Command Palette
Search for a command to run...
Astrolabe: 증류된 자기회귀 비디오 모델을 위한 전진 과정 강화 학습의 제어
Astrolabe: 증류된 자기회귀 비디오 모델을 위한 전진 과정 강화 학습의 제어
Songchun Zhang Zeyue Xue Siming Fu Jie Huang Xianghao Kong Y Ma Haoyang Huang Nan Duan Anyi Rao
초록
증류된 자기회귀 (AR) 비디오 모델은 효율적인 스트리밍 생성을 가능하게 하지만, 인간의 시각적 선호도와 자주 불일치하는 문제가 발생합니다. 기존 강화학습 (RL) 프레임워크는 이러한 아키텍처에 본질적으로 적합하지 않아, 고비용의 재증류 (re-distillation) 가 필요하거나 역과정 최적화를 솔버와 결합해야 하며, 이로 인해 상당한 메모리 및 계산 오버헤드가 발생합니다. 본 논문은 증류된 AR 모델을 위해 최적화된 효율적인 온라인 RL 프레임워크인 'Astrolabe'를 제안합니다. 기존 병목 현상을 극복하기 위해, 우리는 부정적 인식 미세조정 (negative-aware fine-tuning) 에 기반한 순방향 RL 수식화를 도입합니다. 추론 끝단에서 긍정 샘플과 부정 샘플을 직접 대비함으로써, 이 접근법은 역과정 언롤링 (reverse-process unrolling) 없이도 암시적인 정책 개선 방향을 설정합니다. 이러한 정렬을 장편 비디오로 확장하기 위해, 우리는 로울링 KV-cache 를 통해 시퀀스를 점진적으로 생성하는 스트리밍 학습 방식을 제안합니다. 이 방식은 이전 컨텍스트에 조건을 부여하여 장기적 일관성을 보장하면서, RL 업데이트를 로컬 클립 윈도우에만 적용합니다. 마지막으로, 보상 해킹 (reward hacking) 을 완화하기 위해, 불확실성 인식 선택적 정규화와 동적 참조 업데이트로 안정화된 다중 보상 목표를 통합합니다. 광범위한 실험 결과, 본 방법은 다양한 증류된 AR 비디오 모델에서 생성 품질을 일관되게 향상시키며, 견고하고 확장 가능한 정렬 솔루션으로 입증되었습니다.
One-sentence Summary
Researchers from HKUST, JD Explore Academy, and HKU present Astrolabe, an online RL framework that aligns distilled autoregressive video models with human preferences via a forward-process formulation and streaming training scheme, eliminating costly re-distillation while enhancing long-video coherence and mitigating reward hacking.
Key Contributions
- The paper introduces Astrolabe, an online reinforcement learning framework that aligns distilled autoregressive video models with human preferences by contrasting positive and negative samples at inference endpoints to establish policy improvement without reverse-process unrolling.
- A streaming training scheme is proposed to enable scalable alignment for long videos, which generates sequences progressively via a rolling KV-cache and applies reinforcement learning updates exclusively to local clip windows while conditioning on prior context.
- The work integrates a multi-reward objective stabilized by uncertainty-aware selective regularization and dynamic reference updates to mitigate reward hacking, with extensive experiments demonstrating consistent quality improvements across multiple distilled autoregressive video models.
Introduction
Distilled autoregressive video models enable efficient real-time streaming generation by producing frames sequentially, yet they often suffer from artifacts and misalignment with human visual preferences. Prior attempts to align these models using reinforcement learning face significant hurdles, as existing methods either rely on reward-weighted distillation that lacks active exploration or require expensive reverse-process optimization that couples training to specific solvers and incurs high memory overhead. The authors leverage Astrolabe, an efficient online RL framework that introduces a forward-process formulation based on negative-aware fine-tuning to align models without re-distillation or trajectory unrolling. Their approach further scales to long videos through a streaming training scheme that applies updates to local segments while maintaining context, alongside stabilization techniques like multi-reward objectives and uncertainty-aware regularization to prevent reward hacking.
Method
The authors propose Astrolabe, a memory-efficient framework designed to align distilled autoregressive video models with human preferences through online reinforcement learning. The method combines group-wise streaming rollout using a rolling KV cache for efficient group-wise sampling with clip-level forward-process RL for solver-agnostic optimization. To scale to long videos, the framework utilizes Streaming Long Tuning with detached historical gradients. Furthermore, a multi-reward formulation paired with uncertainty-based selective regularization is employed to effectively mitigate reward hacking during training. Refer to the framework diagram for a visual overview of the complete pipeline.
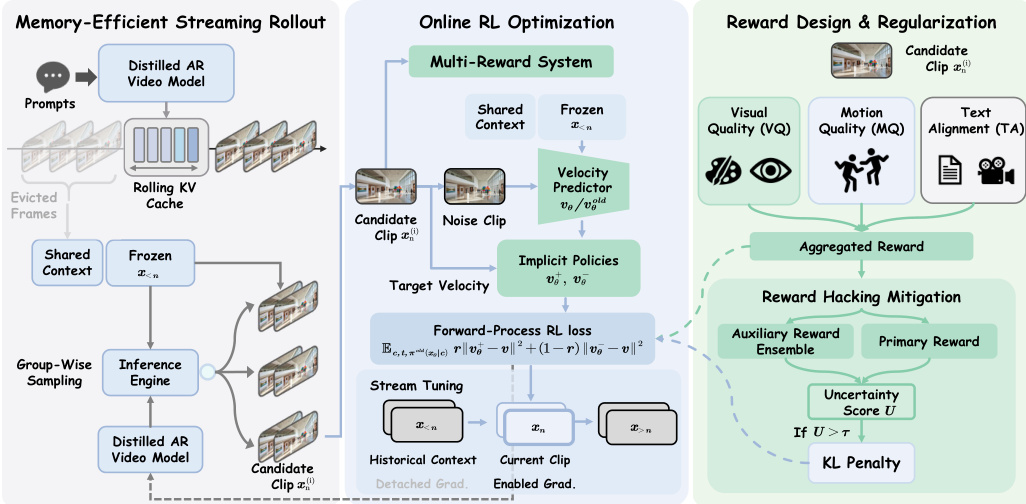
Memory-Efficient Streaming Rollout Standard RL paradigms rely on sequence-level rollouts with global rewards, which introduces temporal credit assignment problems and prohibitive memory overhead. To overcome these limitations, the authors propose a group-wise streaming rollout strategy. They maintain a rolling KV cache to bound memory usage by constructing a restricted visual context window comprising a frame sink of permanently retained frames and a rolling window of the most recent frames. Rather than generating independent long trajectories from scratch, the model autoregressively samples the visual history exactly once and freezes its KV cache as a shared prefix. At each step, the model decodes multiple independent candidate clips in parallel using this shared context, which restricts the generation overhead to the local chunk and substantially reduces rollout time.
Online RL Optimization For each candidate xn(i), the system evaluates a composite reward R(xn(i),c) and computes its advantage A(i) via group-wise mean-centering:
A(i)=R(xn(i),c)−G1j=1∑GR(xn(j),c)This advantage is then normalized as r~i=clip(A(i)/Amax)/2+0.5. Using the current (vθ) and old (vθold) velocity predictors, implicit positive and negative policies are defined via interpolation:
v+=(1−β)vθold+βvθ,v−=(1+β)vθold−βvθThe model is optimized directly via the implicit policy loss Lpolicy by substituting the noised sample to derive vtarget. To further mitigate reward hacking, this objective is complemented by an uncertainty-aware selective KL penalty. Additionally, the framework addresses the train-short/test-long mismatch through Streaming Long Tuning. This paradigm strictly simulates the dynamics of long-sequence inference while decoupling the forward rollout from gradient computation. Specifically, the KV cache of all preceding frames is explicitly detached from the computation graph upon reaching the active training window, allowing gradients to be backpropagated only through the active window.
Reward Design and Regularization To address the issue where scalar reward functions obscure specific quality dimensions, the authors formulate a composite reward integrating three distinct axes: Visual Quality, Motion Quality, and Text-Video Alignment. Visual Quality is computed as the mean HPSv3 score over the top 30% of frames to prevent transient motion blur from disproportionately penalizing the assessment. Motion Quality evaluates temporal consistency using a pre-trained VideoAlign strictly on grayscale inputs to focus on motion dynamics. Text Alignment employs the standard RGB VideoAlign to measure semantic correspondence. To prevent uniform KL regularization from indiscriminately suppressing high-quality generations, an uncertainty-aware selective KL penalty is introduced. For each candidate, sample uncertainty is quantified as the rank discrepancy between the primary reward model and auxiliary models. High positive values indicate likely reward hacking, and these risky samples are masked to apply the KL penalty strictly, preserving optimization flexibility for clean data.
Experiment
- Short-video single-prompt generation: Validates that the Astrolabe framework consistently enhances distilled autoregressive models across various base architectures, yielding sharper textures and superior motion coherence while maintaining inference speed.
- Long-video single-prompt generation: Demonstrates that alignment optimizations performed on short videos effectively extrapolate to extended temporal horizons, improving long-horizon quality and temporal consistency even for models originally trained on short sequences.
- Long-video multi-prompt generation: Confirms the framework's ability to improve human preference alignment in interactive settings, resulting in better visual aesthetics and stable long-range motion consistency during complex narrative transitions.
- Ablation studies: Establish that clip-level group-wise sampling with detached context optimizes the memory-quality trade-off, while a multi-reward formulation prevents single-objective overfitting and selective KL regularization ensures stable convergence without restricting learning freedom.