Command Palette
Search for a command to run...
HopChain: 일반화된 비전-언어 추론을 위한 멀티홉 데이터 합성
HopChain: 일반화된 비전-언어 추론을 위한 멀티홉 데이터 합성
초록
시각-언어 모델 (VLMs) 은 강력한 다중 모달 능력을 보이지만, 세밀한 시각-언어 추론에서는 여전히 어려움을 겪고 있습니다. 우리는 긴 체인-오브-생각 (CoT) 추론이 지각, 추론, 지식, 그리고 환각 오류 등 다양한 실패 양상을 드러내며, 이러한 오류들이 중간 단계들을 거쳐 누적될 수 있음을 발견했습니다. 그러나 현재 강화 학습에서 검증 가능한 보상 (RLVR) 을 위해 사용되는 대부분의 기존 시각-언어 데이터는 시각적 증거에 의존하는 복잡한 추론 체인을 포함하지 않아, 이러한 약점들이 제대로 드러나지 않고 있습니다. 이에 따라 우리는 VLM 의 RLVR 훈련을 위해 다중 홉 (multi-hop) 시각-언어 추론 데이터를 합성하는 확장 가능한 프레임워크인 HopChain 을 제안합니다. 각 합성된 다중 홉 쿼리는 논리적으로 의존적인 인스턴스 기반 홉들의 체인을 형성하며, 초기 홉들은 후속 홉에 필요한 인스턴스, 집합, 또는 조건을 설정하고, 최종 답변은 검증 가능한 보상에 적합한 구체적이고 모호하지 않은 숫자로 구성됩니다. 우리는 Qwen3.5-35B-A3B 와 Qwen3.5-397B-A17B 모델을 두 가지 RLVR 설정 하에 훈련했습니다. 첫 번째는 원본 데이터만 사용한 경우이며, 두 번째는 원본 데이터에 HopChain 의 다중 홉 데이터를 추가한 경우입니다. 이 두 설정을 STEM 및 퍼즐, 일반 VQA, 텍스트 인식 및 문서 이해, 비디오 이해 등 24 개 벤치마크에 걸쳐 비교 평가했습니다. 이 다중 홉 데이터는 특정 벤치마크를 위해 합성된 것은 아니지만, 두 모델 모두에서 24 개 벤치마크 중 20 개에서 성능 향상을 보이며 광범위하고 일반화 가능한 개선을 입증했습니다. 일관되게, 전체 체인 쿼리를 반다중 홉 또는 단일 홉 변형으로 대체할 경우, 다섯 개의 대표 벤치마크에서의 평균 점수가 각각 70.4 에서 66.7 및 64.3 으로 감소했습니다. 특히, 다중 홉에 의한 성능 향상은 긴 CoT 시각-언어 추론에서 정점을 이루며, 초장기 CoT 영역에서는 50 점 이상의 향상을 기록했습니다. 이러한 실험 결과들은 HopChain 이 일반화 가능한 시각-언어 추론을 개선하는 다중 홉 데이터를 합성하는 효과적이고 확장 가능한 프레임워크임을 확립합니다.
One-sentence Summary
The Qwen Team and Tsinghua University introduce HopChain, a scalable framework synthesizing multi-hop vision-language reasoning data to address fine-grained errors in VLMs. By generating logically dependent, instance-grounded chains with verifiable numeric answers, HopChain significantly boosts generalizable performance across diverse benchmarks, particularly excelling in long CoT reasoning scenarios.
Key Contributions
- The paper introduces HopChain, a scalable framework that synthesizes multi-hop vision-language reasoning data by constructing logically dependent chains where earlier hops establish instances or conditions required for subsequent steps, ensuring continuous visual re-grounding.
- This work demonstrates that training VLMs with HopChain's synthesized data improves performance on 20 of 24 diverse benchmarks, including STEM, General VQA, and Video Understanding, indicating broad and generalizable gains without benchmark-specific tailoring.
- Experiments show that multi-hop reasoning gains peak in long-CoT regimes with improvements exceeding 50 points, while ablation studies confirm that reducing chain complexity significantly lowers average scores, validating the necessity of full multi-hop structures for robust reasoning.
Introduction
Vision-language models (VLMs) excel at multimodal tasks but often fail during long chain-of-thought reasoning due to compounding errors like hallucination and weak visual grounding. Existing training data for reinforcement learning with verifiable rewards (RLVR) rarely requires complex, multi-step visual evidence, leaving these critical weaknesses unaddressed during model optimization. The authors introduce HopChain, a scalable framework that synthesizes multi-hop reasoning data where each step logically depends on previous visual findings to force continuous re-grounding. This approach generates queries with verifiable numerical answers that expose diverse failure modes, resulting in broad performance gains across 20 of 24 benchmarks without targeting specific downstream tasks.
Dataset
-
Dataset Composition and Sources: The authors synthesize a multi-hop vision-language reasoning dataset designed to force models to seek visual evidence at every step of long-CoT reasoning. The data originates from raw image collections that contain sufficient detectable instances, processed through a four-stage pipeline to create queries that chain multiple reasoning steps into a single task.
-
Key Details for Each Subset:
- Reasoning Levels: Queries are structured as Level 3 tasks that combine Level 1 (single-object perception like text reading or attribute identification) and Level 2 (multi-object perception like spatial or counting relations).
- Hop Types: Each query must include both Perception-level hops (switching between single and multi-object tasks) and Instance-chain hops (moving to a new object based on the previous one).
- Answer Format: All queries terminate in a specific, unambiguous numerical answer to ensure compatibility with RLVR verification.
- Dependency Rules: Substeps must form a logically dependent chain where earlier hops establish the instances or conditions required for later hops, preventing shallow shortcuts.
-
Data Usage and Processing:
- Stage 1 (Category Identification): A VLM identifies semantic categories present in an input image without localization.
- Stage 2 (Instance Segmentation): SAM3 generates segmentation masks and bounding boxes to resolve categories into concrete, spatially localized instances.
- Stage 3 (Query Generation): The system forms combinations of 3–6 instances and uses a VLM to generate multi-hop queries. The model receives the original image plus cropped patches of each instance to aid design, though these patches are not available during the actual reasoning task.
- Stage 4 (Annotation and Calibration): Four human annotators independently solve each query; only queries where all four agree on the numerical answer are retained. Difficulty calibration then removes queries where a weaker model achieves 100% accuracy, ensuring the final dataset contains verified, challenging examples.
-
Cropping and Metadata Strategy:
- Cropping: During the design phase, the pipeline extracts cropped patches for each detected instance using bounding boxes. These patches serve as reference material for the VLM to understand appearance and location but are excluded from the final training prompt to simulate real-world conditions.
- Metadata Construction: The prompt explicitly provides the coordinates of each instance in a 0–1000 range and lists the specific object instances that must be considered for the task.
- Quality Control: The pipeline filters out queries with ambiguous references during human annotation and discards those that are too easy during model-based calibration, ensuring high-quality training signals.
Method
The authors propose a comprehensive framework that integrates scalable data synthesis with advanced reinforcement learning techniques to enhance the multi-hop reasoning capabilities of Vision-Language Models (VLMs). The methodology is divided into three core components: the generation of structured multi-hop training data, the formulation of the reinforcement learning objective, and the optimization algorithm used for policy updates.
Scalable Multi-Hop Data Synthesis
To address the lack of complex reasoning chains in typical training data, the authors leverage a scalable data synthesis pipeline designed to enforce dependency-linked hops with repeated visual grounding. Refer to the framework diagram for an overview of the HopChain Framework for Multi-Hop Data Synthesis.
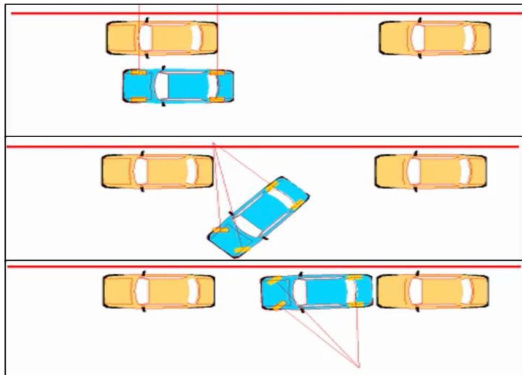
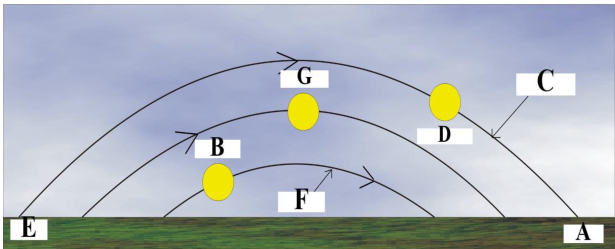
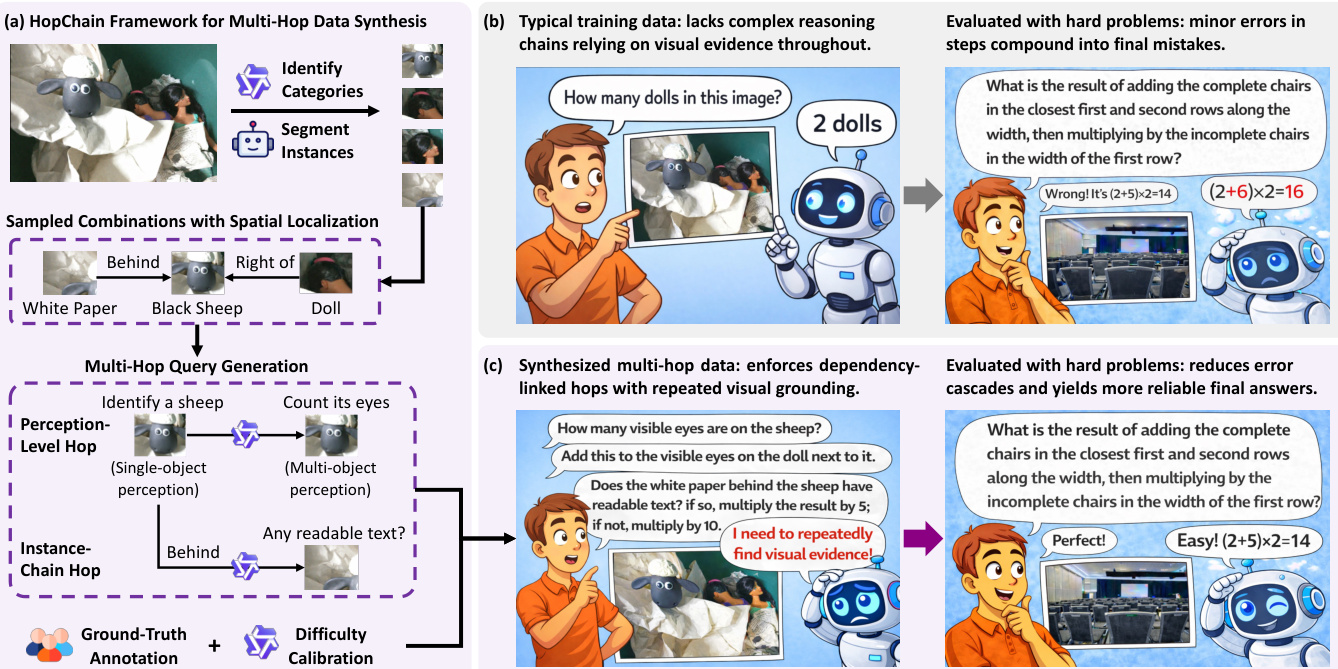 This pipeline utilizes strong foundation models, including VLMs for object detection and SAM for instance segmentation, to construct structured queries from raw images. The synthesis process imposes strict constraints to ensure high quality and generalizability. Each generated query must involve a genuine multi-hop reasoning structure where the instance required at the current hop can only be identified from instances established in earlier hops. Furthermore, the queries are designed to maximize instance coverage, ensuring that every object in a selected combination plays a meaningful role in the reasoning chain. The authors also enforce unambiguous phrasing and deterministic solutions, prohibiting the use of low-level visual features like bounding box colors to locate information. This approach forces the model to recover and retain intermediate visual evidence rather than relying on language-only heuristics. Examples of the visual complexity handled by this synthesis process include spatial reasoning tasks involving vehicle positions and logical reasoning tasks involving trajectory analysis.
This pipeline utilizes strong foundation models, including VLMs for object detection and SAM for instance segmentation, to construct structured queries from raw images. The synthesis process imposes strict constraints to ensure high quality and generalizability. Each generated query must involve a genuine multi-hop reasoning structure where the instance required at the current hop can only be identified from instances established in earlier hops. Furthermore, the queries are designed to maximize instance coverage, ensuring that every object in a selected combination plays a meaningful role in the reasoning chain. The authors also enforce unambiguous phrasing and deterministic solutions, prohibiting the use of low-level visual features like bounding box colors to locate information. This approach forces the model to recover and retain intermediate visual evidence rather than relying on language-only heuristics. Examples of the visual complexity handled by this synthesis process include spatial reasoning tasks involving vehicle positions and logical reasoning tasks involving trajectory analysis.
Reinforcement Learning with Verifiable Rewards The training process employs Reinforcement Learning with Verifiable Rewards (RLVR) for VLMs. This framework closely parallels RLVR for Large Language Models but processes both an image and a text query as input to generate a textual chain-of-thought culminating in a verifiable answer prediction. The primary objective is to maximize the expected reward, defined as:
J(π)=E(I,q,a)∼D,o∼π(⋅∣I,q)[R(o,a)],whereR(o,a)={1.00.0if is_equivalent(o,a),otherwise.Here, I, q, and a denote the image, text query, and ground-truth answer, respectively, sampled from dataset D, and o represents the response generated by policy π conditioned on I and q. The reward function provides a binary signal based on whether the generated output is equivalent to the ground truth.
Soft Adaptive Policy Optimization To mitigate potential instability and inefficiency caused by hard clipping in prior RLVR algorithms, the authors introduce Soft Adaptive Policy Optimization (SAPO). This method substitutes hard clipping with a temperature-controlled soft gate. The optimization objective for VLMs is formulated as:
J(θ)=E(I,q,a)∼D,{oi}i=1G∼πold(⋅∣I,q)G1i=1∑G∣oi∣1t=1∑∣oi∣fi,t(ri,t(θ))A^i,t,where the probability ratio ri,t(θ) is defined as the ratio of the current policy to the old rollout policy. The advantage term A^i,t is computed by normalizing the reward Ri across a group of samples. The function fi,t(x) acts as a soft gate controlled by temperatures τpos and τneg for positive and negative tokens, respectively. This adaptive mechanism allows for smoother policy updates and improved training stability compared to traditional clipping methods.
Experiment
- Analysis of diverse failure modes in long Chain-of-Thought reasoning reveals that errors are not isolated but compounding, with perception mistakes often triggering downstream reasoning, knowledge, and hallucination failures across various visual scenarios.
- Main benchmark evaluations demonstrate that augmenting standard RLVR training with HopChain-synthesized multi-hop data yields broad, generalizable improvements across 20 out of 24 benchmarks for both small and large model scales, covering STEM, general VQA, document understanding, and video tasks.
- Ablation studies confirm that preserving the full multi-hop structure during training is essential, as models trained on shortened or single-hop variants show significantly lower performance, validating the necessity of maintaining long cross-hop dependencies.
- Further analysis indicates that the proposed method effectively strengthens robustness in ultra-long reasoning chains, covers a wide spectrum of query difficulties, and corrects a diverse range of error types rather than addressing only a narrow subset of failure modes.