Command Palette
Search for a command to run...
daVinci-Env: 대규모 오픈 소프웨어 엔지니어링 환경 합성
daVinci-Env: 대규모 오픈 소프웨어 엔지니어링 환경 합성
초록
강력한 소프트웨어 엔지니어링 (SWE) 에이전트를 훈련시키기 위해서는 코드 편집, 테스트 실행, 해결책 정제를 위한 반복적 피드백 루프를 제공하는 대규모, 실행 가능, 검증 가능한 환경이 필수적입니다. 그러나 기존 오픈소스 데이터셋은 규모와 리포지토리 다양성 측면에서 여전히 제한적이며, 산업계 솔루션은 공개되지 않은 인프라로 인해 불투명하여 대부분의 학술 연구 그룹에게 접근을 사실상 불가능하게 만드는 장벽을 형성하고 있습니다. 이에 본고는 Python 기반 SWE 에이전트 훈련을 위한 가장 규모가 크고 완전한 투명성을 갖춘 프레임워크인 'OpenSWE'를 제시합니다. OpenSWE 는 12,800 개 이상의 리포지토리에 걸친 45,320 개의 실행 가능한 Docker 환경을 포함하며, 모든 Dockerfile, 평가 스크립트, 인프라는 재현성을 위해 완전히 오픈소스로 공개되었습니다.OpenSWE 는 64 노드 분산 클러스터에 배포된 멀티에이전트 합성 파이프라인을 통해 구축되었으며, 리포지토리 탐색, Dockerfile 구축, 평가 스크립트 생성, 반복적 테스트 분석을 자동화합니다. 규모를 넘어 본고는 각 환경의 고유한 난이도를 정량화하는 '품질 중심 필터링 파이프라인'을 제안합니다. 이를 통해 해결 불가능하거나 난이도가 충분하지 않은 인스턴스를 필터링하고, 학습 효율성을 극대화하는 인스턴스만을 선별하여 유지합니다. 환경 구축에 891,000 달러, 궤적 샘플링 및 난이도 인지형 큐레이션에 추가 576,000 달러를 투입하여 총 약 147 만 달러의 투자가 이루어졌으며, 이로 인해 약 9,000 개의 품질이 보장된 환경에서 약 13,000 개의 큐레이션된 궤적이 도출되었습니다.광범위한 실험을 통해 OpenSWE 의 유효성이 입증되었습니다. 구체적으로 OpenSWE-32B 와 OpenSWE-72B 는 SWE-bench Verified 벤치마크에서 각각 62.4% 및 66.0% 의 성능을 기록하여 Qwen2.5 시리즈 내 최고 수준 (SOTA) 을 달성했습니다. 또한, SWE 에 특화된 훈련은 사실적 회상 능력을 저하시키지 않으면서 수학 추론에서 최대 12 점, 과학 벤치마크에서 5 점에 이르는 도메인 외 (out-of-domain) 성능 향상을 가져오는 것으로 확인되었습니다.
One-sentence Summary
Researchers from SII, SJTU, and GAIR introduce OpenSWE, a transparent framework featuring 45,320 executable Docker environments for training software engineering agents. By employing a multi-agent synthesis pipeline and quality-centric filtering, this approach establishes new state-of-the-art performance while enabling significant out-of-domain reasoning improvements.
Key Contributions
- OpenSWE addresses the scarcity of large-scale, transparent training environments by releasing 45,320 executable Docker instances across 12.8k repositories, complete with open-sourced Dockerfiles, evaluation scripts, and a multi-agent synthesis pipeline.
- The framework introduces a quality-centric filtering pipeline that characterizes environment difficulty to remove unsolvable or trivial instances, resulting in 13,000 curated trajectories from 9,000 high-quality environments.
- Extensive experiments demonstrate that models trained on OpenSWE achieve state-of-the-art results of 66.0% on SWE-bench Verified and exhibit log-linear scaling without saturation, while also improving out-of-domain reasoning capabilities.
Introduction
Autonomous software engineering agents require executable environments like Docker to generate dynamic feedback through code compilation and testing, yet creating these environments at scale has historically been hindered by prohibitive computational costs and a lack of transparency. Prior open-source efforts often suffer from limited repository diversity or suffer from data quality issues such as unsolvable tasks or trivial problems that fail to provide meaningful learning signals. To address these gaps, the authors introduce OpenSWE, a fully transparent framework that synthesizes over 45,000 executable environments using a multi-agent system and implements a difficulty-aware filtering pipeline to curate high-quality training trajectories. This approach not only releases the complete infrastructure and synthesis pipeline but also demonstrates that combining massive scale with strategic curation significantly boosts agent performance on benchmarks like SWE-Bench Verified.
Dataset
OpenSWE Dataset Overview
-
Dataset Composition and Sources The authors constructed OpenSWE, the largest fully transparent framework for software engineering agent training, by collecting data from GitHub via REST and GraphQL APIs. The final dataset comprises 45,320 executable Docker environments spanning over 12,800 unique Python repositories. This infrastructure was built using a multi-agent synthesis pipeline deployed across a 64-node distributed cluster to automate repository exploration, Dockerfile construction, and test generation.
-
Key Details for Each Subset
- Source Material: The raw data consists of approximately 572,114 GitHub Pull Requests (PRs) from Python repositories.
- Filtering Rules: A four-stage pipeline ensures quality by retaining only repositories with at least five stars, filtering for Python as the primary language, requiring linked issues with descriptions, and excluding PRs where changes are confined entirely to test directories.
- Quality Assurance: A test analysis agent validates each environment to ensure tests are not bypassed by hardcoded exit codes and diagnoses root causes for failures, such as dependency conflicts or unsolvable configurations.
- Final Scale: After rigorous filtering and curation, the project yielded roughly 10,000 high-quality environments and approximately 13,000 curated trajectories.
-
Model Training and Data Usage
- Trajectory Sampling: The authors used the GLM-4.7 model to sample agent trajectories from the OpenSWE and filtered SWE-rebench datasets four times per instance using OpenHands or SWE-Agent scaffolds.
- Selection Criteria: Training data includes only trajectories that successfully solved an instance in one or two of the four attempts.
- Data Cleaning: Steps containing formatting errors or "git pull" commands were masked or removed to prevent reward hacking and ensure observation quality.
- Training Configuration: Models were trained using a modified SLiME codebase with a 128k token context window, 5 epochs, and a batch size of 128, utilizing Qwen2.5-32B and Qwen2.5-72B as base models.
-
Processing and Construction Strategies
- Distributed Synthesis: To handle execution instability and resource contention, the team employed a decoupled, fault-tolerant parallelization framework using a shared filesystem message queue and systemd services for resilient process management.
- Automated Cleanup: An automated daemon aggressively prunes unused Docker resources to prevent storage and memory exhaustion from zombie containers.
- Metadata and Evaluation: The pipeline generates reproducible Docker containers with correct dependencies and validated evaluation scripts that confirm solution correctness through dynamic test execution.
- Difficulty Curation: The authors applied a quality-centric filtering process to characterize environment difficulty, removing instances that were either unsolvable or insufficiently challenging to maximize learning efficiency.
Method
The proposed system functions as an automated environment builder designed to synthesize reproducible Docker-based evaluation environments for software engineering tasks. The architecture is distributed, utilizing a master-worker paradigm to manage the construction and validation of task instances at scale.
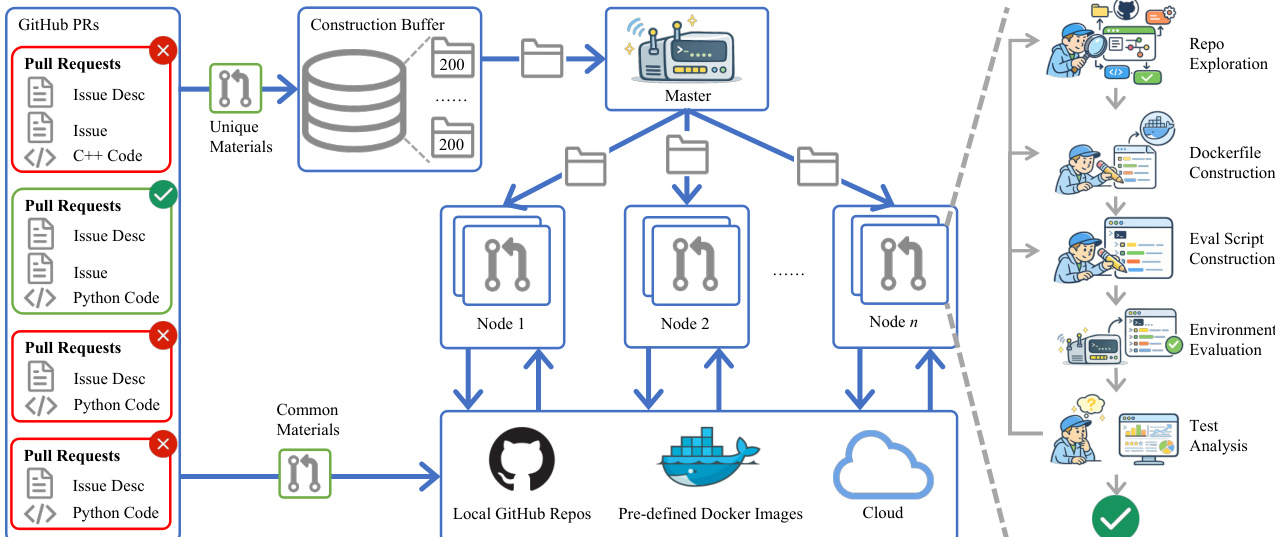
As illustrated in the framework diagram, the pipeline begins with ingesting GitHub Pull Requests and filtering them into unique and common materials. These materials are stored in a construction buffer and distributed by a Master node to multiple worker nodes. Each node executes a multi-stage agent loop comprising repository exploration, Dockerfile construction, evaluation script generation, and environment evaluation. This distributed setup allows for parallel processing of tasks while maintaining isolation through local GitHub repositories, pre-defined Docker images, and cloud resources.
The core of the system relies on a series of specialized agents that operate within an iterative feedback loop. The process initiates with a lightweight repository exploration agent. This agent bridges the gap between raw repository states and downstream environment generation. It operates through a constrained interface that allows for structural inspection, configuration file search, and extraction of setup instructions. The agent follows a cost-aware iterative policy, performing shallow, document-first inspections by default and only diving deeper when specific context is requested by downstream agents. This design minimizes redundant traversal while ensuring that critical artifacts like dependency manifests and CI workflows are identified.
Following context retrieval, the Dockerfile agent constructs the containerized environment. To address common failure modes such as network instability and redundant rebuilds, the system employs a pre-built suite of base images covering various Python versions. This strategy eliminates runtime dependency installation timeouts. Furthermore, the agent utilizes a local bare repository cache to inject codebases via COPY commands rather than cloning at build time, which removes external network dependencies and improves reproducibility. The agent is also guided by layer-aware prompting to place stable base layers early in the Dockerfile, allowing for efficient caching when dependency specifications are revised in subsequent iterations.
Concurrently, the evaluation script agent generates bash scripts to verify repair correctness. The central challenge here is precise test targeting, ensuring only relevant test cases are executed. The agent synthesizes structured bash scripts from scratch, incorporating specific test files and embedding a dedicated exit code marker to signal repair success or failure. This script is template-based to support stable iteration, separating patch injection from test command logic.
Finally, the environment evaluation module performs rule-based validation. For each iteration, the Docker image is built and the evaluation script is executed under two conditions: first with a test-only patch to verify failures on the unpatched codebase, and then with the full fix patch to verify resolution. To support this at scale, containers are bound to dedicated CPU cores and memory limits to prevent resource contention. Images are retained until the Dockerfile changes, significantly speeding up the common case where only the evaluation script is revised. If validation fails, the test analysis agent inspects the logs and provides targeted feedback to the Dockerfile or evaluation script agents to refine their outputs in the next iteration.
Experiment
- Main performance evaluation on SWE-Bench Verified validates that OpenSWE achieves state-of-the-art results at both 32B and 72B scales, demonstrating that high-quality environment data can compensate for the lack of domain-specific pretraining.
- Scaling analysis confirms a robust log-linear improvement trend where larger models benefit more from increased training data, with no performance saturation observed within the current budget.
- Environment source comparison shows that OpenSWE's synthesized environments provide a substantially stronger training signal than existing benchmarks, while mixing data sources offers complementary benefits specifically for larger models.
- General capability assessment reveals that SWE-focused training significantly enhances code generation and mathematical reasoning through improved multi-step planning, while leaving factual recall largely unaffected.