Command Palette
Search for a command to run...
MM-CondChain: 시각적으로 기반을 둔 심층 구성적 추론을 위한 프로그래밍적으로 검증된 벤치마크
MM-CondChain: 시각적으로 기반을 둔 심층 구성적 추론을 위한 프로그래밍적으로 검증된 벤치마크
Haozhan Shen Shilin Yan Hongwei Xue Shuaiqi Lu Xiaojun Tang Guannan Zhang Tiancheng Zhao Jianwei Yin
초록
다중 모달 대규모 언어 모델 (MLLMs) 은 GUI 탐색과 같은 시각적 워크플로우 수행에 점차 활용되고 있으며, 이러한 워크플로우에서는 다음 단계가 검증된 시각적 구성 조건 (예: "권한 대화 상자가 나타나고 인터페이스 색상이 녹색인 경우 '허용'을 클릭") 에 의존하며, 과정이 분기되거나 조기 종료될 수 있습니다. 그러나 이러한 능력은 아직 충분히 평가되지 않았습니다. 기존 벤치마크는 얕은 수준의 구성이나 독립적 제약 조건에 초점을 맞추고 있을 뿐, 심층적으로 연결된 구성적 조건부 (deeply chained compositional conditionals) 를 다루지 못합니다. 본 논문에서는 시각적으로 근거된 심층 구성 추론을 평가하기 위한 벤치마크인 MM-CondChain 을 제시합니다. 각 벤치마크 인스턴스는 다층 추론 체인으로 구성되며, 각 층은 시각적 증거에 기반한 비자명한 구성 조건을 포함하고 있으며, 여러 객체, 속성, 또는 관계로부터 구성됩니다. 정확히 답하기 위해서는 MLLM 이 이미지를 세밀하게 지각하고, 각 단계에서 여러 시각적 요소에 대해 추론하며, 그 결과로 도출된 실행 경로를 따라 최종 결과에 도달해야 합니다. 이러한 워크플로우 스타일의 데이터를 확장 가능하게 구축하기 위해, 우리는 에이전트 기반 합성 파이프라인을 제안합니다. Planner 가 구성 조건을 층별로 생성하도록 조정하고, 검증 가능한 프로그래밍 중간 표현 (VPIR: Verifiable Programmatic Intermediate Representation) 을 통해 각 층의 조건이 기계적으로 검증되도록 보장합니다. 이후 Composer 는 이러한 검증된 층들을 조립하여 완전한 지시문을 생성합니다. 본 파이프라인을 활용하여 우리는 자연 이미지, 데이터 차트, GUI 트래젝토리라는 세 가지 시각적 도메인에 걸쳐 벤치마크를 구축하였습니다. 다양한 MLLM 을 대상으로 한 실험 결과, 가장 강력한 모델조차도 Path F1 점수가 53.33 에 불과하며, 하드 네거티브 샘플에서 급격한 성능 저하가 발생하고, 깊이나 술어 복잡도가 증가함에 따라 성능이 더욱 하락함을 확인하였습니다. 이는 심층 구성 추론이 여전히 근본적인 과제임을 입증합니다.
One-sentence Summary
Researchers from Alibaba Group and Zhejiang University introduce MM-CondChain, a benchmark for visually grounded deep compositional reasoning that employs a VPIR-based agentic pipeline to generate mechanically verifiable, multi-layer conditional chains, revealing that even state-of-the-art multimodal models struggle with complex visual workflows requiring precise step-by-step verification.
Key Contributions
- Existing benchmarks fail to evaluate deep compositional reasoning because they focus on shallow single-layer compositions or independent constraints rather than multi-layer visual workflows where each step determines the execution path.
- The authors introduce MM-CondChain, a benchmark featuring nested conditional chains grounded in visual evidence, constructed via an agentic synthesis pipeline that uses a Verifiable Programmatic Intermediate Representation to ensure mechanical verifiability.
- Experiments across natural images, data charts, and GUI trajectories reveal that even the strongest multimodal models achieve only 53.33 Path F1, demonstrating significant performance drops as reasoning depth and predicate complexity increase.
Introduction
Multimodal Large Language Models are increasingly deployed in complex visual workflows like GUI navigation, where subsequent actions depend on verifying chained visual conditions. However, existing benchmarks fail to evaluate this capability because they focus on shallow, single-layer compositions or independent constraints rather than deep, multi-step reasoning paths that branch or terminate based on visual evidence. To address this gap, the authors introduce MM-CondChain, a benchmark featuring multi-layer control flow with mechanically verified hard negatives. They achieve scalable and reliable data construction through an agentic synthesis pipeline that uses a Verifiable Programmatic Intermediate Representation to decouple logical condition generation from natural language rendering.
Dataset
-
Dataset Composition and Sources: The authors construct MM-CondChain from three distinct visual domains using publicly available datasets. The Natural domain includes 398 images from SAM and GQA, the Chart domain features 200 chart images from ChartQA, and the GUI domain comprises 377 interaction trajectories (totaling 3,421 screenshots) sourced from AITZ.
-
Key Details for Each Subset:
- Natural: Focuses on object attributes and spatial relations.
- Chart: Concentrates on numerical and structural statistics across bar, line, and pie charts.
- GUI: Emphasizes action, state, and trajectory-level metadata with fine-grained reasoning annotations.
- Total Volume: The benchmark contains 975 evaluation samples, where each sample consists of a paired True-path and False-path instance.
-
Data Usage and Processing:
- Synthesis Pipeline: The authors employ Gemini-3-Pro to instantiate all agents in the synthesis pipeline, including the Planner, Verifier, Fact Extractor, and Translator.
- Subject De-leakage: An MLLM-based rewriter modifies subject descriptions to remove condition-revealing attributes while ensuring the subject remains uniquely referential to the target object.
- Paired-Path Instantiation: Each control-flow skeleton generates two nearly isomorphic instances. The True-path follows all conditions to a terminal layer, while the False-path swaps a single condition at a randomly sampled divergence layer to trigger early termination.
- Instruction Compilation: The system merges subjects and conditions into fluent natural-language if-clauses to create nested instructions that serve as hard negatives.
-
Evaluation Strategy:
- Metrics: Performance is measured using True-path Accuracy, False-path Accuracy, and Path F1 (the harmonic mean of the two), with an overall score calculated as the average Path F1 across domains.
- Setup: Models are evaluated in a zero-shot setting using default API parameters, with answers extracted from multiple-choice outputs based on specific formatting rules.
Method
The authors propose a VPIR-based agentic benchmark construction pipeline that decouples logical construction from language rendering to address logical inconsistencies in multi-layer compositional reasoning. The core framework accepts multimodal inputs, including natural images, chart images with metadata, and GUI trajectories with annotations. Refer to the framework diagram for the overall architecture.
The pipeline operates through an iterative, multi-layer reasoning chain coordinated by a Planner. At each layer t, the Planner selects a relational strategy rt to determine how the reasoning chain evolves, choosing between actions such as EXTEND, FINISH, or ROLLBACK. This control mechanism ensures that the chain depth remains within a target interval while maintaining coherence.
Once a layer is initiated, the system executes a four-stage synthesis workflow. First, a Fact Extractor grounds the generation in visual evidence by selecting a subject St and producing structured facts Ft as a typed key-value mapping. This structured representation prevents hallucination and defines a programmatic namespace. Second, the VPIR Generator synthesizes a Verifiable Programmatic Intermediate Representation, consisting of a true-logic predicate pt and a counterfactual false-logic p~t. These predicates are executable Python-like code evaluated in a sandboxed environment to ensure mechanical verifiability.
As shown in the figure below:
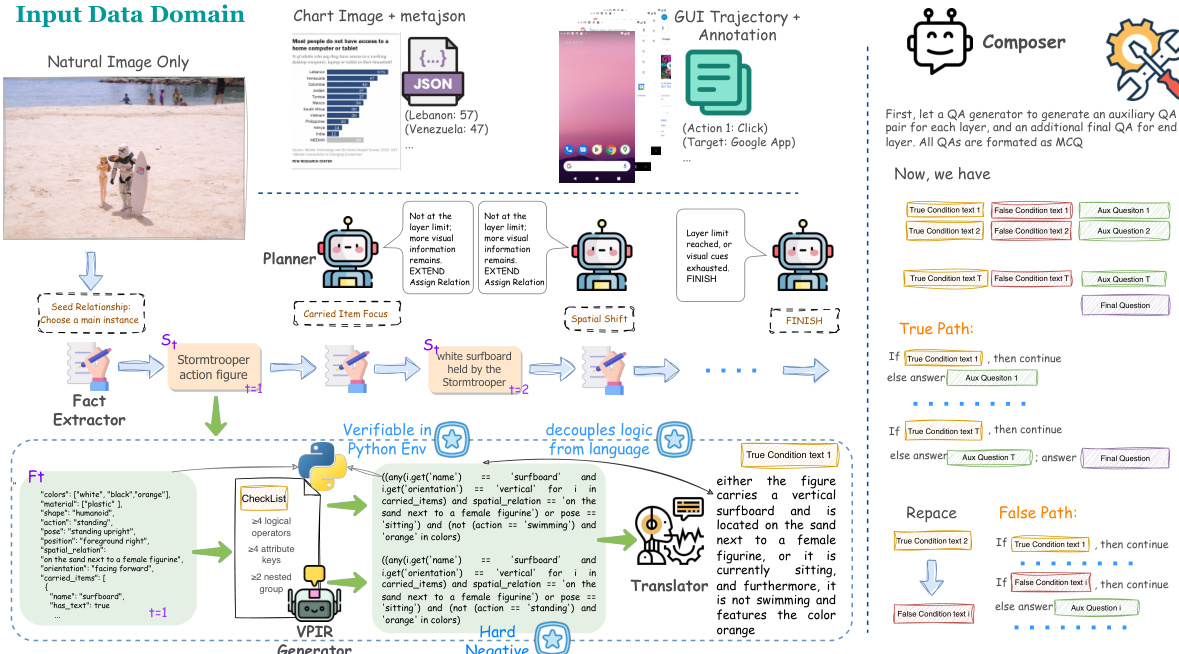
Third, a Translator renders the verified executable logic into natural language condition texts ct and c~t. This step ensures that truth values are anchored in code execution rather than linguistic generation. Finally, a Composer compiles the verified chain into paired benchmark instances. It constructs a True-path where all conditions hold and a False-path where a single condition is replaced by a minimally perturbed counterfactual, creating hard negatives that require precise visual grounding and deep compositional reasoning.
Experiment
- Main evaluation on MM-CondChain reveals that current multimodal large language models struggle with visually grounded deep compositional reasoning, with even top performers achieving only slightly above 50% average Path F1.
- Experiments comparing true versus false paths show a significant bias where models over-assume conditions hold, leading to high accuracy on valid paths but poor performance on invalid ones, which poses risks in real-world workflows.
- Domain analysis indicates that GUI tasks are the most challenging due to the need for multi-frame trajectory and state transition reasoning, whereas chart tasks are comparatively easier as they often reduce to deterministic numerical comparisons.
- Ablation studies on chain depth demonstrate that performance degrades consistently as the number of sequential verification layers increases, confirming that errors compound across layers rather than remaining isolated.
- Tests on predicate complexity reveal that increasing the logical operators and nesting within a single condition causes substantial performance drops, highlighting that models struggle with both sequential and intra-layer compositional reasoning.
- Overall, the findings establish that chain depth and predicate complexity are two orthogonal axes of difficulty that jointly define the limits of current models, making the benchmark a valuable diagnostic tool for identifying specific reasoning failures.