Command Palette
Search for a command to run...
OpenSeeker: 훈련 데이터를 완전히 오픈소스화하여 최전선 검색 에이전트의 민주화를 실현하다
OpenSeeker: 훈련 데이터를 완전히 오픈소스화하여 최전선 검색 에이전트의 민주화를 실현하다
Yuwen Du Rui Ye Shuo Tang Xinyu Zhu Yijun Lu Yuzhu Cai Siheng Chen
초록
선진형 대형 언어 모델(LLM) 에이전트에게 심층 검색(deep search) 능력은 필수적인 역량이 되었으나, 투명하고 고품질의 학습 데이터 부재로 인해 고성능 검색 에이전트 개발은 여전히 산업계 거대 기업들이 주도하고 있습니다. 이러한 지속적인 데이터 부족은 해당 분야에서 연구 및 혁신을 추진하는 광범위한 연구 커뮤니티의 진전을 근본적으로 저해해 왔습니다. 이러한 격차를 해소하기 위해 우리는 OpenSeeker 를 소개합니다. OpenSeeker 는 두 가지 핵심 기술 혁신을 통해 선진 수준의 성능을 달성한 최초의 완전 오픈소스 검색 에이전트(모델 및 데이터 모두 포함)입니다. (1) 사실 기반 확장 가능한 제어형 질문-답변(QA) 합성: 웹 그래프를 위상적 확장과 엔티티 은폐를 통해 역공학하여, 제어 가능한 커버리지와 복잡성을 가진 복잡한 멀티홉 추론 과제를 생성합니다. (2) 노이즈 제거 궤적 합성: 사후 요약 메커니즘을 활용하여 궤적의 노이즈를 제거함으로써, 교사 LLM 들이 고품질 행동을 생성하도록 유도합니다. 실험 결과에 따르면, OpenSeeker 는 단 한 번의 학습 실행으로 11.7k 개의 합성 샘플만으로 학습되었으며, BrowseComp, BrowseComp-ZH, xbench-DeepSearch, WideSearch 등 여러 벤치마크에서 최첨단(state-of-the-art) 성능을 달성했습니다. 특히, 단순한 지도 미세 조정(SFT)으로 학습된 OpenSeeker 는 두 번째로 성능이 높은 완전 오픈소스 에이전트인 DeepDive 보다 BrowseComp 에서 현저히 우수한 성능(29.5% 대 15.3%)을 보였으며, 광범위한 연속 사전 학습, SFT, 강화 학습(RL)을 통해 학습된 산업계 경쟁사인 Tongyi DeepResearch 보다도 BrowseComp-ZH 에서 더 높은 성능(48.4% 대 46.7%)을 기록했습니다. 우리는 선진 검색 에이전트 연구의 민주화와 더 투명하고 협력적인 생태계 조성을 위해 완전한 학습 데이터셋과 모델 가중치를 모두 오픈소스로 공개합니다.
One-sentence Summary
Researchers from Shanghai Jiao Tong University introduce OpenSeeker, a fully open-source search agent that leverages fact-grounded scalable QA synthesis and denoised trajectory techniques to achieve state-of-the-art performance on complex benchmarks using simple supervised fine-tuning.
Key Contributions
- The paper introduces a fact-grounded scalable controllable QA synthesis method that reverse-engineers the web graph through topological expansion and entity obfuscation to generate complex, multi-hop reasoning tasks with adjustable difficulty.
- A denoised trajectory synthesis technique is presented that employs retrospective summarization to clean historical context for teacher models, enabling the generation of high-quality action sequences while training the agent on raw, noisy data to improve robustness.
- The work releases the fully open-source OpenSeeker agent, including its complete training dataset and model weights, which achieves state-of-the-art performance on multiple benchmarks using only simple supervised fine-tuning on 11.7k synthesized samples.
Introduction
Deep search capabilities are now essential for Large Language Model agents to navigate the internet for accurate, real-time information, yet this field has been dominated by industrial giants due to a lack of transparent, high-quality training data. Prior open-source efforts have failed to bridge this gap because they either withhold their training datasets, release only partial data, or rely on low-fidelity samples that cannot support frontier-level performance. To address these limitations, the authors introduce OpenSeeker, the first fully open-source search agent that achieves state-of-the-art results by leveraging two key innovations: fact-grounded scalable controllable QA synthesis to generate complex multi-hop reasoning tasks and denoised trajectory synthesis to teach models how to extract signals from noisy web content.
Dataset
-
Dataset Composition and Sources: The authors construct a high-fidelity dataset D comprising complex queries, ground truth answers, and optimal tool-use trajectories by reverse-engineering the web graph. They leverage approximately 68GB of English and 9GB of Chinese web data to anchor every query in real-world topology, ensuring factual grounding and eliminating hallucination risks.
-
Key Details for Each Subset: The synthesis pipeline operates in two phases: Generative Construction to create candidate pairs and Dual-Criteria Verification to filter for difficulty and solvability. Task difficulty is a deliberate design choice controlled by tuning the subgraph size k, which calibrates reasoning complexity and information coverage to create a curriculum ranging from straightforward retrieval to multi-hop investigations.
-
Model Usage and Training Strategy: The dataset trains an agent to master long-horizon tool invocation by forcing it to predict expert-level reasoning and tool calls conditioned on raw history. The training mixture utilizes the synthesized pairs to teach the model to handle complex queries that necessitate extended chains of "Reasoning → Tool Call → Tool Response" interactions.
-
Processing and Denoising Strategy: A unique asymmetry exists between synthesis and training. During synthesis, the authors employ a retrospective summarization mechanism where raw tool responses are condensed into summarized versions to help the teacher generate high-quality reasoning. However, the final training and inference phases operate exclusively on raw tool responses to force the model to intrinsically learn denoising capabilities and extract relevant information from noisy contexts.
Method
The proposed framework operates through two distinct phases: the generative construction of complex question-answer pairs and the synthesis of denoised reasoning trajectories.
Generative Construction and Verification
The authors leverage a graph-based pipeline to construct high-quality QA pairs, as illustrated in the framework diagram below.

The process begins with the QA Generation module. To mimic natural information discovery, the system samples a seed node vseed from a web corpus and expands it by traversing outgoing edges to form a local dependency subgraph Gsub. This subgraph serves as a topologically-linked knowledge base. To reduce noise, an extraction function identifies a central theme ytheme and distills key entities into a condensed Entity Subgraph Gentity. A generator Pgen then synthesizes an initial question qinit conditioned on Gentity, enforcing a structural constraint where deriving the answer requires traversing multiple edges.
To prevent agents from exploiting specific keywords, the pipeline applies obfuscation. An obfuscation operator Φ maps concrete entities e to vague descriptions e~=Φ(e), creating a Fuzzy Entity Subgraph G~entity. The final question q~ is generated by rewriting qinit to incorporate these ambiguous descriptions while preserving the reasoning logic.
Following generation, the QA Verifier module employs a rejection sampling scheme based on two criteria. First, a difficulty check ensures the question cannot be solved by a foundation model πbase in a closed-book setting (I[πbase(q~)=y]), guaranteeing the necessity of external tools. Second, a solvability check verifies logical consistency by confirming the model can derive the answer y when provided with the full Entity Subgraph Gentity as context (I[πbase(q~∣Gentity)=y]).
Denoised Trajectory Synthesis
To address the challenge of information retention versus context window constraints in web-scale search, the authors propose a synthesis framework that decouples the generation context from the training context. This process is visualized in the trajectory synthesis diagram below.
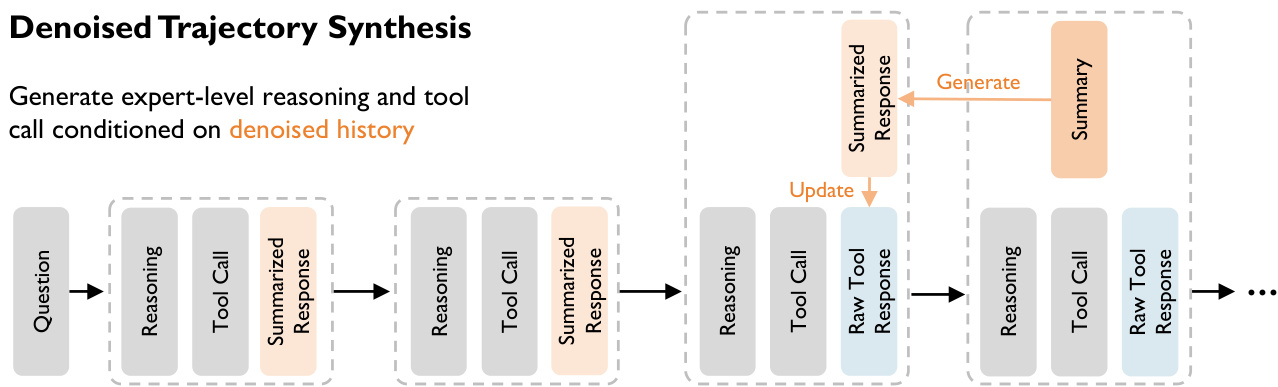
The synthesis employs a dynamic context denoising strategy using a "Summarized History + Raw Recent" protocol. At any turn t, the agent generates a reasoning and action pair (rt,at) based on a context Ht. This context includes a summarized long-term history where past observations oi are compressed into semantic summaries si, alongside the raw observation ot−1 from the immediately preceding step. This ensures the agent has access to all signals in the most recent observation while maintaining a concise memory of the past.
The framework operates in a two-phase cycle. During the decision phase, the agent utilizes the full raw observation ot−1 to inform its next move. In the subsequent compression phase, once a new observation ot is obtained, a summarizer compresses the previous observation ot−1 into st−1, which replaces the raw data in the long-term history for the next step.
Finally, the authors implement an asymmetric context training strategy to cultivate robustness. The trajectories are synthesized by a "Teacher" model using the clean, denoised context containing summaries. However, for the final training dataset, the "Student" model is supervised to predict the optimal reasoning and actions given the noisy raw context Httrain, which strips away the summaries. This forces the student model to implicitly learn the denoising and information extraction capabilities, internalizing the logic required to handle real-world unstructured data.
Experiment
- OpenSeeker, trained solely via supervised fine-tuning on a small, high-quality dataset, outperforms resource-intensive proprietary models and complex multi-stage training baselines on benchmarks testing multi-step navigation and deep research, validating that data quality surpasses training complexity.
- Comparisons with similarly sized models demonstrate that OpenSeeker's synthesized data is significantly more effective than larger, noisier datasets, proving that its denoised trajectory synthesis successfully teaches agents to extract critical information from complex web observations.
- Performance evaluations against concurrent academic and corporate works confirm that OpenSeeker achieves state-of-the-art results with full data transparency and a lean SFT-only approach, establishing that strategic data synthesis can replace massive compute and reinforcement learning cycles.
- Difficulty analysis reveals that the synthesized training data exceeds the complexity of standard benchmarks in terms of tool calls and token length, directly correlating this high-fidelity challenge with superior model performance on hard information-seeking tasks.