Command Palette
Search for a command to run...
3DreamBooth: 고정밀 3D 주제 주도형 비디오 생성 모델
3DreamBooth: 고정밀 3D 주제 주도형 비디오 생성 모델
Hyun-kyu Ko Jihyeon Park Younghyun Kim Dongheok Park Eunbyung Park
초록
맞춤형 대상의 동적이고 뷰 일관성을 갖춘 비디오 생성은 몰입형 VR/AR, 가상 제작, 차세대 전자상거래 등 다양한 신흥 응용 분야에서 높은 수요를 보이고 있습니다. 그러나 대상 중심 비디오 생성 분야에서 빠른 진전이 이루어졌음에도 불구하고, 기존 방법론들은 주로 대상을 2D 개체로 간주하며 단일 뷰 시각 특징이나 텍스트 프롬프트를 통해 정체성을 전달하는 데 초점을 맞추고 있습니다. 실제 세계의 대상들은 본질적으로 3D적이므로, 이러한 2D 중심 접근법을 3D 객체 맞춤화에 적용할 경우 근본적인 한계가 드러납니다. 즉, 3D 기하학을 재구성하는 데 필요한 포괄적인 공간 사전 지식 (spatial priors) 이 부족하다는 점입니다. 그 결과, 새로운 뷰를 합성할 때 보이지 않는 영역에 대해 실제 3D 정체성을 보존하기보다는 그럴듯하지만 임의적인 세부 사항을 생성하는 데 의존할 수밖에 없습니다. 멀티뷰 비디오 데이터셋의 부족으로 인해 진정한 3D 인식 (3D-aware) 맞춤화를 달성하는 것은 여전히 어렵습니다. 제한된 비디오 시퀀스로 모델을 파인튜닝하는 시도를 할 수 있으나, 이는 종종 시간적 과적합 (temporal overfitting) 을 초래합니다. 이러한 문제들을 해결하기 위해 우리는 3DreamBooth 와 3Dapter 로 구성된 새로운 3D 인식 비디오 맞춤화 프레임워크를 제안합니다. 3DreamBooth 는 1 프레임 최적화 패러다임을 통해 공간 기하학과 시간적 운동을 분리합니다. 공간 표현에 대한 업데이트만 제한함으로써, 광범위한 비디오 기반 학습 없이도 모델에 강력한 3D 사전 지식을 효과적으로 주입합니다. 미세한 텍스처를 향상시키고 수렴 속도를 가속화하기 위해 시각적 조건부 모듈인 3Dapter 를 도입했습니다. 3Dapter 는 단일 뷰 사전 학습 후, 비대칭적 조건부 전략을 통해 주요 생성 분기와 함께 멀티뷰 공동 최적화를 거칩니다. 이 설계는 모듈이 동적 선택적 라우터 역할을 하여 최소한의 참조 집합에서 뷰별 기하학적 힌트를 쿼리할 수 있도록 합니다. 프로젝트 페이지: https://ko-lani.github.io/3DreamBooth/
One-sentence Summary
Researchers from Yonsei University and Sungkyunkwan University propose 3DreamBooth and 3Dapter, a framework that decouples spatial geometry from temporal motion via 1-frame optimization to generate high-fidelity, view-consistent videos of customized 3D subjects for immersive VR and virtual production.
Key Contributions
- The paper introduces 3DreamBooth, a 1-frame optimization strategy that integrates subject-specific 3D identity into video diffusion models by restricting updates to spatial representations, thereby avoiding the need for multi-view video datasets while preventing temporal overfitting.
- A multi-view conditioning module called 3Dapter is presented to enhance fine-grained textures and accelerate convergence through a two-stage pipeline that employs an asymmetrical conditioning strategy to query view-specific geometric hints from a minimal reference set.
- The work establishes 3D-CustomBench, a curated evaluation suite for 3D-consistent video customization, with experiments demonstrating that the combined framework outperforms existing single-reference baselines in generating high-fidelity, identity-preserving videos.
Introduction
The demand for immersive VR/AR experiences and virtual production requires generative systems that can place customized subjects into dynamic environments while maintaining strict visual consistency across different viewpoints. Current subject-driven video generation methods largely treat objects as 2D entities, relying on single-view references or text prompts that fail to capture the underlying 3D geometry. This limitation forces models to hallucinate arbitrary details for unseen angles rather than preserving true spatial identity, while attempts to train on limited multi-view video data often result in temporal overfitting. To resolve these issues, the authors introduce 3DreamBooth, a framework that decouples spatial geometry from temporal motion through a 1-frame optimization paradigm to bake robust 3D priors without exhaustive video training. They further enhance this approach with 3Dapter, a multi-view conditioning module that uses an asymmetrical strategy to inject fine-grained geometric hints, enabling high-fidelity and view-consistent video generation with improved computational efficiency.
Dataset
-
Dataset Composition and Sources: The authors utilize two primary datasets: the Subjects200K dataset for single-view pre-training and the newly introduced 3D-CustomBench for evaluation. 3D-CustomBench combines objects from the MVIgNet dataset with custom-captured 3D objects to ensure complete 360° orbital coverage.
-
Key Details for Each Subset:
- Subjects200K: Contains over 30,000 distinct subject descriptions generated by GPT-4o, which are used to synthesize paired images via the FLUX.1 model. These pairs share identical subject identities but feature varied poses, lighting, and backgrounds to prevent overfitting.
- 3D-CustomBench: Comprises 30 distinct objects selected for complex 3D structures, non-trivial topologies, and high texture resolution. Each object includes a full multi-view sequence of approximately 30 images.
-
Data Usage and Training Strategy:
- Pre-training: The model leverages Subjects200K to train 3Dapter using Low-Rank Adaptation (LoRA) on key image-processing modules. Training runs for 100,000 iterations with a global batch size of 4 and a learning rate of 1×10−4 using the AdamW optimizer.
- Evaluation: For 3D-CustomBench, the full multi-view sequence of each object is used for 3DreamBooth optimization. The authors sample Nc=4 conditioning views for 3Dapter that maximize angular coverage while minimizing visual overlap.
-
Processing and Metadata Construction:
- Automated Curation: GPT-4o generates subject descriptions and acts as an automated evaluator to discard misaligned samples during the construction of Subjects200K.
- Prompt Generation: GPT-4o automatically creates one challenging validation prompt per object in 3D-CustomBench, featuring diverse backgrounds and complex dynamics like human-object interactions.
- View Selection: Conditioning views are strategically selected to ensure optimal angular distribution rather than random sampling.
Method
The authors introduce 3DreamBooth, a framework for 3D customization of video diffusion models. The core strategy involves decoupling spatial identity from temporal dynamics through a 1-frame training paradigm.

Refer to the framework diagram for the overall architecture. The pipeline accepts a set of multiview images where one image serves as the target and a subset acts as reference conditions. A global prompt with a unique identifier V guides the generation. The text and noisy target latents are processed through the main branch using 3DB LoRA, while reference latents pass through a shared 3Dapter. These features are concatenated for Multi-view Joint Attention. By restricting the input to a single frame (T=1), the model bypasses temporal attention, focusing updates on spatial representations to learn a 3D prior without temporal overfitting.
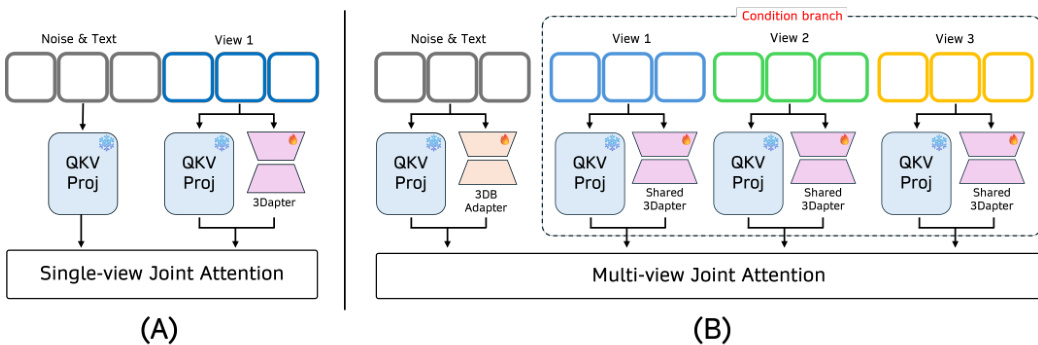
As shown in the figure below, the 3Dapter module utilizes a two-stage conditioning mechanism. The first stage involves single-view pre-training on reference-target pairs. The second stage performs multi-view joint optimization where a shared 3Dapter processes multiple conditioning views in parallel. The Multi-view Joint Attention acts as a dynamic selective router, querying relevant view-specific geometric hints to reconstruct the target view. This shared architecture ensures consistent geometric feature extraction across viewpoints without increasing parameter count linearly.
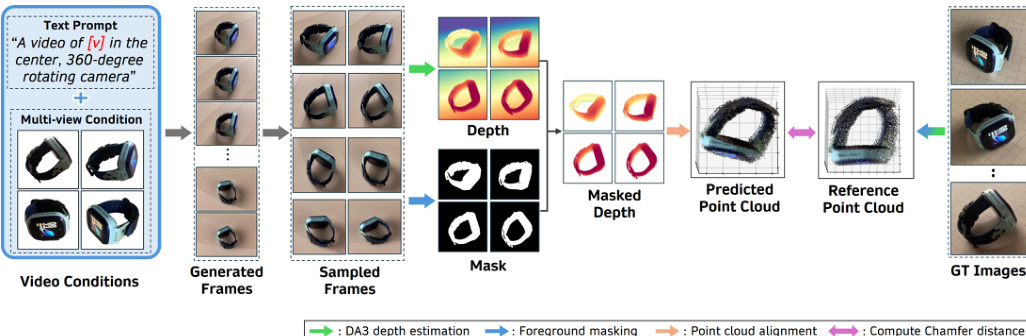
As shown in the figure below, the training process incorporates a 3D consistency check to ensure geometric fidelity. Generated frames undergo depth estimation and foreground masking to produce a predicted point cloud. This cloud is aligned with a reference point cloud to compute the Chamfer distance, which serves as a constraint during optimization. This approach allows the model to focus on learning geometric transformations while preserving high-frequency details, effectively overcoming the information bottleneck of text-driven customization.
Experiment
- Comparative experiments against VACE and Phantom validate that the proposed framework achieves superior multi-view subject fidelity, preserving identity, shape, color, and fine-grained details during 360-degree rotations where baselines fail to reconstruct unseen viewpoints.
- 3D geometric fidelity evaluations demonstrate that the method significantly reduces reconstruction error and improves surface coverage compared to single-view approaches, confirming its ability to recover complete 3D structures from multi-view conditioning.
- Ablation studies reveal that the synergistic combination of 3Dapter and 3DreamBooth is essential, as 3Dapter alone lacks 3D consistency while 3DreamBooth alone struggles with texture details and slow convergence, whereas their joint optimization ensures both structural accuracy and high-frequency detail preservation.
- Additional tests confirm the framework's robustness across diverse object categories and dynamic scenarios, as well as its extensibility to other Diffusion Transformer architectures without requiring explicit spatial conditioning modules.
- Analysis of training dynamics shows that pre-training the 3Dapter module is critical to prevent optimization collapse and enable rapid convergence, while the full framework achieves high-fidelity results in fewer iterations than text-driven baselines.