Command Palette
Search for a command to run...
Attention 잔차
Attention 잔차
초록
현대 LLM 에서는 PreNorm 을 적용한 잔차 연결 (residual connections) 이 표준으로 사용되고 있으나, 이러한 방식은 모든 층의 출력을 고정된 단위 가중치로 누적합니다. 이러한 균일한 집계는 네트워크 깊이가 깊어질수록 은닉 상태 (hidden state) 의 비제어적 성장을 초래하여 각 층의 기여도가 점진적으로 희석되는 문제를 야기합니다. 본 연구에서는 이를 해결하기 위해 Attention Residuals(AttnRes) 를 제안합니다. AttnRes 는 고정된 누적 방식을 이전 층들의 출력에 대한 softmax attention 으로 대체하여, 각 층이 학습된 입력 의존적 가중치를 통해 이전 표현들을 선택적으로 집계할 수 있도록 합니다. 대규모 모델 학습 시 모든 이전 층의 출력에 attention 을 적용할 때 발생하는 메모리 및 통신 오버헤드를 완화하기 위해, 우리는 Block AttnRes 를 도입하였습니다. Block AttnRes 는 층들을 블록 단위로 분할하고 블록 수준의 표현에 대해 attention 을 수행함으로써, 전체 AttnRes 의 이점을 대부분 유지하면서도 메모리 발자국 (memory footprint) 을 크게 줄입니다. 캐시 기반 파이프라인 통신 및 2 단계 계산 전략과 결합될 때, Block AttnRes 는 최소한의 오버헤드로 표준 잔차 연결을 대체할 수 있는 실용적인 솔루션이 됩니다. 스케일링 법칙 실험을 통해 모델 크기에 관계없이 개선 효과가 일관되게 나타남을 확인했으며, 절단 실험 (ablation studies) 을 통해 콘텐츠 의존적 깊이 방향 선택의 유효성을 검증하였습니다. 또한, 본 연구에서는 AttnRes 를 Kimi Linear 아키텍처(총 48B, 활성화 파라미터 3B) 에 통합하여 1.4T 토큰으로 사전 학습을 수행하였습니다. 그 결과, AttnRes 는 PreNorm 에 의한 희석 효과를 완화하여 깊이 전반에 걸쳐 더 균일한 출력 크기 및 기울기 분포를 달성하였으며, 평가된 모든 하류 작업에서 성능을 향상시켰습니다.
One-sentence Summary
The Kimi Team proposes Attention Residuals, a novel mechanism replacing fixed residual weights with learned softmax attention to mitigate hidden-state dilution in large language models. Their optimized Block AttnRes variant reduces memory overhead while significantly improving training stability and downstream task performance across various model scales.
Key Contributions
- The paper introduces Attention Residuals (AttnRes), a mechanism that replaces fixed unit-weight accumulation with learned softmax attention over preceding layer outputs to enable selective, content-dependent aggregation of representations across depth.
- To address scalability, the work presents Block AttnRes, which partitions layers into blocks and attends over block-level summaries to reduce memory and communication complexity from O(Ld) to O(Nd) while preserving performance gains.
- Comprehensive experiments on a 48B-parameter model pre-trained on 1.4T tokens demonstrate that the method mitigates hidden-state dilution, yields more uniform gradient distributions, and consistently improves downstream task performance compared to standard residual connections.
Introduction
The research addresses the challenge of efficiently scaling large language models while maintaining high performance, a critical need for deploying advanced AI in real-world applications. Prior approaches often struggle with the computational overhead of attention mechanisms or fail to fully utilize residual connections for stable training at scale. To overcome these limitations, the authors introduce a novel framework centered on attention residuals that optimizes information flow and reduces training costs without sacrificing model quality.
Method
The authors propose Attention Residuals (AttnRes) to address the limitations of standard residual connections in deep networks. In standard architectures, the hidden state update follows a fixed recurrence hl=hl−1+fl−1(hl−1), which unrolls to a uniform sum of all preceding layer outputs. This fixed aggregation causes hidden-state magnitudes to grow linearly with depth, diluting the contribution of individual layers. AttnRes replaces this fixed accumulation with a learned, input-dependent attention mechanism over depth.
Refer to the framework diagram for a visual comparison of the residual connection variants.
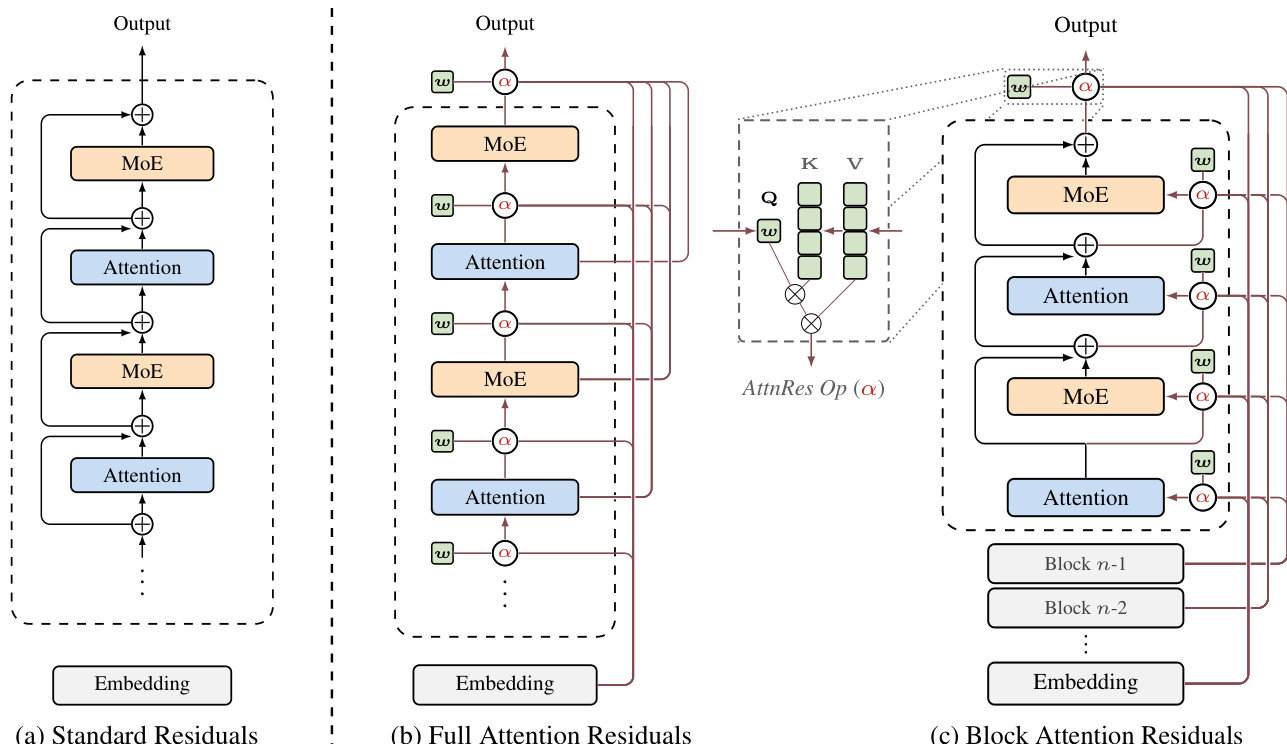
As shown in the figure, the standard approach (a) simply adds the previous layer output. In contrast, Full AttnRes (b) allows each layer to selectively aggregate all previous layer outputs via learned attention weights. Specifically, the input to layer l is computed as hl=∑i=0l−1αi→l⋅vi, where vi represents the output of layer i (or the embedding for i=0). The attention weights αi→l are derived from a softmax over a kernel function ϕ(ql,ki), where ql=wl is a learnable pseudo-query vector specific to layer l, and ki=vi are the keys derived from previous outputs. This mechanism enables content-aware retrieval across depth with minimal parameter overhead.
To make this approach scalable for large models, the authors introduce Block AttnRes (c). This variant partitions the L layers into N blocks. Within each block, layer outputs are reduced to a single representation via summation, and attention is applied only over the N block-level representations. This reduces the memory and communication complexity from O(Ld) to O(Nd). The intra-block accumulation is defined as bn=∑j∈Bnfj(hj), where Bn is the set of layers in block n. Inter-block attention then operates on these block summaries, allowing layers within a block to attend to previous blocks and the partial sum of the current block.
For efficient training at scale, the method incorporates specific infrastructure optimizations to handle the communication of block representations across pipeline stages. As illustrated in the pipeline communication example, cross-stage caching is employed to eliminate redundant data transfers.
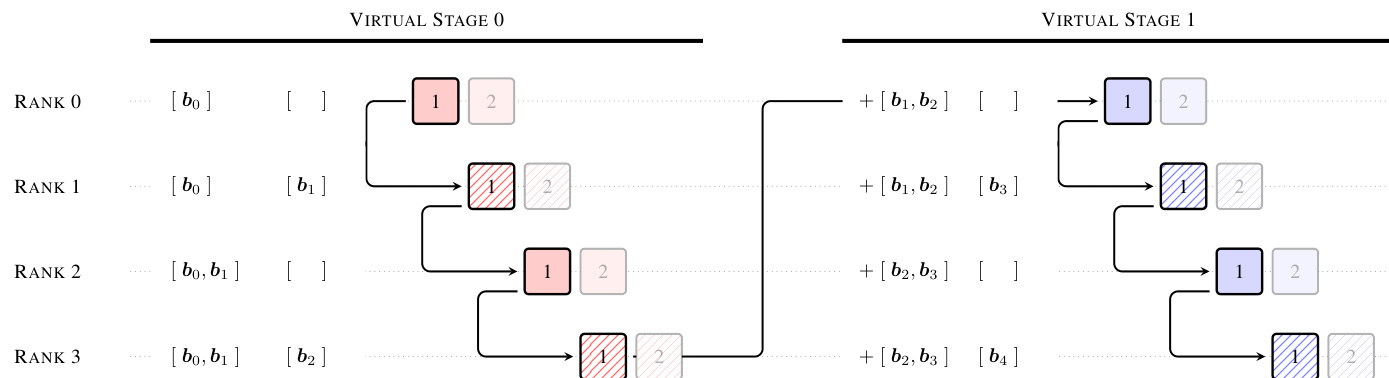
In this setup, blocks received during earlier virtual stages are cached locally. Consequently, stage transitions only transmit incremental blocks accumulated since the receiver's corresponding chunk in the previous virtual stage, rather than the full history. This caching strategy reduces the peak per-transition communication cost significantly, enabling the method to function as a practical drop-in replacement for standard residual connections with marginal training overhead. Additionally, a two-phase computation strategy is used during inference to amortize cross-block attention costs, further minimizing latency.
Experiment
- Scaling law experiments validate that both Full and Block Attention Residuals (AttnRes) consistently outperform the PreNorm baseline across all model sizes, with Block AttnRes recovering most of the performance gains of the full variant while maintaining lower memory overhead.
- Main training results demonstrate that AttnRes resolves the PreNorm dilution problem by bounding hidden-state growth and achieving a more uniform gradient distribution, leading to superior performance on multi-step reasoning, code generation, and knowledge benchmarks.
- Ablation studies confirm that input-dependent weighting via softmax attention is critical for performance, while block-wise aggregation offers an effective trade-off between memory efficiency and the ability to access distant layers compared to sliding-window or full cross-layer access.
- Architecture sweeps reveal that AttnRes shifts the optimal design preference toward deeper and narrower networks compared to standard Transformers, indicating that the method more effectively leverages increased depth for information flow.
- Analysis of learned attention patterns shows that AttnRes preserves locality while establishing learned skip connections to early layers and the token embedding, with Block AttnRes successfully maintaining these structural benefits through implicit regularization.