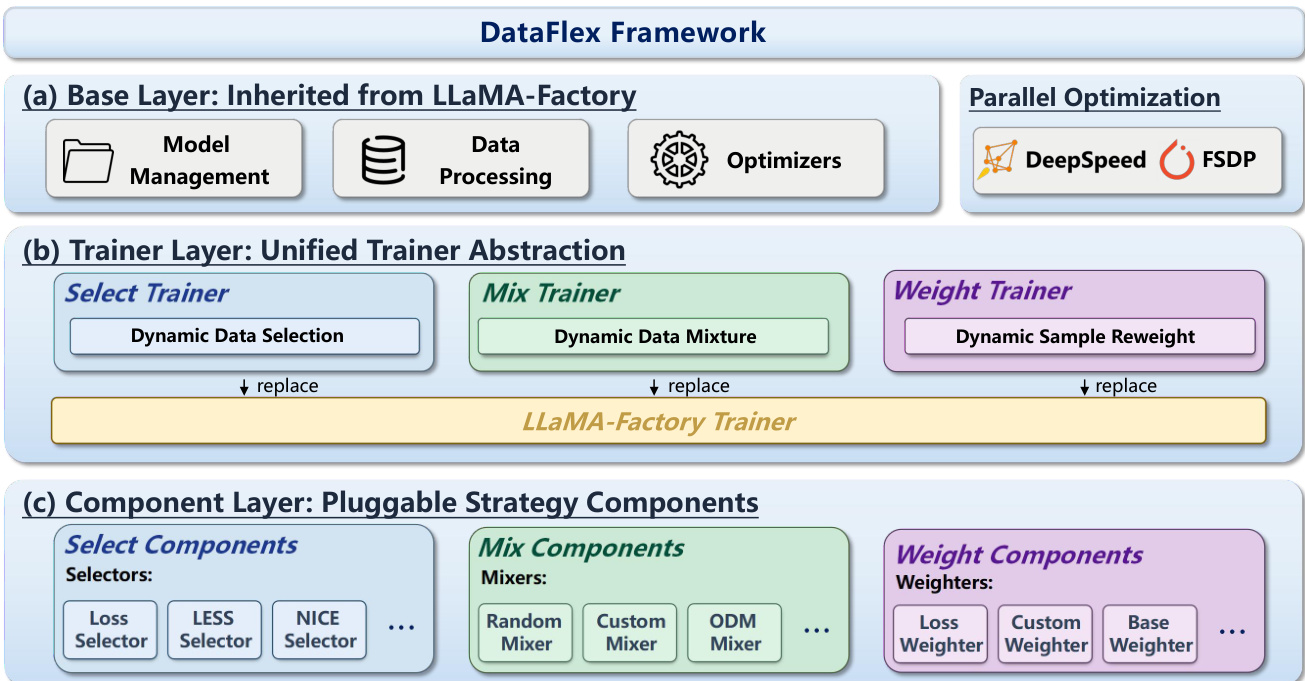
At the core of the system is the Trainer Layer, labeled as (b), which implements a unified trainer abstraction. This layer replaces the original LLaMA-Factory trainer with three specialized dynamic training modes: the Select Trainer for dynamic data selection, the Mix Trainer for dynamic data mixture, and the Weight Trainer for dynamic sample reweighting. Each mode corresponds to a specific paradigm of data-centric optimization.
Beneath the trainer layer lies the Component Layer, labeled as (c), which consists of pluggable strategy components. The Select Trainer utilizes Selectors (e.g., Loss Selector, LESS Selector), the Mix Trainer employs Mixers (e.g., Random Mixer, ODM Mixer), and the Weight Trainer uses Weighters (e.g., Loss Weighter). These components encapsulate algorithm-specific logic while sharing a common interface. During training, the trainer invokes its associated component to generate control signals, such as sample subsets, domain mixing ratios, or per-sample weights, which are then fed back into the optimization process. This modular design allows researchers to implement and compare new data-centric algorithms with minimal engineering overhead while maintaining compatibility with existing large-scale training workflows.
Experiment
- Experiments on data selection and reweighting validate that dynamic, model-aware methods (such as LESS and Reweight) consistently outperform static full-data training baselines on both Mistral-7B and Llama-3.2-3B, with the performance gap widening for smaller models where dynamic selection is critical.
- Offline selection methods demonstrate faster early convergence due to precomputed high-value samples, while online methods achieve superior final accuracy by adapting to evolving model gradients.
- Data mixture experiments confirm that dynamic optimization strategies (DoReMi and ODM) improve both MMLU accuracy and perplexity compared to static baselines, with DoReMi excelling in high-resource domains and ODM effectively upweighting specialized, underrepresented domains.
- Efficiency evaluations show that the DATAFLEX framework reduces runtime for both online (LESS) and offline (TSDS) selection algorithms compared to original implementations, while uniquely enabling multi-GPU parallel scalability for online selection to handle large-scale datasets.