Command Palette
Search for a command to run...
SocialOmni: Omni Models의 오디오-비주얼 사회적 상호작용(Audio-Visual Social Interactivity) 벤치마킹
SocialOmni: Omni Models의 오디오-비주얼 사회적 상호작용(Audio-Visual Social Interactivity) 벤치마킹
초록
Omni-modal large language models (OLMs)는 오디오, 비전, 텍스트를 네이티브하게 통합함으로써 인간과 기계의 상호작용을 재정의하고 있습니다. 그러나 기존의 OLM benchmark는 정적이고 정확도 중심적인 작업에 머물러 있어, 자연스러운 대화 속에서 동적인 단서(dynamic cues)를 탐색하는 근본적인 능력인 '사회적 상호작용성(social interactivity)'을 평가하는 데 있어 중대한 공백이 존재합니다.이를 해결하기 위해, 본 연구에서는 대화의 상호작용성을 세 가지 핵심 차원에서 실질적으로 평가할 수 있는 포괄적인 benchmark인 SocialOmni를 제안합니다. 세 가지 차원은 다음과 같습니다: (i) 화자 분리 및 식별(who is speaking), (ii) 개입 타이밍 제어(when to interject), (iii) 자연스러운 개입 생성(how to phrase the interruption)입니다.SocialOmni는 2,000개의 인지(perception) 샘플과 엄격한 시간적·맥락적 제약 조건이 적용된 209개의 품질 관리된 진단용 interaction-generation 인스턴스로 구성되어 있으며, 모델의 강건성(robustness)을 테스트하기 위해 제어된 오디오-비주얼 불일치(audio-visual inconsistency) 시나리오를 포함하고 있습니다. 12개의 주요 OLM을 대상으로 benchmark를 수행한 결과, 모델별로 사회적 상호작용 능력에서 상당한 차이가 있음을 확인했습니다.
One-sentence Summary
The authors propose SocialOmni, a comprehensive benchmark for omni-modal large language models designed to assess social interactivity beyond static tasks by operationalizing speaker separation and identification, interruption timing control, and natural interruption generation using 2,000 perception samples and 209 quality-controlled interaction-generation instances, complemented by controlled audio-visual inconsistency scenarios to evaluate 12 leading OLMs and uncover significant variance in their social-interaction capabilities.
Key Contributions
- The paper introduces SocialOmni, a comprehensive benchmark that operationalizes the evaluation of conversational interactivity across speaker separation, interruption timing, and natural interruption generation. This benchmark assesses dynamic cues in natural dialogues to evaluate social interactivity capabilities.
- SocialOmni features 2,000 perception samples and a quality-controlled diagnostic set of 209 interaction-generation instances with strict temporal and contextual constraints. The dataset includes controlled audio-visual inconsistency scenarios to test model robustness against multimodal conflicts.
- Benchmarking 12 leading OLMs uncovers significant variance in their social-interaction capabilities across different models. These results demonstrate the benchmark's ability to reveal performance gaps in turn-entry decisions and interruption handling.
Introduction
Omni-modal large language models integrate audio, vision, and text to support real-time multimodal conversation where success depends on interaction competence like turn timing and social coherence rather than just factual accuracy. Existing benchmarks focus on static accuracy and fail to assess coherent understanding across multi-turn dialogues. Prior behavior-centric work often isolates single facets without evaluating perception and social appropriateness simultaneously. To close this gap, the authors introduce SocialOmni to evaluate social interactivity across speaker identification, turn timing, and interruption generation. They also propose a dual-axis protocol to decouple perception from generation and design probes to quantify robustness under audio-visual conflicts.
Dataset
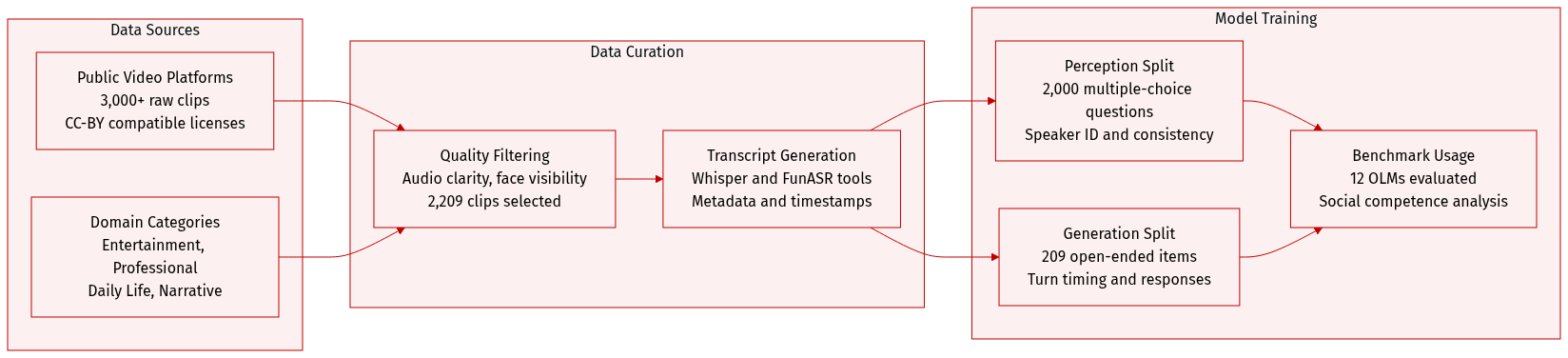
-
Dataset Composition and Sources
- The authors compile over 3,000 raw videos from public platforms ensuring CC-BY-compatible licenses.
- Content is organized into four domains including Entertainment, Professional, Daily Life, and Narrative across 15 subcategories.
-
Key Details for Each Subset
- Strict filtering for audio clarity, face visibility, and turn structure reduces the pool to 2,209 clips with a mean duration of 25.0 seconds.
- The Perception split contains 2,000 multiple-choice questions split into 1,725 consistent and 275 inconsistent audio-visual scenarios.
- The Generation split features 209 open-ended items with multi-reference responses to support robust evaluation of conversational turns.
-
How the Paper Uses the Data
- SocialOmni functions as a benchmark to evaluate 12 leading Omni-modal Large Language Models rather than for model training.
- Task I tests speaker identification capabilities at specific timestamps.
- Task II measures turn-taking timing and response generation quality based on video and audio prefixes.
-
Processing and Metadata Construction
- Automatic transcripts are generated using Whisper and FunASR to create answer options and evaluation references.
- Options are synthesized by permuting speaker identity and content to isolate visual grounding errors from speech recognition errors.
- Released metadata includes video URLs, timestamps, transcript segments, consistency labels, and adjudication flags subject to licensing constraints.
Method
The SocialOmni framework is designed to evaluate large multimodal models on social interaction capabilities, specifically focusing on perception and generation tasks across diverse domains. The benchmark comprises 2209 videos spanning 15 distinct domains, structured around two primary tasks that assess the model's ability to understand social cues and generate appropriate responses.
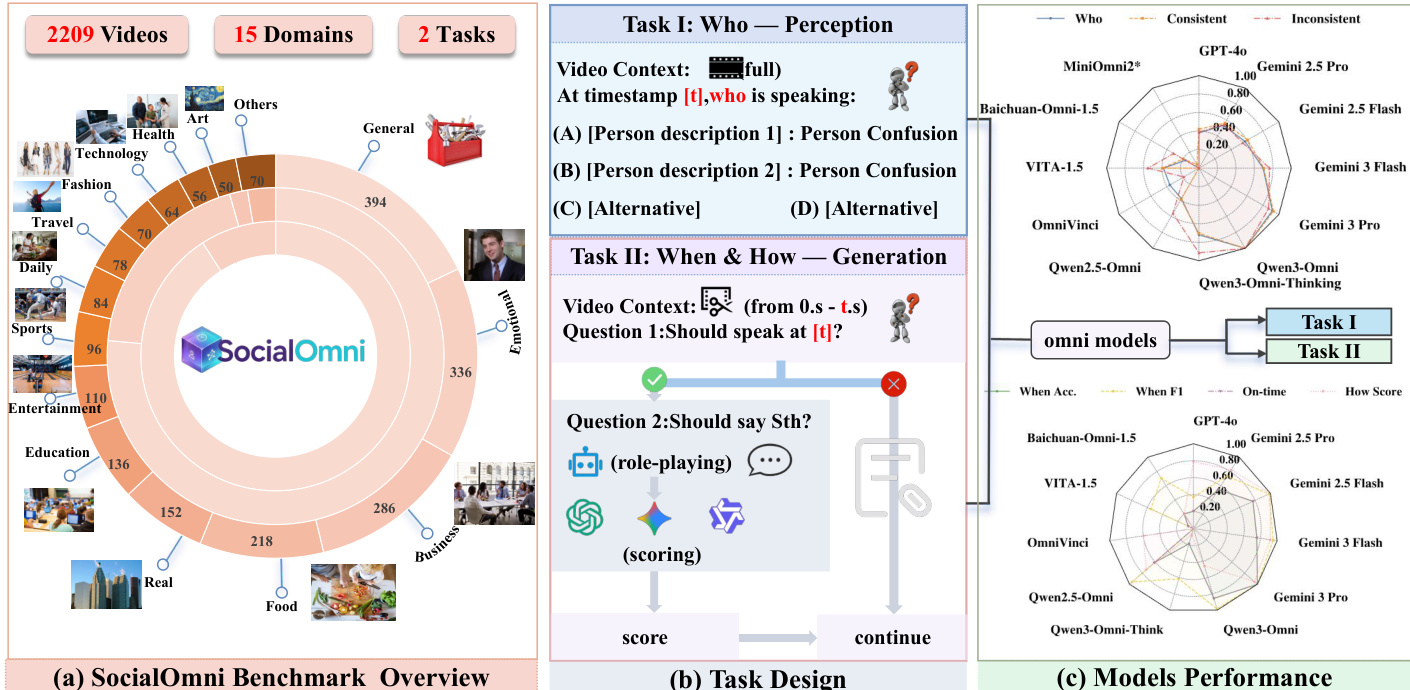
The core processing pipeline is divided into three zones to handle context alignment and task execution. Zone 1 establishes the video and audio context, identifying specific timestamps and ground truth text. Zone 2 performs an audio-vision consistency check. The system analyzes whether the visual speaker matches the active audio source. For instance, if the visual shows a person with closed lips while the audio indicates a voice active on the opposite side, the input is flagged as inconsistent. This consistency check is crucial for determining the ground truth for speaker attribution.
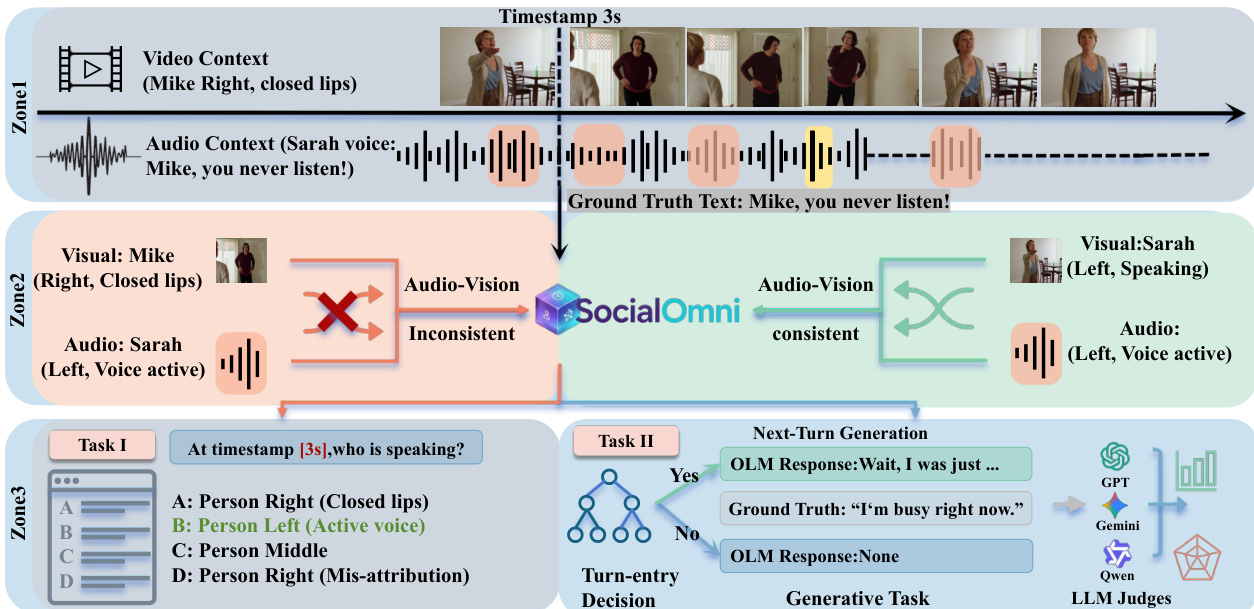
The evaluation is split into Task I (Perception) and Task II (Generation). Task I asks the model to identify the speaker at a specific timestamp using a multiple-choice format with options A through D. Task II involves a two-step generation process. First, the model must decide whether it is appropriate to speak (Turn-entry Decision). If the decision is positive, the model proceeds to the Generative Task, producing a natural response. These outputs are then evaluated by LLM judges to assess quality and relevance.
To quantify timing accuracy, the authors define a timing label ci based on the response offset Δτi=τ^i−τi∗. Responses are categorized into five classes: INTERRUPTED if Δτi<−θ1, PERFECT if −θ1≤Δτi≤θ2, DELAYED if θ2<Δτi≤θ3, TOOLATE if Δτi>θ3, and NO RESPONSE if no output is generated. The default thresholds are set to (θ1,θ2,θ3)=(1,2,5) seconds.

Finally, the system employs fixed prompt cards with strict parsing constraints to minimize variance across different model APIs. For the "Who" task, the model must output a single option letter. For the "When" task, only unambiguous YES or NO outputs are accepted. For the "How" task, non-empty continuations are retained for judging, while empty responses are recorded as no-response.
Experiment
The SocialOmni benchmark evaluates twelve omni-modal large language models across three dimensions of social interactivity: speaker identification, interruption timing, and natural response generation. Experiments reveal that no single model dominates all axes, highlighting a significant decoupling where strong perception accuracy does not ensure high-quality conversational generation. Diagnostic analysis identifies systemic failure modes such as cross-modal temporal incoherence and premature interruption, indicating that current systems struggle to align visual grounding with conversational flow. These results demonstrate that understanding-centric benchmarks are insufficient for characterizing social competence and motivate dedicated interaction-oriented evaluation.
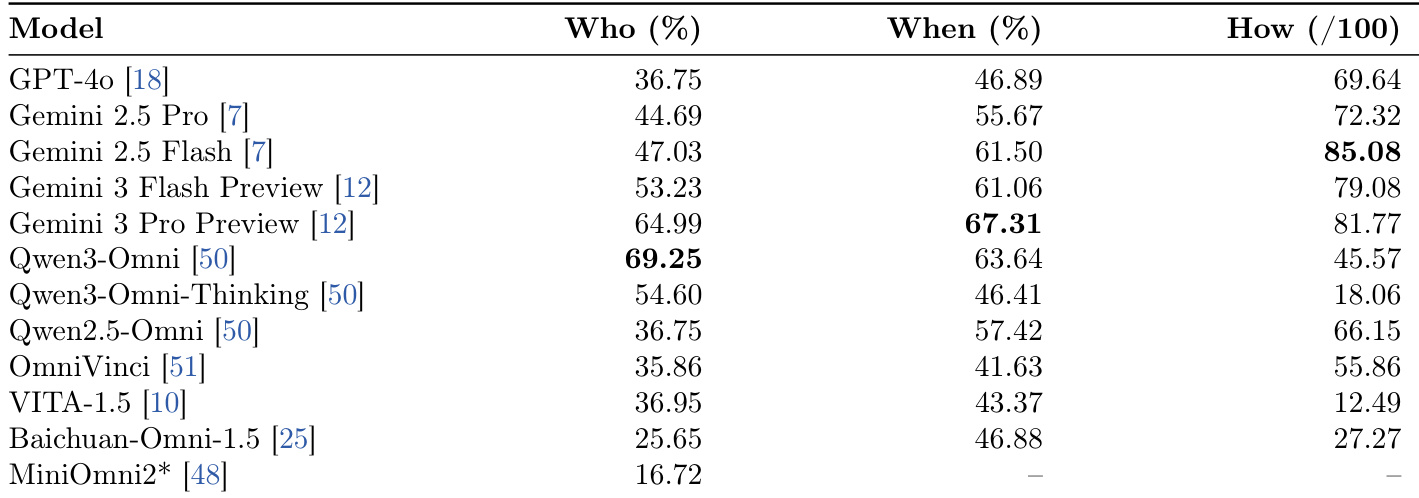
The the the table presents evaluation results for the speaker identification task, comparing accuracy and macro-F1 scores across various omni-modal models. Qwen3-Omni achieves the highest performance metrics, surpassing commercial models like Gemini 3 Pro Preview and GPT-4o. There is a clear distinction in capability, with top models significantly outperforming lower-ranked open-source alternatives. Qwen3-Omni leads the comparison with the highest accuracy and macro-F1 scores. Commercial models generally perform well but do not surpass the top open-source model. Performance varies widely, with some models scoring substantially lower than the leaders.
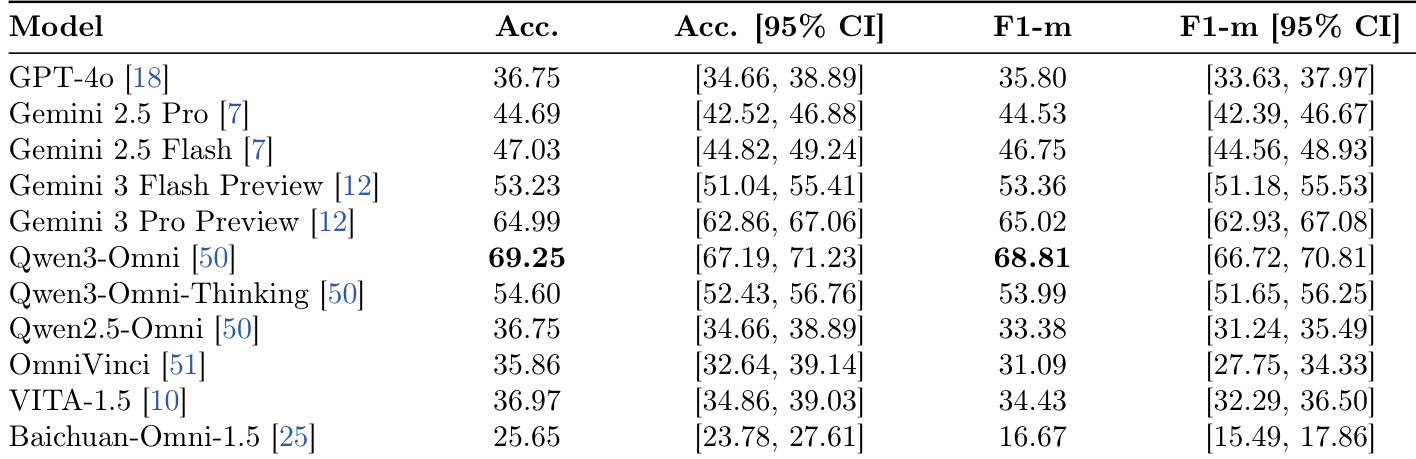
The study evaluates twelve omni-modal models across three dimensions of social interaction: speaker identification, interruption timing, and response generation. Results reveal that no single model dominates all axes, with specific models leading in perception while others excel in generation quality. Additionally, commercial systems generally outperform open-source counterparts, particularly in producing contextually appropriate conversational continuations. Distinct leaders emerge for each dimension, with Qwen3-Omni leading in speaker identification and Gemini 2.5 Flash leading in response quality. A decoupling exists between perception and generation, as models with high speaker identification accuracy do not necessarily produce natural interruptions. Commercial APIs demonstrate a substantial advantage over open-source models, especially regarding the fluency and relevance of generated responses.
The authors present a comparison between model performance on a full benchmark and human performance on a challenging selected subset. Humans demonstrate significantly higher accuracy than the average model on the selected subset for speaker identification and timing control. Although top models on the full benchmark score higher on response quality than humans on the subset, they still fall short of human performance in perception and timing tasks. Humans significantly outperform the average model on the selected subset across all three evaluation axes. The best models on the full benchmark achieve higher generation quality scores than humans on the selected subset but underperform humans on perception and timing. Model performance degrades drastically on the selected subset compared to the full benchmark, highlighting specific weaknesses in handling difficult scenarios.

The the the table presents correlation statistics comparing model performance against human judgments on a challenging subset of the SocialOmni benchmark. A significant negative correlation is observed for the "When" axis at the item level, suggesting that models often interrupt prematurely based on acoustic cues while human raters prioritize semantic completion. In contrast, model-level comparisons for the "When" axis show wide confidence intervals, reflecting uncertainty due to the limited number of evaluated models. Item-level analysis reveals a negative correlation on the "When" axis, indicating a divergence between model timing strategies and human expectations. The "Who" axis shows a negative but statistically non-significant correlation at the item level, suggesting weak alignment on speaker identification for difficult cases. Model-level comparisons for the "When" axis yield wide confidence intervals, indicating uncertainty due to the small sample size of evaluated models.

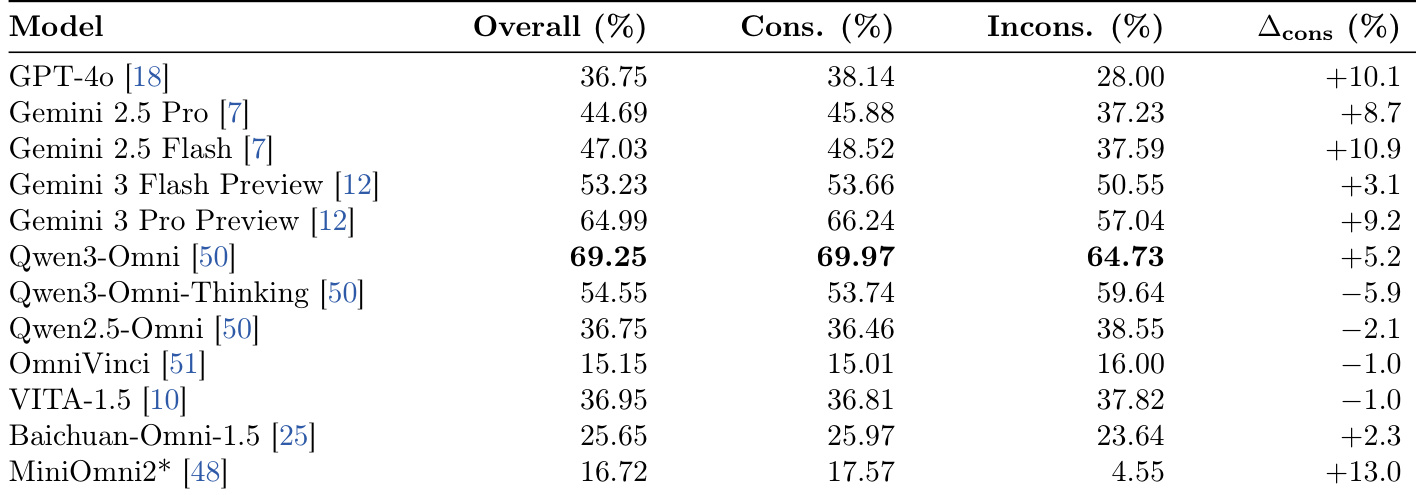
The the the table presents speaker identification accuracy for various omni-modal models, separating performance on clips with consistent audio-visual cues from those with inconsistent cues. It highlights the consistency gap to measure model robustness when visual and audio signals conflict. Qwen3-Omni achieves the highest overall accuracy and consistency rates, outperforming both commercial APIs and open-source alternatives. MiniOmni2 exhibits the largest consistency gap, indicating it is highly sensitive to cross-modal misalignment compared to other models. Qwen3-Omni-Thinking shows a negative consistency gap, performing worse on consistent clips than on inconsistent ones, suggesting reasoning overhead may hinder simple perception tasks.
The study evaluates twelve omni-modal models across social interaction dimensions including speaker identification, interruption timing, and response generation, revealing that no single system dominates all axes. While commercial systems generally excel in generation quality, Qwen3-Omni leads in perception tasks, yet humans significantly outperform models on challenging subsets regarding timing and identification accuracy. Furthermore, analysis indicates a divergence between model and human timing strategies, alongside varying robustness to conflicting audio-visual cues where reasoning overhead can hinder simple perception.