Command Palette
Search for a command to run...
보완적 강화 학습
보완적 강화 학습
초록
강화 학습 (RL) 은 LLM 기반 에이전트 훈련을 위한 강력한 패러다임으로 부상했으나, 희소한 결과 기반 피드백뿐만 아니라 에피소드 간 이전 경험을 활용하지 못하는 에이전트의 한계로 인해 샘플 효율성이 낮다는 제약에 직면해 있습니다. 과거 경험을 에이전트에 통합하는 것은 유망한 해결책으로 제시되나, 기존 접근법은 결정적 약점을 지닙니다: 역사적 경험에서 추출된 지식이 정적으로 저장되거나, 개선되는 액터 (actor) 와 공진화 (co-evolution) 하지 못해, 훈련 과정에서 경험과 액터의 진화하는 능력 간 점진적 불일치가 발생하며 그 유용성이 감소합니다. 신경과학의 보완적 학습 시스템 (complementary learning systems) 에서 영감을 받아, 본 논문은 RL 최적화 루프 내에서 경험 추출기 (experience extractor) 와 정책 액터 (policy actor) 의 원활한 공진화를 달성하는 'Complementary RL'을 제안합니다. 구체적으로, 액터는 희소한 결과 기반 보상을 통해 최적화되는 반면, 경험 추출기는 추출한 경험이 액터의 성공에 명확히 기여하는지에 따라 최적화되어, 액터의 능력 성장과 동기화되도록 경험 관리 전략을 진화시킵니다. 실험 결과, Complementary RL 은 경험으로부터 학습하지 않는 결과 기반 에이전트 RL 베이스라인을 능가하여, 단일 작업 시나리오에서 10% 의 성능 향상을 달성하였으며, 다중 작업 환경에서도 견고한 확장성을 입증했습니다. 이러한 결과는 Complementary RL 을 효율적인 경험 주도 에이전트 학습의 새로운 패러다임으로 확립합니다.
One-sentence Summary
Researchers from Alibaba Group and HKUST introduce Complementary RL, a framework that enables the seamless co-evolution of an experience extractor and policy actor to overcome static memory limitations in reinforcement learning, significantly boosting sample efficiency and performance for LLM-based agents in both single and multi-task scenarios.
Key Contributions
- The paper introduces Complementary RL, a framework that establishes a closed co-evolutionary loop between a policy actor and an experience extractor to ensure distilled knowledge evolves in lockstep with the agent's growing capabilities.
- This method optimizes the experience extractor based on the demonstrable utility of its distilled experiences in facilitating actor success, utilizing structured addition, refining, and merging operations to automatically resolve conflicts and redundancies.
- Experimental results demonstrate that the approach achieves a 10% performance improvement in single-task scenarios and exhibits robust scalability in multi-task settings compared to outcome-based agentic RL baselines that do not learn from experience.
Introduction
Reinforcement learning empowers Large Language Model agents but struggles with sample inefficiency due to sparse outcome feedback and an inability to effectively reuse prior experience. Existing methods that incorporate historical data often fail because they treat experience as a static resource or rely on extractors that do not adapt, leading to a misalignment between the guidance provided and the agent's growing capabilities. To address this, the authors introduce Complementary RL, a framework inspired by neuroscience that establishes a closed co-evolutionary loop between a policy actor and an experience extractor. The actor optimizes via outcome-based rewards while the extractor learns to distill high-utility experiences based on their actual contribution to the actor's success, ensuring both components evolve in lockstep to maximize learning efficiency.
Dataset
-
Dataset Composition and Sources The authors curate a multi-environment dataset drawn from five distinct sources: MiniHack, WebShop, ALFWorld, SWE-Bench, and Sokoban. These environments span grid-based navigation, web interaction, household task simulation, software engineering, and combinatorial puzzle solving.
-
Key Details for Each Subset
- MiniHack: Adapted for LLM agents using text symbols to represent entities under a fog-of-war observation model. The authors evaluate on four specific variants of increasing difficulty: MiniHack Room (5x5 grid, directional actions), MiniHack Maze (9x9 grid, directional actions), MiniHack KeyRoom (requires key retrieval and door opening), and MiniHack River (requires pushing a boulder to cross water).
- WebShop: A simulated shopping benchmark where agents issue search queries or click buttons. The authors use the small variant configuration, restricting the product catalog to 1,000 items and sampling goals based on attribute frequency.
- ALFWorld: A text-based interactive environment for household tasks. The training split consists of 1,466 task instances, while 134 instances are held out for evaluation.
- SWE-Bench: A software engineering benchmark requiring codebase modifications to pass unit tests. The authors utilize the SWE-Bench-Verified subset but apply a filtering strategy to retain only 124 tasks where the base model achieves a pass@16 success rate between 0% and 80%, excluding trivial or impossible instances.
- Sokoban: A text-based puzzle game represented with structured symbols. Episodes are configured as 6x6 rooms containing two boxes and two targets to create a challenging combinatorial search space.
-
Model Usage and Task Mixtures The paper defines two specific training mixtures based on the available environments:
- 3-Tasks Mixture: Combines MiniHack Room, WebShop, and ALFWorld.
- 6-Tasks Mixture: Expands the set to include MiniHack Maze, MiniHack KeyRoom, and Sokoban alongside the previous three. During reinforcement learning, all environments generally use a binary reward scheme (1 for success, 0 for failure), with the exception of ALFWorld which assigns -1 for failure.
-
Processing and Implementation Details
- Symbolic Representation: MiniHack and Sokoban environments are converted into text-based formats using specific symbols for agents, goals, obstacles, and objects to align with LLM input requirements.
- Action Spaces: Action definitions vary by environment, ranging from simple directional movements in MiniHack Room to complex tool usage (Bash, str_replace_editor) in SWE-Bench and natural language commands in ALFWorld.
- Reward Logic: The authors implement a standard binary reward system across most tasks, while ALFWorld utilizes a negative reward for failure to provide stronger learning signals.
Method
The authors propose Complementary RL, a unified framework that establishes a co-evolutionary relationship between a policy actor and an experience extractor. Unlike traditional approaches where experience is static or collected by a fixed extractor, this method jointly optimizes both components to ensure mutual adaptation. As shown in the figure below, the system evolves through distinct training steps where the Policy Actor and Experience Extractor grow in complexity in tandem.
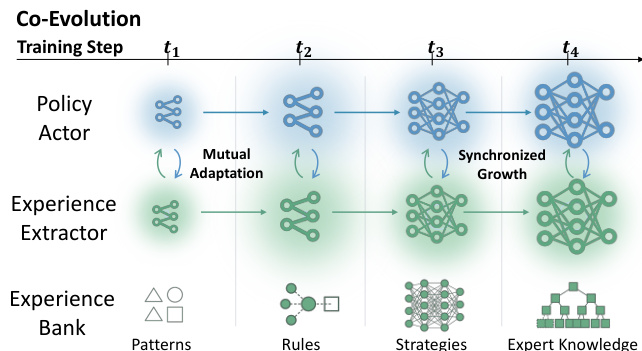
At the initial stage t1, both the Policy Actor and Experience Extractor are relatively simple. As training progresses through t2 and t3, the Policy Actor generates higher-quality trajectories, which in turn allows the Experience Extractor to distill more sophisticated patterns and rules into the Experience Bank. By t4, the system achieves synchronized growth, where the extractor provides expert knowledge that guides the actor, and the actor's improved performance refines the quality of the experience bank. This dynamic prevents the distributional misalignment often seen in static experience systems, where the guidance becomes stale as the policy improves.
The algorithmic design relies on specific optimization objectives for each component. The Experience Extractor πϕ distills structured experience m from completed trajectories τ and is optimized using the CISPO objective. This objective maximizes the utility of the distilled experience by assigning a binary reward based on the outcome of the trajectory it guided. The Policy Actor πθ is optimized using a modified Group Relative Policy Optimization (GRPO) objective. To prevent over-reliance on external guidance, the authors partition the rollouts into experience-guided and experience-free subgroups. Advantages are computed independently within each subgroup to preserve signal integrity, ensuring the actor internalizes capabilities while benefiting from retrieved knowledge.
To support this co-evolution efficiently, the authors implement a dual-loop infrastructure that decouples rollout collection from experience distillation. Refer to the framework diagram for the detailed architecture of the Primary Training Loop and Background Track. In the Primary Training Loop, the Policy Actor continuously interacts with the environment to collect trajectories and updates its parameters based on outcome rewards. Concurrently, the Background Track manages the Experience Manager H, which oversees the Experience Bank M. The Experience Manager coordinates the asynchronous flow of data by receiving distillation requests from completed episodes, processing them through the Experience Extractor, and updating the bank using write locks to ensure consistency. For retrieval, it employs query batching and parallel search workers under read locks to minimize latency for the actor. This asynchronous design eliminates synchronization barriers, allowing the actor and extractor to optimize on independent schedules while maintaining a globally consistent experience bank.
Experiment
- Complementary RL is validated across four open-ended environments, demonstrating that co-evolving a policy actor with an experience extractor consistently outperforms static baselines and methods lacking experience integration.
- The approach achieves higher success rates and improved action efficiency by guiding the actor toward more effective decision-making through distilled experience.
- Multi-task training experiments confirm that co-evolution is essential for performance, as static extractors fail to adapt to the evolving actor, leading to distributional misalignment and noisy retrieval.
- Increasing the capacity of the experience extractor further amplifies benefits, indicating that stronger models extract more generalizable and informative experience.
- The framework scales robustly as the number of training tasks increases, maintaining significant performance gains over baselines in complex, multi-task settings.
- Latency analysis shows that the asynchronous training framework introduces no appreciable overhead to rollout collection compared to standard baselines.