Command Palette
Search for a command to run...
ViGoR-Bench: 시각 생성 모델이 제로샷 시각 추론기에 얼마나 가까운가?
ViGoR-Bench: 시각 생성 모델이 제로샷 시각 추론기에 얼마나 가까운가?
Haonan Han Jiancheng Huang Xiaopeng Sun Junyan He Rui Yang Jie Hu Xiaojiang Peng Lin Ma Xiaoming Wei Xiu Li
초록
현대 AIGC 모델이 보여주는 놀라운 시각적 충실도 이면에는 물리적, 인과적 또는 복잡한 공간 추론이 필요한 과제에서 실패하는 '논리적 사막'이 존재합니다. 현재의 평가는 대부분 피상적인 지표나 단편적인 벤치마크에 의존하여 생성 과정을 간과하는 '성능 기미지(performance mirage)'를 조성해 왔습니다. 이를 해결하기 위해 우리는 ViGoR(Vision-Generative Reasoning-centric Benchmark)을 소개합니다. ViGoR은 이러한 기미지를 해체하도록 설계된 통합 프레임워크입니다. ViGoR은 네 가지 핵심 혁신을 통해 차별화됩니다: 1) Image-to-Image 및 Video 작업을 연결하는 전체적 교차모달 커버리지, 2) 중간 과정과 최종 결과를 모두 평가하는 듀얼 트랙 메커니즘, 3) 높은 인간 정렬성을 보장하는 증거 기반 자동 평가자, 4) 성능을 세분화된 인지 차원으로 분해하는 미세 진단 분석. 20 개 이상의 선도적 모델을 대상으로 한 실험 결과, 최첨단 시스템조차도 상당한 추론 결함을 안고 있음이 드러났으며, 이는 ViGoR을 차세대 지능형 비전 모델에 대한 핵심적인 '스트레스 테스트'로 자리매김하게 합니다. 데모는 https://vincenthancoder.github.io/ViGoR-Bench/ 에서 이용 가능합니다.
One-sentence Summary
Researchers from Tsinghua University and other institutions introduce ViGoR, a unified benchmark that evaluates vision generative models through holistic cross-modal coverage and dual-track process analysis, exposing significant reasoning deficits in state-of-the-art systems to guide future intelligent vision development.
Key Contributions
- The paper introduces ViGoR, a unified benchmark framework that bridges Image-to-Image and Video tasks to provide holistic cross-modal coverage across 20 distinct cognitive dimensions.
- A dual-track evaluation mechanism is implemented to assess both intermediate generative processes and final results, ensuring that outputs adhere to physical laws and causal consistency rather than just visual fidelity.
- An evidence-grounded automated judge system is presented to mitigate evaluator subjectivity, achieving high alignment with human experts while enabling granular diagnostic analysis of specific reasoning failures.
Introduction
Modern AIGC models achieve impressive visual fidelity but often fail at tasks requiring physical, causal, or complex spatial reasoning, a deficit obscured by traditional metrics like CLIP-Score and FID that prioritize statistical similarity over structural integrity. Existing benchmarks remain fragmented across specific modalities like Image-to-Image or Video generation and typically evaluate only final outputs while ignoring the generative process, creating a "performance mirage" that masks logical gaps. To address these challenges, the authors introduce ViGoR-Bench, a unified framework that bridges cross-modal tasks and employs a dual-track mechanism to evaluate both intermediate reasoning steps and final results. This approach utilizes an evidence-grounded automated judge to ensure high alignment with human experts and provides granular diagnostic analysis to pinpoint specific cognitive failures in state-of-the-art systems.
Dataset
-
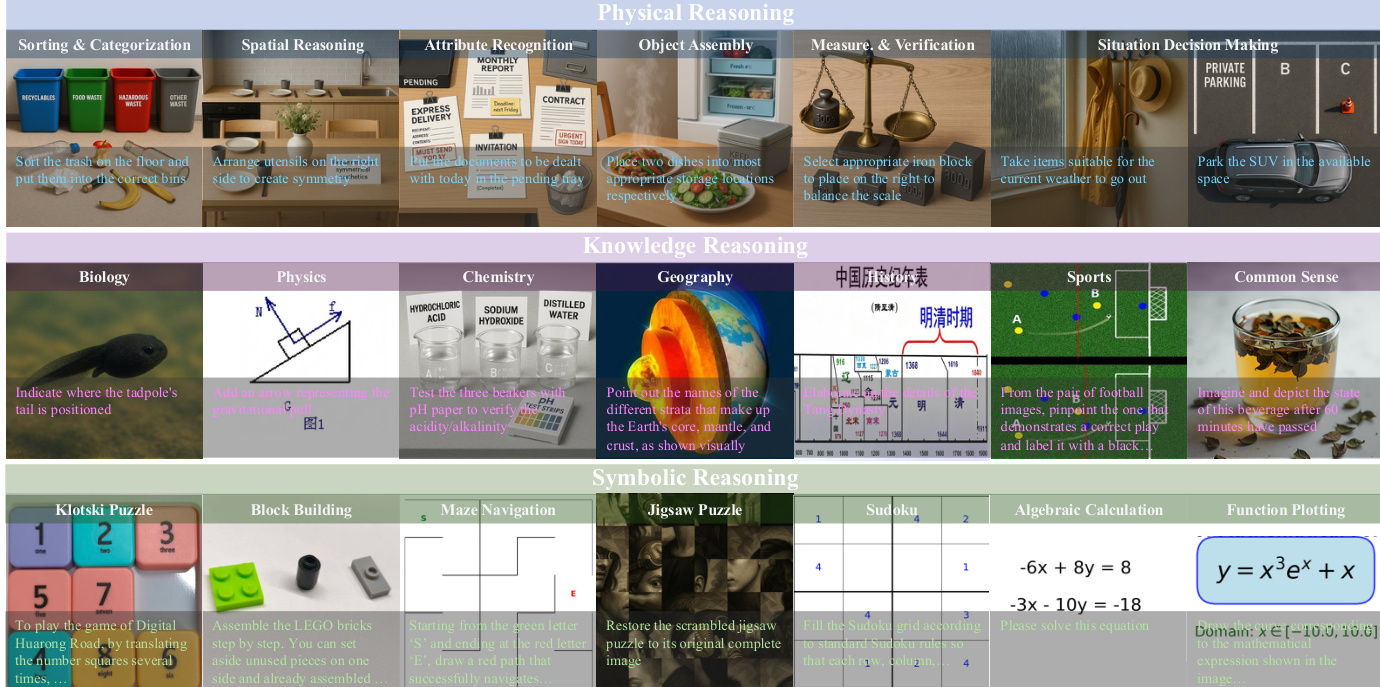
Dataset Composition and Sources The authors constructed ViGoR-Bench, a diverse benchmark designed to evaluate reasoning capabilities across three primary domains: Physical Reasoning, Knowledge Reasoning, and Symbolic Reasoning. The dataset spans 20 distinct subdomains and integrates three distinct construction paradigms: Generative Synthesis using LLMs and image generation models, Real-world Acquisition via authoritative web curation and manual photography, and Algorithmic Construction using rule-based engines.
-
Key Details for Each Subset
- Physical Reasoning: This subset covers tasks like sorting, spatial reasoning, and object assembly. Due to the complexity of acquiring real-world embodied data, the authors employ a generative pipeline where LLMs enrich textual descriptions to prompt state-of-the-art image generators like NanoBanana-Pro. These subsets lack ground-truth images; instead, they provide human-verified textual ground-truth answers to ensure logical consistency.
- Knowledge Reasoning: Focusing on disciplines such as Biology, Physics, and History, this data is curated from authoritative educational websites and scientific repositories. While some samples preserve original ground-truth images (e.g., before-and-after phenomena), others rely solely on human-verified textual answers.
- Symbolic Reasoning: This domain requires precise logical manipulation. For physical puzzles like Klotski and Block Building, data is collected in physical environments with annotators capturing solved states as ground-truth images. For abstract tasks like Sudoku, Maze Navigation, and Function Plotting, the authors use rule-based algorithms to generate input and ground-truth images with mathematical rigor. Algebraic calculation tasks involve generating equations via LLMs and validating solutions with symbolic solvers before rendering them as images.
-
Data Usage and Processing The benchmark is not used for model training but serves as a comprehensive evaluation suite. The authors utilize a rigorous post-processing verification stage that includes human-in-the-loop reviews for semantic consistency and symbolic solver validation for mathematical precision. Unlike previous benchmarks, ViGoR-Bench provides both referenced ground-truth images and human-verified ground-truth captions where applicable to ensure objectivity.
-
Metadata and Evaluation Structure The dataset structure organizes inputs into a specific sequence: an initial input image, a sequence of middle frames representing the model's step-by-step reasoning or action execution, and an optional final ground-truth reference image. The evaluation framework distinguishes between Chain-of-Thought (CoT) tasks, which assess the full temporal sequence of model outputs, and binary tasks, which evaluate the final output image. Evaluation dimensions include Background Consistency, Rule Obey, Beneficial Action, and Visual Quality, with scores calculated as integers or binary values based on visual observation and comparison against ground-truth descriptions.
Method
The authors propose a comprehensive framework for evaluating visual reasoning capabilities, centered around the construction of the ViGoR-Bench and a rigorous evaluation pipeline. The overall architecture is depicted in the framework diagram, which outlines both the data collection and evaluation processes.
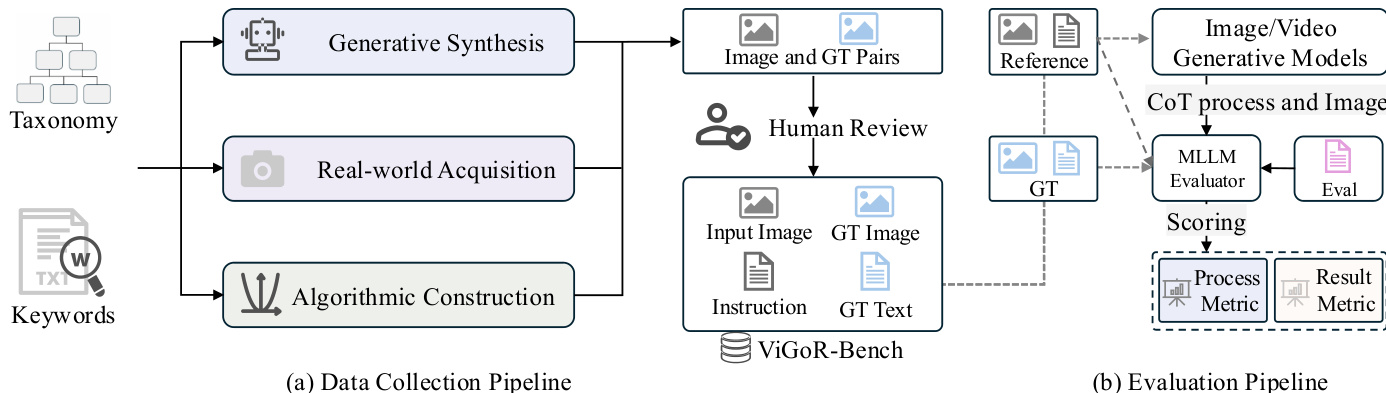
To ensure diversity and quality, the benchmark is constructed through three primary channels: Generative Synthesis, Real-world Acquisition, and Algorithmic Construction. These sources feed into a process that generates Image and Ground Truth (GT) Pairs. These pairs undergo Human Review to ensure accuracy before being finalized into the ViGoR-Bench dataset, which includes Input Images, Instructions, GT Images, and GT Text. The evaluation pipeline leverages Image/Video Generative Models to produce outputs based on the benchmark instructions. These outputs are then assessed by an MLLM Evaluator, which compares the model's output against the Ground Truth and the original instruction to produce Process and Result Metrics.
The benchmark categorizes visual reasoning tasks into three main domains: Physical Reasoning, Knowledge Reasoning, and Symbolic Reasoning. As illustrated in the taxonomy overview, Physical Reasoning involves tasks like object assembly and spatial arrangement. Knowledge Reasoning covers domains such as Biology, Physics, and Geography. Symbolic Reasoning includes challenges like Sudoku, Maze Navigation, and Function Plotting.

Specific task instances are visualized in the task examples grid, demonstrating diverse challenges like sorting recyclables, solving algebraic equations, and navigating mazes.
To standardize the assessment, the authors employ specific binary templates tailored to different reasoning types. For Knowledge Reasoning tasks, the evaluation focuses on four binary dimensions: Background Consistency, Rule Obey, Reasoning Accuracy, and Visual Quality. The template requires the evaluator to output a strict JSON format detailing the score and explanation for each dimension.

Similarly, for Physical Reasoning tasks, a dedicated template is used to assess the model's ability to perform embodied actions and physical manipulations. This template evaluates whether the model preserves the environment, follows specific rules (e.g., sorting criteria), and achieves the correct final state, while also maintaining high visual quality.

Experiment
- A dual-track evaluation protocol was established to assess both the logical coherence of intermediate reasoning steps and the validity of final solutions across physical, knowledge, and symbolic reasoning domains.
- Reliability analysis confirmed that the VLM-as-a-Judge pipeline achieves high alignment with human experts, demonstrating that providing Ground Truth references is critical for stabilizing automated judgments.
- Main experiments revealed that proprietary models significantly outperform open-source counterparts, with only top-tier models capable of handling complex physical and symbolic reasoning tasks without hallucinations.
- Qualitative findings indicate that while explicit Chain-of-Thought prompting improves process interpretability, it does not guarantee higher final accuracy due to error accumulation and execution limitations.
- Video generation models were found to exhibit an "illusion of reasoning," maintaining high visual quality and temporal consistency but failing to satisfy strict logical constraints required for task completion.
- Post-training experiments demonstrated that Reinforcement Learning on high-complexity data yields superior generalization and reasoning success compared to Supervised Fine-Tuning, enabling models to surpass state-of-the-art proprietary baselines.
- Capability profiling highlighted a persistent gap where models maintain high visual quality but struggle with rule obedience and reasoning accuracy in multi-step symbolic and embodied tasks.