Command Palette
Search for a command to run...
PackForcing: 짧은 비디오 학습이 긴 비디오 샘플링 및 긴 문맥 추론에 충분하다
PackForcing: 짧은 비디오 학습이 긴 비디오 샘플링 및 긴 문맥 추론에 충분하다
Xiaofeng Mao Shaohao Rui Kaining Ying Bo Zheng Chuanhao Li Mingmin Chi Kaipeng Zhang
초록
자가회귀적 비디오 확산 모델 (autoregressive video diffusion models) 은 괄목할 만한 진전을 보여주고 있으나, 장편 비디오 생성 과정에서 해결하기 어려운 선형 KV-cache 성장, 시간적 반복, 그리고 누적 오차로 인해 여전히 병목 현상에 직면해 있습니다. 이러한 과제를 해결하기 위해 우리는 생성 이력을 효율적으로 관리하기 위한 새로운 3 영역 KV-cache 전략을 도입한 통합 프레임워크인 PackForcing 을 제안합니다. 구체적으로, 우리는 과거 문맥을 세 가지 유형으로 분류합니다: (1) Sink tokens: 전역 의미론을 유지하기 위해 초기 앵커 프레임을 풀 해상도로 보존하는 토큰; (2) Mid tokens: 점진적 3D 합성곱과 저해상도 VAE 재인코딩을 융합한 듀얼 브랜치 네트워크를 통해 대규모 시공간 압축 (토큰 32 배 감소) 을 달성하는 토큰; (3) Recent tokens: 국소적 시간적 일관성을 확보하기 위해 풀 해상도로 유지되는 토큰입니다. 품질 저하 없이 메모리 사용량을 엄격히 제한하기 위해, 우리는 Mid tokens 에 대한 동적 top-k 문맥 선택 메커니즘을 도입하고, 버려진 토큰으로 인한 위치 간격을 거의 오버헤드 없이 원활하게 재정렬하는 연속적인 Temporal RoPE 조정을 결합하였습니다. 이러한 원칙에 기반한 계층적 문맥 압축을 통해 PackForcing 은 단일 H200 GPU 에서 16 FPS 속도로 2 분, 832x480 해상도의 일관된 비디오를 생성할 수 있습니다. 이는 단지 4 GB 의 한정된 KV-cache 를 구현하며, 제로샷 (zero-shot) 방식으로 또는 불과 5 초 클립으로만 학습된 경우에도 효과적으로 작동하여 5 초에서 120 초까지 24 배의 시간적 외삽 (temporal extrapolation) 을 가능하게 합니다. VBench 에 대한 광범위한 실험 결과는 최첨단 수준의 시간적 일관성 (26.07) 과 역동성 (56.25) 을 입증하여, 고품질 장편 비디오 합성을 위해 짧은 비디오 감독 (supervision) 만으로도 충분함을 보여줍니다. https://github.com/ShandaAI/PackForcing
One-sentence Summary
Researchers from Alaya Studio, Fudan University, and Shanghai Innovation Institute present PackForcing, a framework that enables long-video generation by compressing historical KV caches into three partitions. This approach achieves 24x temporal extrapolation from short clips while maintaining state-of-the-art coherence on a single GPU.
Key Contributions
- The paper introduces PackForcing, a unified framework that partitions generation history into sink, compressed, and recent tokens to bound per-layer attention to approximately 27,872 tokens regardless of video length.
- A hybrid compression layer fusing progressive 3D convolutions with low-resolution VAE re-encoding achieves a 128× spatiotemporal compression for intermediate history, increasing effective memory capacity by over 27×.
- The method employs a dynamic top-k context selection mechanism coupled with an incremental Temporal RoPE adjustment to seamlessly correct position gaps caused by dropped tokens without requiring full cache recomputation.
Introduction
Autoregressive video diffusion models enable long-form generation but face critical bottlenecks where linear Key-Value cache growth causes out-of-memory errors and iterative prediction leads to severe semantic drift. Prior solutions either truncate history to save memory, which destroys long-range coherence, or retain full context, which exceeds the capacity of single GPUs for minute-scale videos. The authors introduce PackForcing, a unified framework that partitions generation history into sink, compressed, and recent tokens to bound memory usage while preserving global semantics. By employing a dual-branch network for massive spatiotemporal compression and a dynamic top-k selection mechanism with incremental RoPE adjustment, the method achieves stable 2-minute video synthesis on a single H200 GPU using only 5-second training clips.
Method
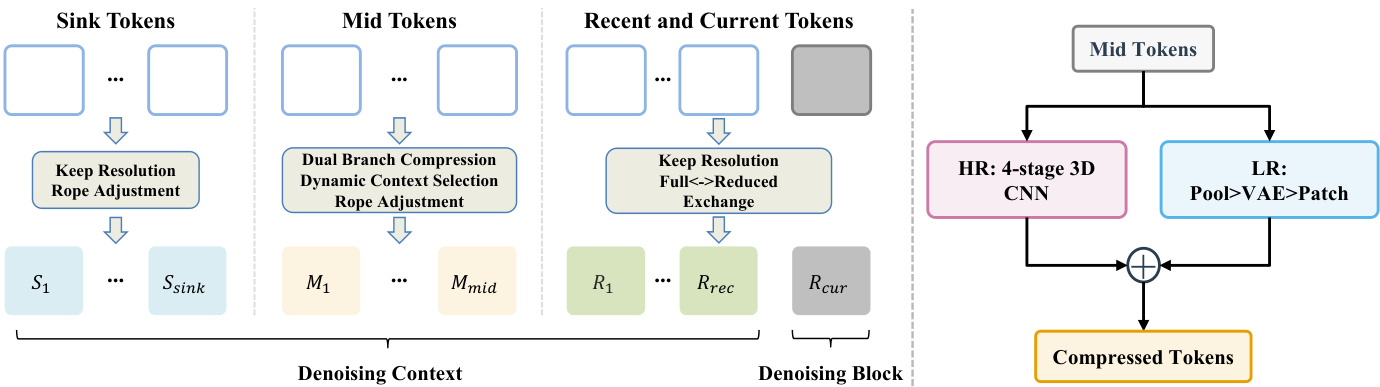
The authors propose PackForcing, a framework designed to resolve the memory bottleneck in autoregressive video generation by decoupling the generation history into three distinct functional partitions. Refer to the framework diagram for the overall architecture. The system organizes the denoising context into Sink Tokens, Mid Tokens, and Recent and Current Tokens. Sink Tokens correspond to the initial frames and are kept at full resolution to serve as semantic anchors. Recent and Current Tokens maintain high-fidelity local dynamics at full resolution. The vast majority of the history falls into the Mid Tokens partition, which undergoes aggressive compression to reduce the token count by approximately 32 times.
To achieve this compression, the authors employ a dual-branch compression module. As shown in the figure below, this module processes the Mid Tokens through two parallel pathways. The High-Resolution (HR) branch utilizes a 4-stage 3D CNN to preserve fine-grained structural details. The Low-Resolution (LR) branch decodes the latent frames to pixel space, applies pooling, and re-encodes them via a VAE to capture coarse semantics. These features are fused via element-wise addition to produce the final compressed tokens.
The specific architecture of the HR branch is detailed in the subsequent figure. It consists of a cascade of strided 3D convolutions with SiLU activations. The process begins with a temporal compression followed by three stages of spatial compression, culminating in a projection to the model's hidden dimension. This design ensures a significant volume reduction while retaining essential layout information.

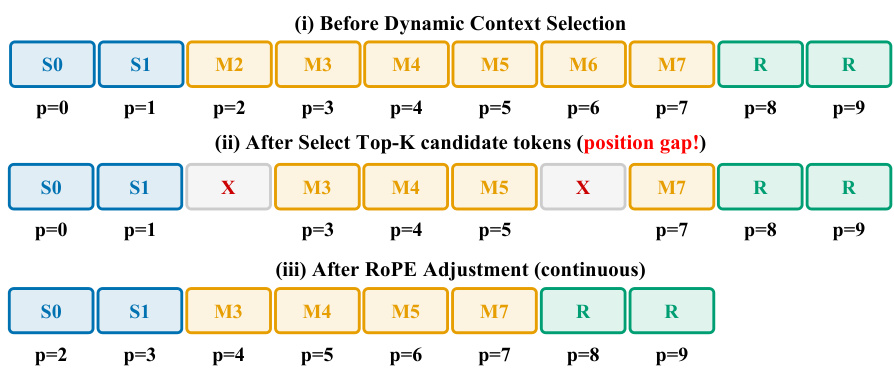
To further optimize memory usage, the system implements Dynamic Context Selection. Instead of attending to all compressed mid tokens, the model evaluates query-key affinities to route only the top-K most informative blocks. This selection process inevitably creates position gaps in the token sequence. To resolve this, the authors apply an incremental RoPE adjustment. Refer to the diagram illustrating the selection process to see how the position indices are re-aligned. Initially, the selection creates gaps where tokens are removed. The RoPE adjustment then shifts the positional embeddings of the remaining tokens to ensure continuous indices, allowing the transformer to maintain temporal coherence without full recomputation.
Finally, the training strategy involves end-to-end optimization of the HR compression layer. During the rollout phase, the compression module is integrated directly into the computational graph. This ensures that the compressed mid tokens are explicitly tailored to preserve semantic and structural cues necessary for downstream causal attention, rather than minimizing a generic reconstruction loss. This approach allows the model to generalize from short training sequences to long video generation with constant attention complexity.
Experiment
- Main experiments on 60s and 120s video generation validate that PackForcing achieves superior motion synthesis and temporal stability compared to baselines, maintaining high subject and background consistency without the severe degradation seen in other methods.
- Long-range consistency tests confirm that the sink token mechanism effectively anchors global semantics, preventing the compounding errors and semantic drift that typically occur in extended autoregressive generation.
- Ablation studies demonstrate that sink tokens are critical for balancing dynamic motion with semantic coherence, while dynamic context selection outperforms standard FIFO eviction by retaining highly attended historical blocks.
- Analysis of attention patterns reveals that information demand is distributed across the entire video history rather than being limited to recent frames, justifying the need for a compressed mid-buffer and global summary tokens.
- Qualitative evaluations show that the proposed architecture preserves fine visual details and complex continuous motion over two minutes, whereas competing methods suffer from color shifts, object duplication, or motion freezing.
- Efficiency analysis proves that the compression strategy bounds memory usage to a constant level regardless of video length, enabling long-horizon generation on single GPUs where uncompressed methods would fail.