Command Palette
Search for a command to run...
Video-CoE: Chain of Events를 통한 비디오 이벤트 예측 강화
Video-CoE: Chain of Events를 통한 비디오 이벤트 예측 강화
Qile Su Jing Tang Rui Chen Lei Sun Xiangxiang Chu
초록
다양한 비디오 작업에 대한 MLLM 활용이 진전되었음에도 불구하고, 비디오 이벤트 예측(Video Event Prediction, VEP) 분야는 여전히 상대적으로 미개척 영역으로 남아 있습니다. VEP는 모델이 비디오에 대한 세밀한 temporal modeling을 수행하고, 비디오와 미래 이벤트 간의 논리적 관계를 구축할 것을 요구하는데, 현재의 MLLM은 여전히 이 부분에서 어려움을 겪고 있습니다.본 연구에서는 먼저 VEP 작업에 대한 현재 주요 MLLM들의 종합적인 평가를 제시하며, 미래 이벤트 예측을 위한 논리적 추론 능력의 부재 및 시각적 정보 활용의 미흡함 등 부정확한 예측이 발생하는 원인을 밝힙니다. 이러한 과제를 해결하기 위해, 본 연구에서는 Chain of Events (CoE) 패러다임을 제안합니다. CoE는 temporal event chain을 구축함으로써 MLLM이 시각적 콘텐츠와 비디오 및 미래 이벤트 사이의 논리적 연결에 암묵적으로 집중하도록 유도하며, 다양한 training protocols를 통해 모델의 추론 능력을 강화합니다.공개 benchmark를 통한 실험 결과, 제안된 방법론은 기존의 주요 오픈 소스 및 상용 MLLM 모두를 능가하였으며, VEP 작업에서 새로운 SOTA(state-of-the-art)를 달성했습니다.
One-sentence Summary
To address the limitations of current multimodal large language models in video event prediction, the paper propose Video-CoE, a Chain of Events paradigm that constructs temporal event chains and employs multiple training protocols to improve logical reasoning and visual information utilization, establishing a new state-of-the-art on public benchmarks.
Key Contributions
- This work provides a comprehensive evaluation of leading Multimodal Large Language Models (MLLMs) on the video event prediction (VEP) task, identifying critical deficiencies in logical reasoning and visual information utilization.
- The paper introduces the Chain of Events (CoE) paradigm, which employs CoE-SFT and CoE-GRPO training protocols to enable models to construct temporal event chains and establish logical connections between observed video content and unobservable future events.
- A new open-set judge model evaluation metric is proposed to assess the validity of reasoning and the correctness of answers by selecting the best response from competing models based on their reasoning processes.
Introduction
Video event prediction (VEP) is a critical capability for real-world applications such as crisis early warning, where models must anticipate future occurrences from observed video sequences. While Multimodal Large Language Models (MLLMs) excel at standard video understanding, they struggle with VEP because they often lack the logical reasoning required to infer unobservable future events. Current models frequently suffer from a text-centric modality bias, where they rely on linguistic cues in answer options rather than grounding their predictions in fine-grained visual evidence. The authors leverage a new paradigm called Chain of Events (CoE) to address these limitations. By constructing temporal event chains that segment videos into historical sequences, the CoE paradigm forces models to focus on visual content and establish causal-temporal links between observed actions and future outcomes. To implement this, the authors introduce a two-stage training approach involving CoE-SFT and CoE-GRPO, which enables models to perform robust, logically grounded video event prediction.
Dataset
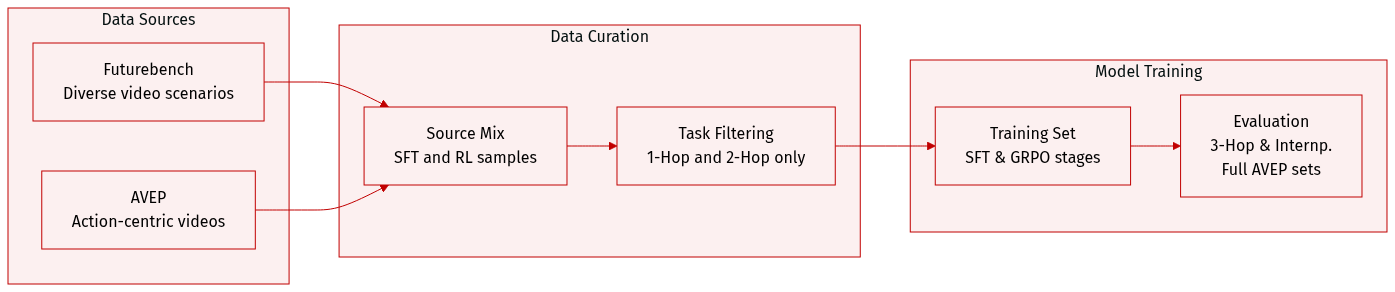
The authors utilize two primary benchmarks to evaluate and train their models for video event prediction:
-
Futurebench: This benchmark is designed to assess video event prediction across various temporal complexities. It categorizes tasks into four types: 1-Hop (standard next event prediction), 2-Hop (two consecutive events requiring short chain reasoning), 3-Hop (three consecutive events requiring deep causal reasoning), and Internp. (inferring multiple non-consecutive events using anchor events).
- Training Composition: The authors construct 2,000 CoE-SFT samples for supervised fine-tuning and utilize 2,000 reinforcement learning samples for CoE-GRPO training.
- Training Strategy: To test generalization, the training set is restricted to only 1-Hop and 2-Hop samples, meaning performance on 3-Hop and Internp. tasks serves as a measure of the model's ability to generalize.
-
AVEP (Action-centric Video Event Prediction): This benchmark focuses on fine-grained event decomposition, evaluating predictions at the argument level through verb accuracy, noun metrics (subject, object, and tool), and action metrics.
- Training and Evaluation: Since the original AVEP dataset lacks SFT data, the authors construct 5,000 CoE-SFT samples for supervised fine-tuning. Additionally, they select 5,000 samples for GRPO and CoE-GRPO training, evaluating the resulting models on the complete validation and test sets.
Method
The authors propose a Chain of Events (CoE) paradigm designed to model historical video events in a fine-grained manner, moving beyond traditional action-centric representations that often introduce unnecessary complexity for Multimodal Large Language Models (MLLMs). In this paradigm, an event E is defined as a pair E=(T,D), where T represents the start and end timestamps and D provides a textual description. A temporal event chain EC is thus a sequence of these events ordered chronologically.
The modeling process follows a structured reasoning flow. Instead of direct prediction, the model first performs fine-grained temporal modeling to construct the event chain EC=MLLMCoE(V). Subsequently, the model engages in reasoning based on both the video content and the constructed chain, denoted as R′=MLLMreason(V,Q,EC). This reasoning process incorporates logical connections between the observed video content and the predicted future events. Finally, the prediction is expressed as: P=P(E^∣V,Q,R′,EC)
To implement this, the authors employ a two-phase training approach. The first phase, CoE-SFT, utilizes a specialized reasoning dataset to train the model to connect visual content to future events through logical intermediate steps. Refer to the framework diagram for an illustration of how the CoE-SFT method is integrated within a model like Qwen2.5-VL-72B.

The second phase, CoE-GRPO, utilizes Group Relative Policy Optimization to refine the model's ability to construct event chains and perform temporal localization. In this phase, the model is encouraged to use special event tags, ⟨event⟩ and ⟨/event⟩, to explicitly mark the boundaries of each event. Each tag pair includes the timestamps and a fine-grained semantic description: E=⟨event⟩Time:tstart−tend,Des:D⟨/event⟩
As shown in the figure below, the CoE-GRPO method employs a multi-component supervision signal to guide the reinforcement learning process.
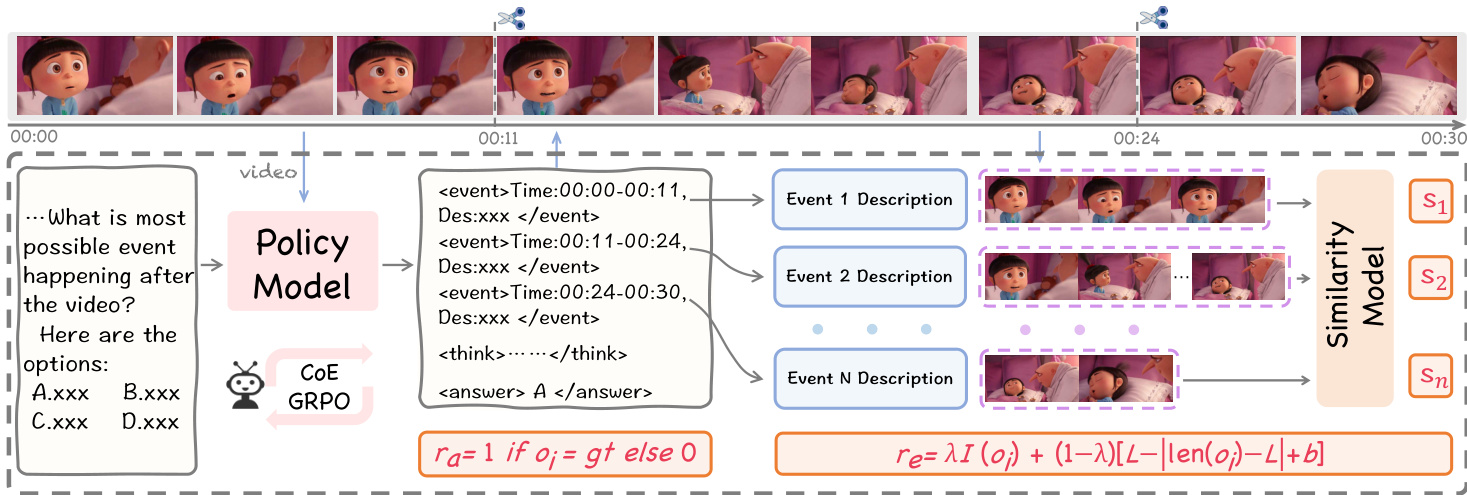
The supervision consists of three primary reward signals. First, a dense CoE reward re encourages the model to follow the reasoning paradigm and constrains the length of the event chain to prevent excessively long or short outputs. This is calculated as: re(i)=λI(oi)+(1−λ)[L−∣len(oi)−L∣+b] where I(oi) is an indicator function for correct tag usage, L is the target length, and b is a bias term.
Second, a similarity reward rs ensures alignment between the textual descriptions and the visual content. The model crops video clips based on the predicted timestamps and computes the cross-modal similarity sj between the description and the clip. The reward is the average similarity: rs=n1∑j=1nsj where sj=cos(vj,tj) represents the cosine similarity between visual and textual features.
Third, an accuracy reward ra provides verifiable signals for the final prediction. The total reward ri is a weighted sum of these components: ri=αra(i)+βre(i)+(1−α−β)rs(i)
By normalizing these rewards within a group of N sampled completions, the model calculates advantages Ai to update the policy, effectively unlocking the model's ability to perform fine-grained temporal modeling and improve visual information utilization without requiring additional data annotations.
Experiment
The evaluation assesses various open-source and commercial MLLMs on Video Event Prediction (VEP) tasks using the FutureBench and AVEP benchmarks to identify limitations in logical reasoning and visual information utilization. While standard models often rely too heavily on textual cues and lack true temporal connections to future events, the proposed CoE-GRPO and CoE-SFT methods significantly improve performance by establishing logical event chains. These methods effectively enhance the models' attention to visual tokens and enable more accurate, visually grounded reasoning for predicting future occurrences.
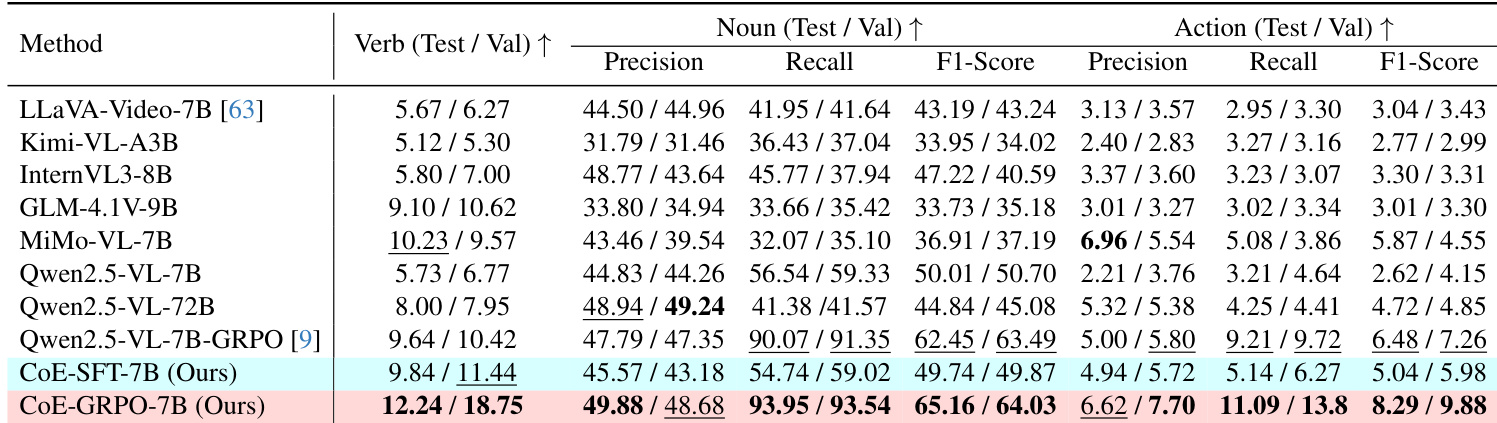
The authors evaluate various MLLMs on the AVEP benchmark, focusing on verb prediction and noun and action components. Results show that the proposed CoE-GRPO method achieves the highest performance across all tested metrics compared to existing models. CoE-GRPO demonstrates superior accuracy in verb prediction and overall event component prediction. The proposed method shows significant improvements in precision, recall, and F1-score for both nouns and actions. CoE-GRPO outperforms both the CoE-SFT approach and various open-source and commercial baseline models.
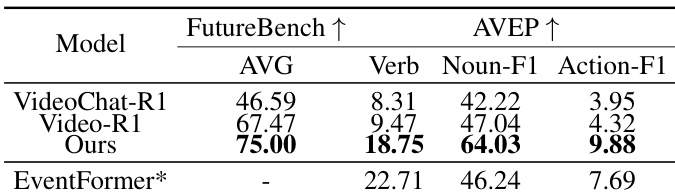
The authors compare their proposed method against existing models on the FutureBench and AVEP benchmarks. The results demonstrate that the proposed approach achieves superior performance across all evaluated metrics, including average accuracy and specific event components. The proposed method outperforms both VideoChat-R1 and Video-R1 on all measured categories. Results show significant improvements in verb prediction and action-related F1 scores compared to the baseline models. The proposed approach achieves the highest overall average score on the FutureBench benchmark.
The authors evaluate various MLLMs on the FutureBench benchmark for video event prediction. Results show that the proposed CoE-GRPO method consistently achieves the highest overall performance across different model scales compared to vanilla models and other training methods. CoE-GRPO outperforms both vanilla models and CoE-SFT across most prediction types and the overall average. The CoE-GRPO method demonstrates superior performance on both the 3B and 7B versions of the Qwen2.5-VL model. The proposed training approach shows significant improvements in prediction accuracy over standard instruction tuning and vanilla reinforcement learning methods.
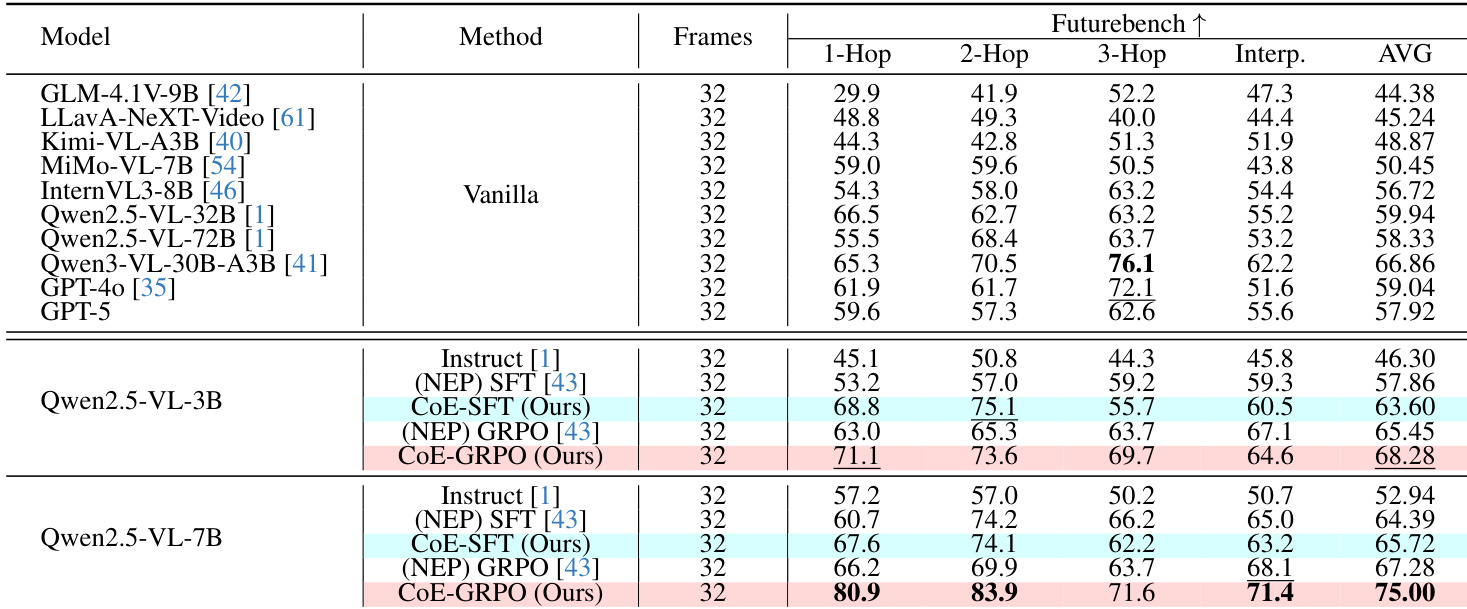
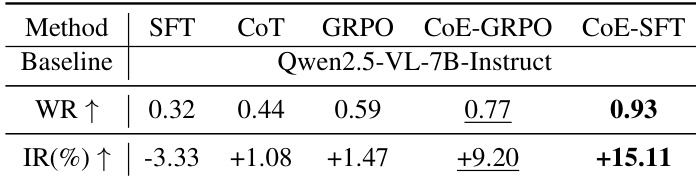
The authors compare different training methods using a judge-based evaluation to assess the reasoning quality and accuracy of model predictions. The results show that methods incorporating the CoE paradigm significantly outperform standard instruction tuning and reinforcement learning baselines. CoE-SFT achieves the highest win rate among all evaluated methods. CoE-GRPO demonstrates a substantial improvement in win rate compared to vanilla GRPO and SFT. The CoE-based approaches show a clear advantage over the Instruct baseline in terms of reasoning performance.

The authors evaluate different fine-tuning and reasoning strategies to improve the visual attention of MLLMs during video event prediction. Results show that the proposed CoE methods significantly outperform standard SFT, CoT, and GRPO approaches in both reasoning win rate and attention improvement. CoE-SFT achieves the highest win rate and the most substantial increase in visual token attention. CoE-GRPO also demonstrates superior performance compared to vanilla GRPO and SFT methods. Standard SFT actually results in a decrease in visual attention, whereas the CoE paradigm effectively enhances it.
The authors evaluate the CoE-GRPO method against various baseline models and training strategies using the AVEP and FutureBench benchmarks to assess video event prediction and reasoning quality. The results demonstrate that the CoE paradigm significantly improves accuracy in predicting event components such as nouns and verbs while enhancing visual attention compared to standard instruction tuning. Ultimately, the proposed approach consistently outperforms existing open-source and commercial models across different scales, showing superior reasoning capabilities and better alignment with visual information.