Command Palette
Search for a command to run...
FlowScene: 멀티모달 그래프 정류 흐름을 통한 스타일 일관성 실내 장면 생성
FlowScene: 멀티모달 그래프 정류 흐름을 통한 스타일 일관성 실내 장면 생성
Zhifei Yang Guangyao Zhai Keyang Lu YuYang Yin Chao Zhang Zhen Xiao Jieyi Long Nassir Navab Yikai Wang
초록
장면 생성은 산업 전반에 걸쳐 광범위하게 적용되며, 높은 사실성과 기하학적 구조 및 외관에 대한 정밀한 제어를 동시에 요구합니다. 언어 기반 검색 방법은 대규모 객체 데이터베이스에서 그럴듯한 장면을 구성하지만, 객체 수준의 제어는 간과하는 경향이 있으며 장면 수준의 스타일 일관성을 강제하지 못해 실패하는 경우가 많습니다. 반면, 그래프 기반 형식은 객체에 대한 높은 제어 가능성을 제공하고 명시적으로 관계를 모델링함으로써 전체적 일관성을 도모하지만, 기존 방법들은 고충실도 텍스처링 결과를 생성하는 데 어려움을 겪어 실용성을 제한하고 있습니다. 본 논문은 멀티모달 그래프에 조건부인 삼중 분기 장면 생성 모델인 FlowScene 을 제안합니다. FlowScene 은 장면 레이아웃, 객체 형태, 객체 텍스처를 협력적으로 생성합니다. 그 핵심에는 생성 과정에서 객체 정보를 교환하여 그래프 전반에 걸친 협력적 추론을 가능하게 하는 긴밀하게 결합된 rectified flow 모델이 자리 잡고 있습니다. 이를 통해 객체의 형태, 텍스처, 관계에 대한 세밀한 제어가 가능해지며, 구조와 외관 전반에 걸쳐 장면 수준의 스타일 일관성이 강제됩니다. 광범위한 실험 결과, FlowScene 은 생성 사실성, 스타일 일관성, 그리고 인간 선호도와의 정렬 측면에서 언어 조건부 및 그래프 조건부 베이스라인을 모두 능가하는 성능을 입증하였습니다.
One-sentence Summary
Researchers from Peking University and Technical University of Munich introduce FlowScene, a tri-branch generative model that leverages a tight-coupled rectified flow mechanism to collaboratively synthesize layouts, shapes, and textures from multimodal graphs, achieving superior style coherence and object-level control compared to existing language or graph-driven baselines.
Key Contributions
- The paper introduces FlowScene, a tri-branch generative model conditioned on multimodal graphs that collaboratively produces scene layouts, object shapes, and object textures to ensure fine-grained control and scene-level style coherence.
- A tight-coupled rectified flow mechanism is presented as the core engine, which exchanges node information during the sampling process to satisfy both individual object conditions and holistic scene constraints while accelerating generation compared to diffusion-based methods.
- Extensive experiments demonstrate that the method outperforms language-conditioned and graph-conditioned baselines in generation realism, style consistency, and alignment with human preferences, supported by a workflow for diverse input sources.
Introduction
Scene generation is critical for industries like interior design, VR/AR, and robotics, where applications demand high realism alongside precise control over geometry and appearance. Prior language-driven methods often fail to enforce scene-level style coherence or provide granular object control, while existing graph-based approaches struggle to produce high-fidelity textured results in an end-to-end manner. The authors introduce FlowScene, a tri-branch generative model that leverages Multimodal Graph Rectified Flow to collaboratively generate scene layouts, object shapes, and textures. By tightly coupling node information exchange during the sampling process, this approach enables fine-grained control over individual objects while ensuring consistent style across the entire scene structure and appearance.
Method
The proposed framework, FlowScene, operates as a tri-branch generator conditioned on a multimodal graph to synthesize indoor scenes. The system accepts diverse inputs, including natural language descriptions and reference images, which are parsed into a structured scene graph. This graph serves as the central conditioning mechanism for the generation process, ensuring consistency across object layouts, shapes, and textures.
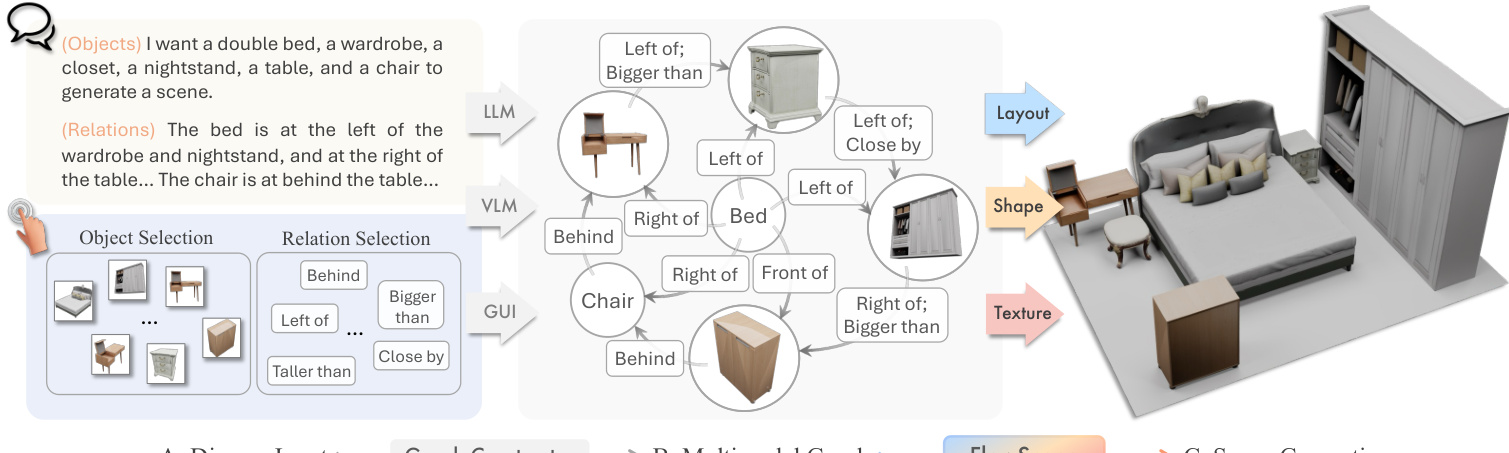
The process begins with the construction of a multimodal scene graph GM=(VM,E). Nodes in VM represent objects and can be text-only, image-only, or multimodal, aggregating learnable embeddings with foundation features from CLIP or DINOv2. Edges in E encode spatial and semantic relationships such as "left of" or "bigger than." An LLM or VLM parses user inputs to populate this graph, allowing for fine-grained control over the scene configuration.
To generate the scene, the authors employ a Multimodal Graph Rectified Flow backbone. This module adapts rectified flow models to handle multiple content generation jointly. The core of this mechanism is the InfoExchangeUnit, which utilizes a Triplet-Graph Convolutional Network (Triplet-GCN) to perform message passing and feature aggregation across the graph edges. During the denoising process, this unit incorporates temporal denoising data Dt and projects it alongside node features to produce time-dependent conditions Ct. This ensures that the generation of each object respects the global constraints imposed by the graph structure.
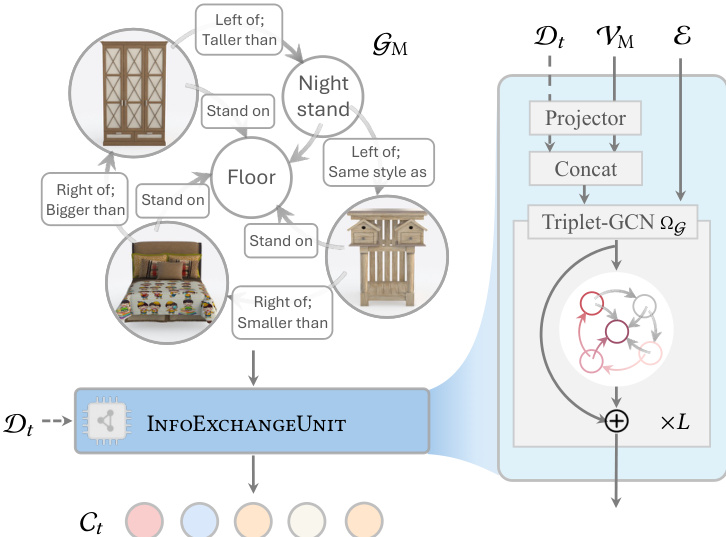
The training objective minimizes the least-squares error between the predicted velocity field vθ and the target velocity derived from linear interpolation between data and noise. The loss function is defined as:
LGRF=ED,C,t[∥ΘD(Dt,Ct,t)−v∥22]where ΘD is the denoiser network. During inference, the model integrates the reverse-time ODE starting from Gaussian noise to recover the target data distribution.
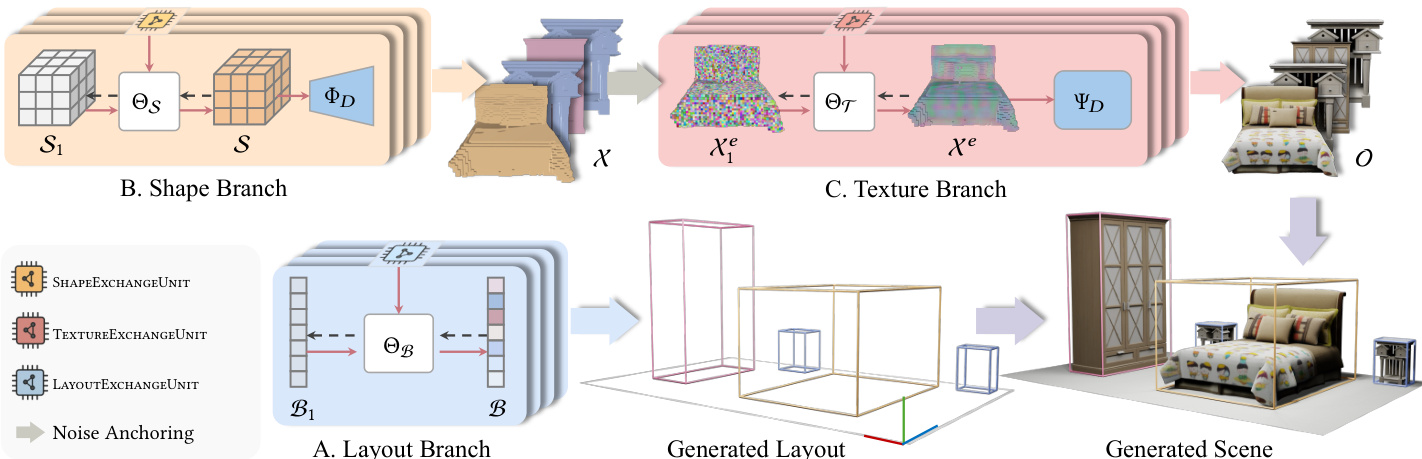
FlowScene decomposes the generation task into three coordinated branches, each backed by the graph rectified flow module. The Layout Branch generates 3D bounding boxes defined by location, size, and rotation, utilizing a specialized LayoutExchangeUnit to enforce spatial constraints. The Shape Branch operates in parallel to generate voxelized object shapes. It employs a Shape VQ-VAE to encode sparse voxel structures into compact latent codes, which are then denoised and decoded. The Texture Branch is subordinate to the shape branch, anchoring Gaussian noise to the geometric structure to generate textures. It uses a Texture VQ-VAE and a TextureExchangeUnit to ensure style consistency across objects, which is particularly crucial for text-only nodes where appearance is inferred from relational context.
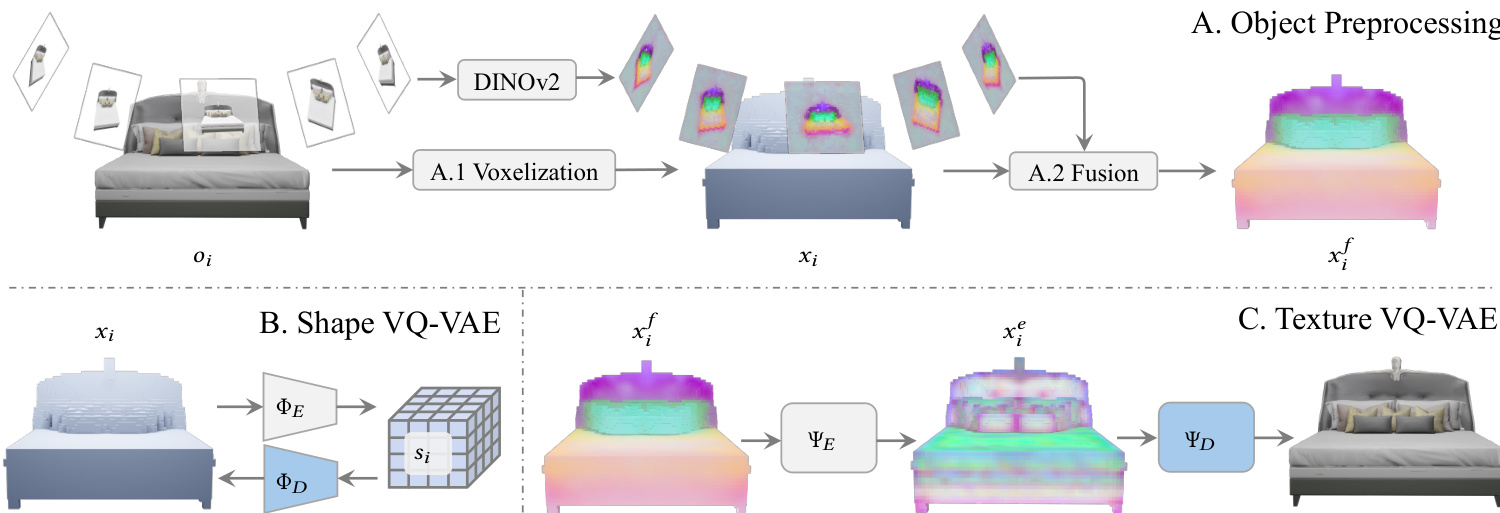
Prior to training the generative branches, objects undergo preprocessing to prepare the data for the VQ-VAEs. Objects are voxelized into sparse structures, and multi-view images are rendered to extract DINOv2 features. These features are reprojected onto the voxel grid and averaged to create feature voxels. The Shape VQ-VAE learns to reconstruct the voxelized geometry, while the Texture VQ-VAE learns to reconstruct the object appearance from the feature voxels. This preprocessing ensures that the generative models operate on efficient latent representations rather than raw high-dimensional data.
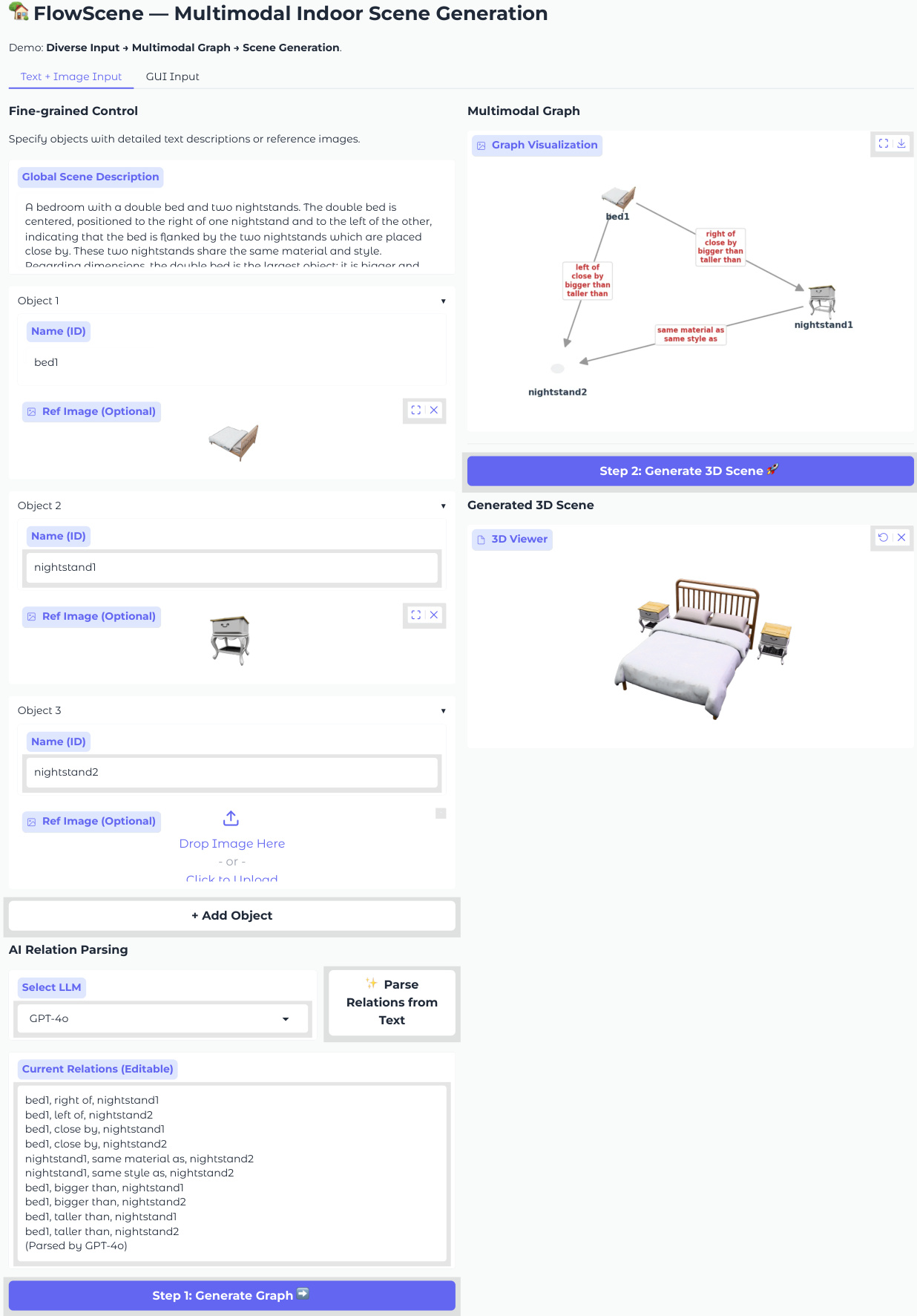
The system supports two primary application modes for user interaction. In the language-driven mode, users provide natural language descriptions which are parsed into a scene graph by an LLM. In the interactive GUI mode, users select object candidates and define relations through a visual interface. Both modes feed into the multimodal graph, which drives the FlowScene backend to generate a high-fidelity textured 3D scene consistent with the specified configuration.
Experiment
- Experiments on SG-FRONT and 3D-FRONT datasets validate that FlowScene outperforms training-free language-based methods and graph-conditioned generative models in scene-level realism, object-level geometric fidelity, and style consistency.
- Quantitative and qualitative comparisons demonstrate that FlowScene achieves superior alignment with human preferences, producing scenes with higher visual quality and more accurate layout adherence to textual and graph constraints.
- Ablation studies confirm that the InfoExchangeUnit is critical for spatial coherence and appearance consistency, while the graph flow backbone significantly enhances shape generation quality compared to diffusion baselines.
- Robustness tests show that training with multi-view inputs enables flexible adaptation to varying visual conditions, and the model maintains high performance even with sparse relational information in the input graph.
- Additional evaluations highlight FlowScene's ability to preserve inter-shape consistency for identical objects and effectively propagate local graph updates to maintain holistic scene structure.