Command Palette
Search for a command to run...
비디오 추론의 신비 해명
비디오 추론의 신비 해명
초록
최근 비디오 생성 분야의 발전은 diffusion 기반 비디오 모델이 상당한 추론 능력을 보인다는 예상치 못한 현상을 드러냈습니다. 기존 연구들은 이러한 능력을 프레임 간 순차적으로 전개된다고 가정하는 Chain-of-Frames (CoF) 메커니즘에 기인한다고 설명해 왔습니다. 본 논문에서는 이러한 가정을 재검토하며 근본적으로 다른 메커니즘을 규명합니다. 우리는 비디오 모델 내에서의 추론이 주로 diffusion denoising 단계들을 따라 발현됨을 보여줍니다. 질적 분석과 표적 프로빙 실험을 통해, 모델들이 초기 denoising 단계에서 여러 후보 해를 탐색하다가 점진적으로 최종 답으로 수렴하는 과정을 확인했으며, 이를 Chain-of-Steps (CoS) 라고 명명했습니다. 이 핵심 메커니즘 외에도 모델 성능에 결정적인 여러 발현적 추론 행위를 식별했습니다: (1) 지속적 참조를 가능하게 하는 작업 기억 (working memory), (2) 잘못된 중간 해로부터 복구를 허용하는 자기 수정 및 향상, (3) 초기 단계에서 의미적 기반을 확립하고 후기 단계에서 구조화된 조작을 수행하는 '행위 전 지각 (perception before action)'입니다. 또한 각 diffusion 단계 내에서 Diffusion Transformer 내부에서 스스로 진화한 기능적 분업화를 발견했는데, 초기 레이어는 밀집된 지각 구조를 인코딩하고, 중간 레이어는 추론을 실행하며, 후기 레이어는 잠재 표현을 통합합니다. 이러한 통찰에 기반하여, 우리는 개념 증명 (proof-of-concept) 으로 간단한 학습 불필요 전략을 제시하며, 서로 다른 random seeds 를 가진 동일한 모델들의 latent trajectories 를 앙상블함으로써 추론 능력을 향상시킬 수 있음을 실증했습니다. 종합적으로, 본 연구는 비디오 생성 모델에서 추론이 어떻게 발현되는지에 대한 체계적인 이해를 제공하며, 비디오 모델의 내재적 추론 역학을 새로운 지능의 기저 (substrate) 로 더 효과적으로 활용하기 위한 향후 연구를 위한 토대를 마련합니다.
One-sentence Summary
Researchers from SenseTime Research and Nanyang Technological University propose that video reasoning emerges via a Chain-of-Steps mechanism during diffusion denoising rather than across frames. This discovery reveals emergent behaviors like self-correction and enables a training-free strategy to enhance reasoning by ensembling latent trajectories.
Key Contributions
- The paper introduces the Chain-of-Steps (CoS) mechanism, demonstrating that reasoning in diffusion-based video models unfolds along denoising steps rather than across frames, where models explore multiple candidate solutions early and progressively converge to a final answer.
- This work identifies three emergent reasoning behaviors critical to performance: working memory for persistent reference, self-correction capabilities to recover from intermediate errors, and a perception-before-action dynamic where early steps establish semantic grounding before later steps perform manipulation.
- A training-free inference strategy is presented that improves reasoning by ensembling latent trajectories from identical models with different random seeds, with experiments showing this approach retains diverse reasoning paths and increases the likelihood of converging to correct solutions.
Introduction
Diffusion-based video models have recently demonstrated unexpected reasoning capabilities in spatiotemporally consistent environments, offering a new substrate for machine intelligence beyond static images and text. Prior research incorrectly attributed this ability to a Chain-of-Frames mechanism where reasoning unfolds sequentially across video frames, leaving the true internal dynamics largely unexplored. The authors challenge this assumption by revealing that reasoning primarily emerges along the diffusion denoising steps, a process they term Chain-of-Steps. They identify critical emergent behaviors such as working memory, self-correction, and functional layer specialization within the model architecture. Leveraging these insights, the team introduces a simple training-free strategy that ensembles latent trajectories from multiple model runs to improve reasoning performance by preserving diverse candidate solutions during generation.
Method
The proposed framework is built upon VBVR-Wan2.2, a video reasoning model finetuned from the Wan2.2-I2V-A14B architecture using flow matching. The core mechanism treats the diffusion denoising process as a primary axis for reasoning. The model learns a velocity field vθ(xs,s,c) conditioned on a prompt c, guiding the latent xs along a continuous transport path defined by xs=(1−s)x0+sx1, where x0 is the clean latent and x1 is noise. By estimating the clean latent at each step via x^0=xs−σs⋅vθ(xs,s,c), the system visualizes the evolution of semantic decisions. This analysis reveals that early diffusion steps function as a high-level heuristic search where the model populates the latent workspace with multiple hypotheses, while later steps prune suboptimal trajectories to converge on a solution.
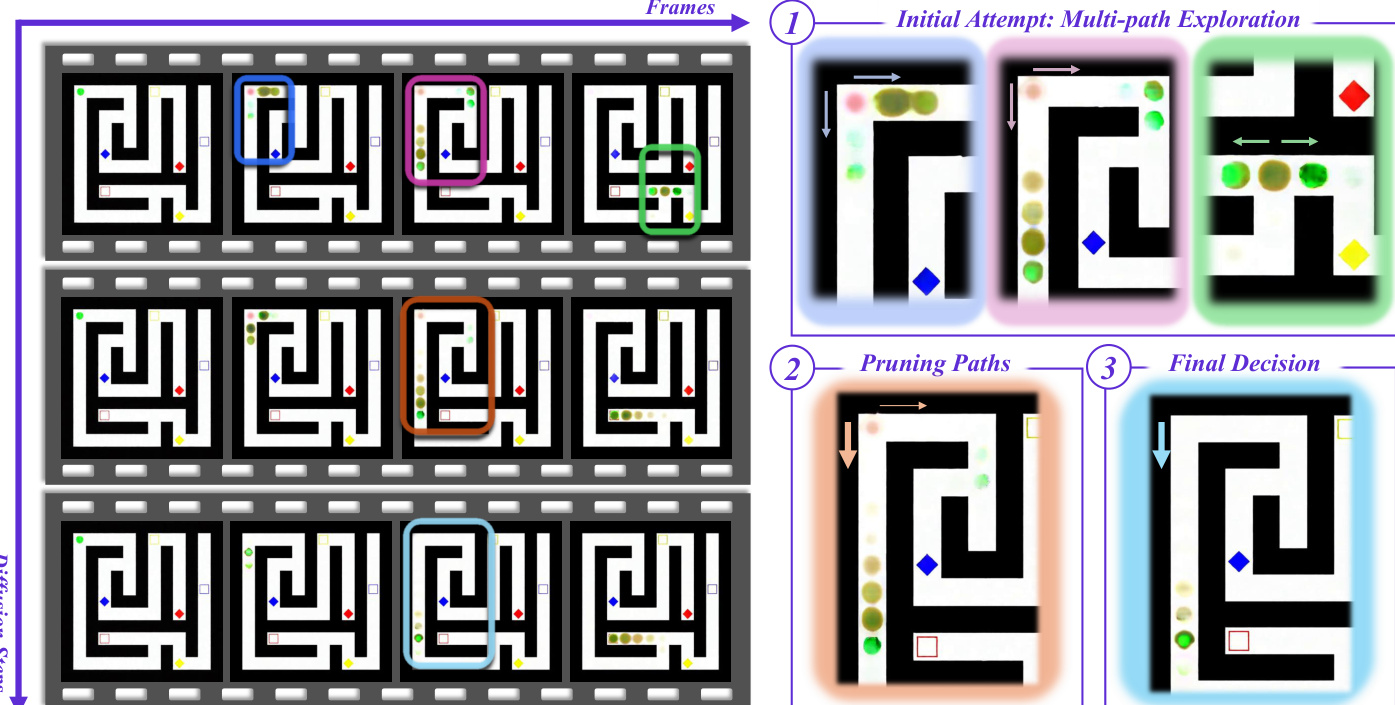
Refer to the framework diagram for a visualization of this multi-path exploration and subsequent pruning in a maze-solving task.
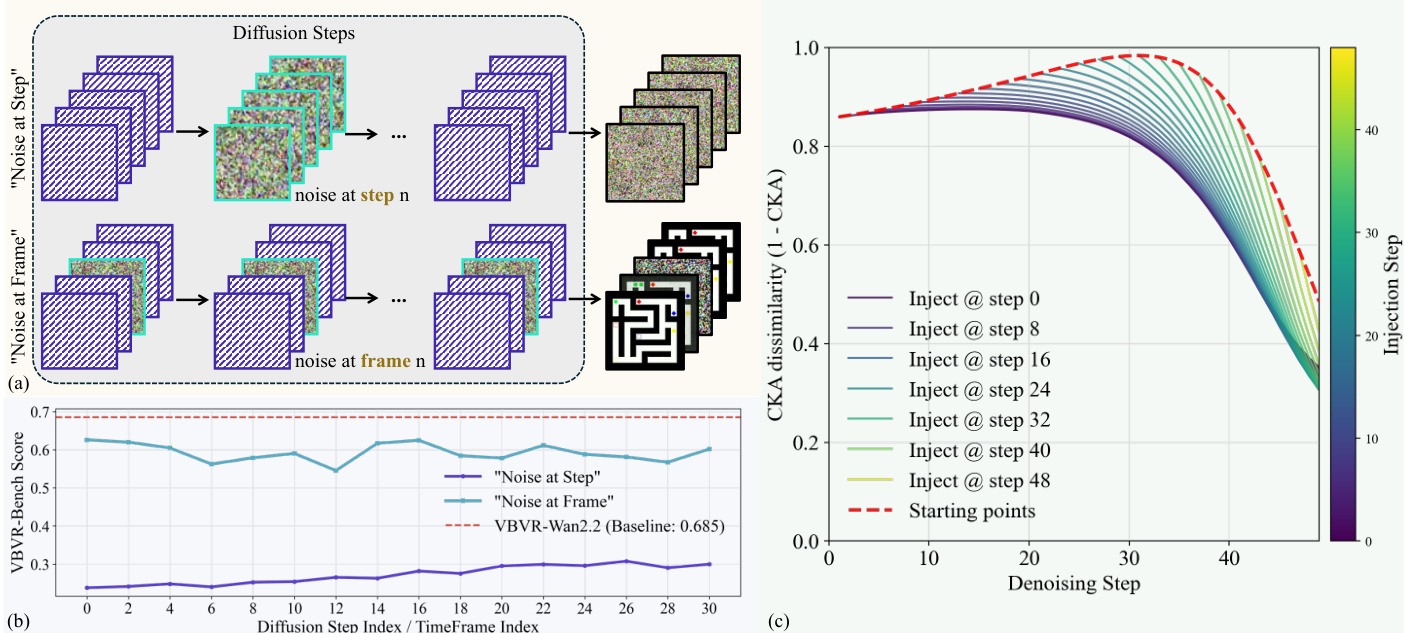
The study further analyzes the impact of noise injection strategies on the reasoning trajectory, comparing noise at specific diffusion steps versus frames.
Two distinct modes of step-wise reasoning are identified: Multi-path Exploration, where parallel possibilities are spawned, and Superposition-based Exploration, where patterns are completed through overlapping states.
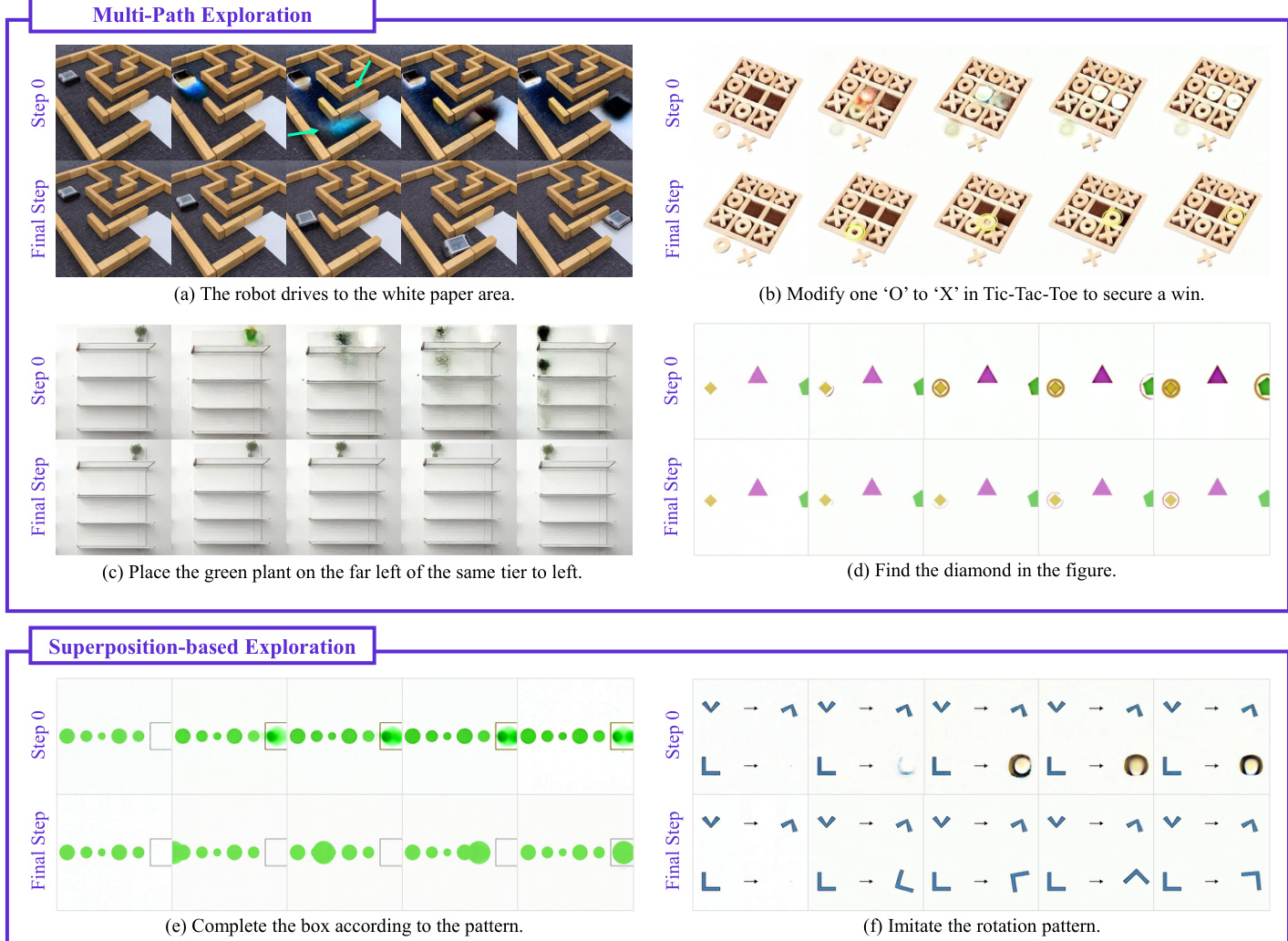
The architecture exhibits emergent reasoning behaviors critical for complex tasks, including working memory to retain essential information and self-correction to refine intermediate hypotheses.

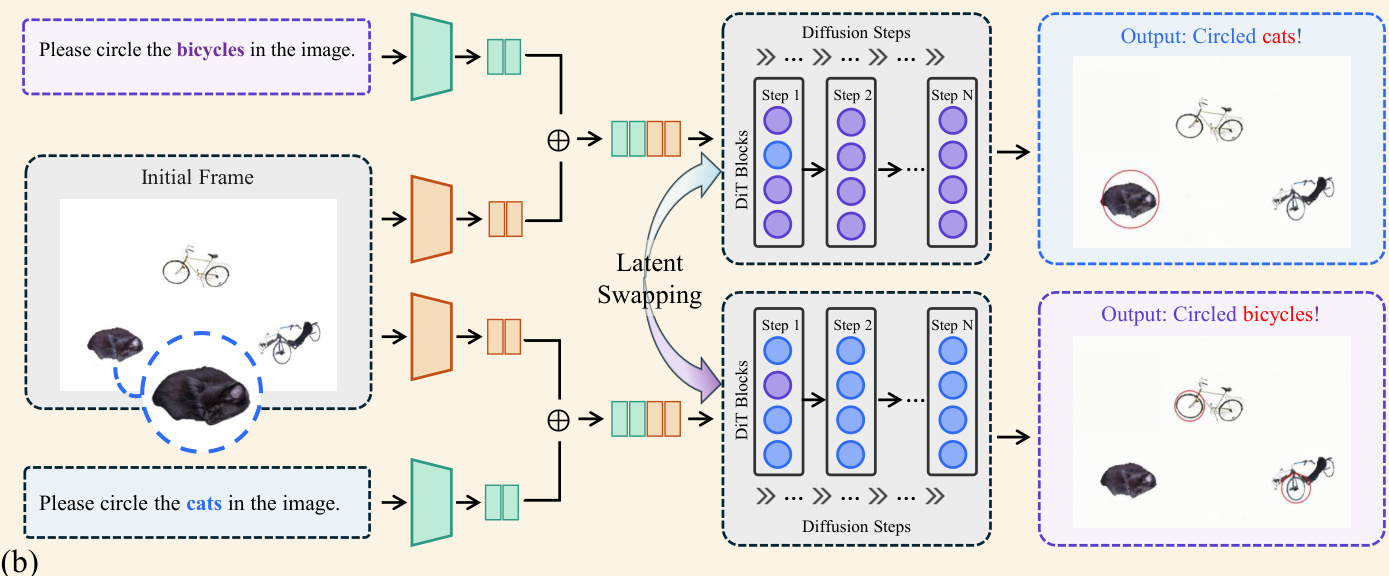
To stabilize these reasoning trajectories, a training-free ensemble strategy is implemented. This method exploits the shared probabilistic bias in the reasoning manifold by executing multiple independent forward passes with different initial noise seeds. During the critical early diffusion steps, hidden representations from the mid-layers (specifically layers 20 to 29) are extracted and spatially-temporally averaged. This latent-space ensemble filters out seed-specific noise and steers the probability distribution toward a more stable state.
Experiment
- Chain-of-Steps analysis validates that video reasoning occurs across diffusion denoising steps rather than frame-by-frame, with models exploring multiple solution paths in parallel before converging to a final outcome.
- Noise perturbation experiments confirm that disrupting specific diffusion steps severely degrades performance, whereas corrupting individual frames is more easily recovered, proving that the reasoning trajectory is highly sensitive to step-wise information flow.
- Layer-wise mechanistic analysis reveals a hierarchical processing structure where early transformer layers focus on global background context, while middle and later layers concentrate on foreground objects and execute critical logical reasoning.
- Latent swapping experiments demonstrate that middle layers encode semantically decisive information, as altering representations at these specific depths directly reverses the final inference results.
- Investigations into frame counts and model distillation show that while reasoning is not strictly frame-dependent, maintaining a minimum number of frames is essential for spatiotemporal coherence, and aggressive step compression in distilled models can collapse the latent exploration phase required for effective reasoning.
- Qualitative observations identify emergent behaviors such as working memory for preserving object states, self-correction mechanisms that refine incorrect initial hypotheses, and a "perception before action" transition where static grounding precedes dynamic motion planning.