Command Palette
Search for a command to run...
DreamVideo-Omni: 잠재적 정체성 강화 학습을 통한 오미-모션 제어 다중 대상 비디오 커스터마이징
DreamVideo-Omni: 잠재적 정체성 강화 학습을 통한 오미-모션 제어 다중 대상 비디오 커스터마이징
초록
대규모 확산 모델이 비디오 합성 분야에 혁명을 일으켰음에도 불구하고, 다중 대상의 정체성 (identity) 과 다중 세분화 (multi-granularity) 움직임을 동시에 정밀하게 제어하는 것은 여전히 주요 과제로 남아 있습니다. 최근 이러한 격차를 해소하려는 시도들은 제한된 움직임 세분화, 제어의 모호성, 그리고 정체성 저하 등의 문제로 인해 정체성 보존 및 움직임 제어 측면에서 최적의 성능을 달성하지 못하고 있습니다. 본 논문에서는 점진적 2 단계 학습 패러다임을 통해 조화로운 다중 대상 커스터마이징과 범용 (omni) 움직임 제어를 가능하게 하는 통합 프레임워크인 'DreamVideo-Omni'를 제시합니다.첫 번째 단계에서는 대상의 외관, 전역 움직임, 국부적 역학, 그리고 카메라 이동 등을 포괄하는 포괄적인 제어 신호들을 통합하여 공동 학습을 수행합니다. 견고하고 정밀한 제어 가능성을 확보하기 위해 이질적인 입력들을 조정하기 위한 '조건 인식 3D 회전 위치 임베딩 (condition-aware 3D rotary positional embedding)'을 도입하고, 전역 움직임 가이드를 강화하기 위한 '계층적 움직임 주입 전략 (hierarchical motion injection strategy)'을 적용합니다. 또한, 다중 대상 간의 모호성을 해결하기 위해 '그룹 및 역할 임베딩 (group and role embeddings)'을 도입하여 움직임 신호를 특정 정체성에 명시적으로 고정함으로써, 복잡한 장면을 독립적으로 제어 가능한 인스턴스로 효과적으로 분리해냅니다.두 번째 단계에서는 정체성 저하를 완화하기 위해 사전 학습된 비디오 확산 백본 (backbone) 을 기반으로 잠재 공간의 정체성 보상 모델을 학습시키는 '잠재 정체성 보상 피드백 학습 패러다임'을 설계했습니다. 이를 통해 잠재 공간 내에서 움직임에 민감한 정체성 보상을 제공하며, 인간의 선호도에 부합하는 정체성 보존을 최우선으로 합니다. 저희가 직접 구축한 대규모 데이터셋과 다중 대상 및 범용 움직임 제어 평가를 위한 포괄적인 'DreamOmni 벤치마크 (DreamOmni Bench)'를 기반으로 한 실험 결과, DreamVideo-Omni 는 정밀한 제어 가능성을 갖춘 고품질 비디오 생성에서 우수한 성능을 입증하였습니다.
One-sentence Summary
Researchers from Alibaba and HKUST propose DreamVideo-Omni, a unified framework that achieves precise multi-subject video customization with omni-motion control by introducing group embeddings to resolve ambiguity and a latent identity reward model to preserve fidelity during complex movements.
Key Contributions
- DreamVideo-Omni addresses the critical challenge of simultaneously preserving multiple subject identities while enabling precise, multi-granularity motion control, a task where existing methods suffer from limited signal types, control ambiguity, and identity degradation.
- The framework introduces a progressive two-stage training paradigm featuring condition-aware 3D rotary positional embeddings and group-role embeddings to explicitly anchor heterogeneous motion signals to specific subjects, alongside a latent identity reward model that aligns generation with human preferences to prevent identity loss.
- Validated on a curated large-scale dataset and the comprehensive DreamOmni Bench, the method demonstrates superior performance in generating high-quality videos with harmonious multi-subject customization and robust omni-motion control compared to prior approaches.
Introduction
Video diffusion models have transformed synthesis, yet real-world applications demand simultaneous preservation of multiple subject identities and precise control over global motion, local dynamics, and camera movement. Prior approaches struggle with this dual objective because they often rely on single motion signals, fail to explicitly bind motion to specific subjects causing ambiguity, and suffer from identity degradation when reconciling static appearance with dynamic movement. The authors leverage a unified framework called DreamVideo-Omni that employs a progressive two-stage training paradigm to resolve these issues. They introduce architectural innovations like group and role embeddings to disambiguate multi-subject signals and a latent identity reward feedback learning system that aligns optimization with human preferences to maintain identity fidelity during complex motion.
Dataset
-
Dataset Composition and Sources: The authors construct a large-scale, densely annotated video dataset specifically for the supervised fine-tuning (SFT) stage of DreamVideo-Omni. This corpus is designed to support multi-subject customization and comprehensive motion control, distinguishing it from previous datasets that often lack these combined capabilities.
-
Key Details for Each Subset:
- Training Dataset: An automated pipeline filters raw video data to ensure high quality and significant temporal dynamics. It includes videos with precise annotations for global bounding boxes, subject masks, and motion trajectories.
- DreamOmni Bench: A separate evaluation set comprising 1,027 high-quality real-world videos sourced independently from the training data to ensure zero-shot assessment. This benchmark is split into 436 single-subject and 591 multi-subject samples covering humans, animals, general objects, and faces.
-
Data Usage and Processing Pipeline:
- Motion Filtering: The authors use RAFT to estimate dense optical flow and discard videos with low motion magnitude to focus on meaningful dynamics.
- Subject Discovery: Semantic tags are extracted via RAM++, refined by Qwen3 Max to identify significant moving subjects, and then used by Qwen3-VL to generate detailed captions.
- Spatiotemporal Annotation: Grounding DINO detects bounding boxes, which feed into SAM 2 to create precise binary segmentation masks. CoTracker3 performs dense point tracking, classifying trajectories as either object or camera motion based on the masks.
- Reference Image Construction: To prevent trivial copy-paste solutions and enable zero-shot customization, reference images are sampled from frames temporally disjoint from the training clip, isolated using segmentation masks, and subjected to extensive data augmentation.
-
Benchmark Construction and Filtering: For the DreamOmni Bench, the authors apply manual filtering to retain high-resolution videos with meaningful motion while explicitly excluding static content, text overlays, and watermarks. The resulting dataset provides a unified evaluation framework for identity preservation and motion control precision using metrics for bounding box and trajectory accuracy.
Method
The authors propose DreamVideo-Omni, a unified video diffusion transformer framework designed for harmonious multi-subject customization with omni-motion control. The system follows a progressive two-stage training paradigm to resolve the conflict between identity preservation and complex motion control. Refer to the framework diagram for the overall architecture, which illustrates the transition from supervised fine-tuning to reinforcement learning.
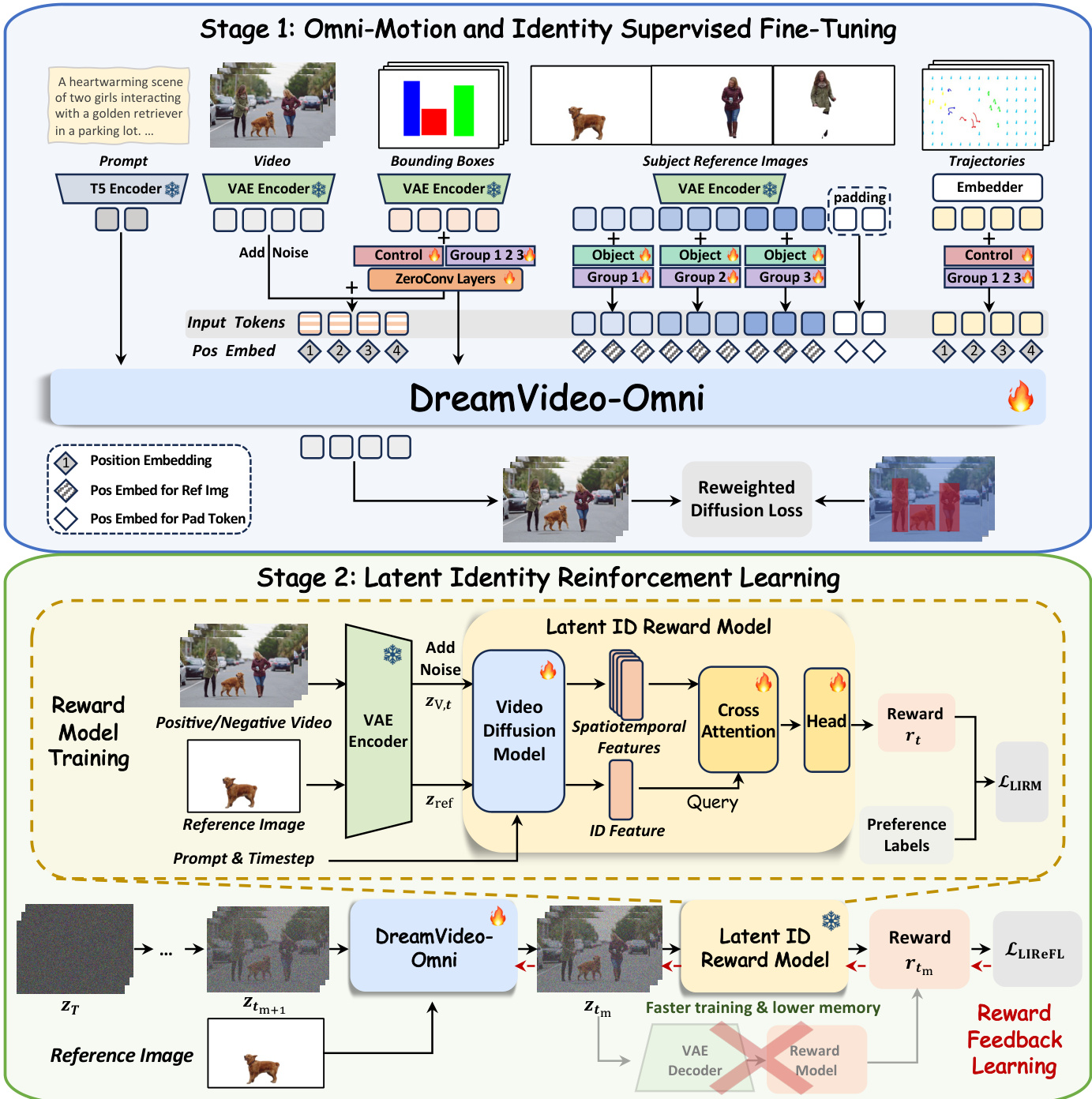
In the first stage, Omni-Motion and Identity Supervised Fine-Tuning, the model is trained on a comprehensive set of tasks including single- and multi-subject customization, global and local object motion control, and camera movement. To enable precise composition, the authors craft four compact conditioning signals. The data preparation for these signals involves a rigorous automated pipeline.
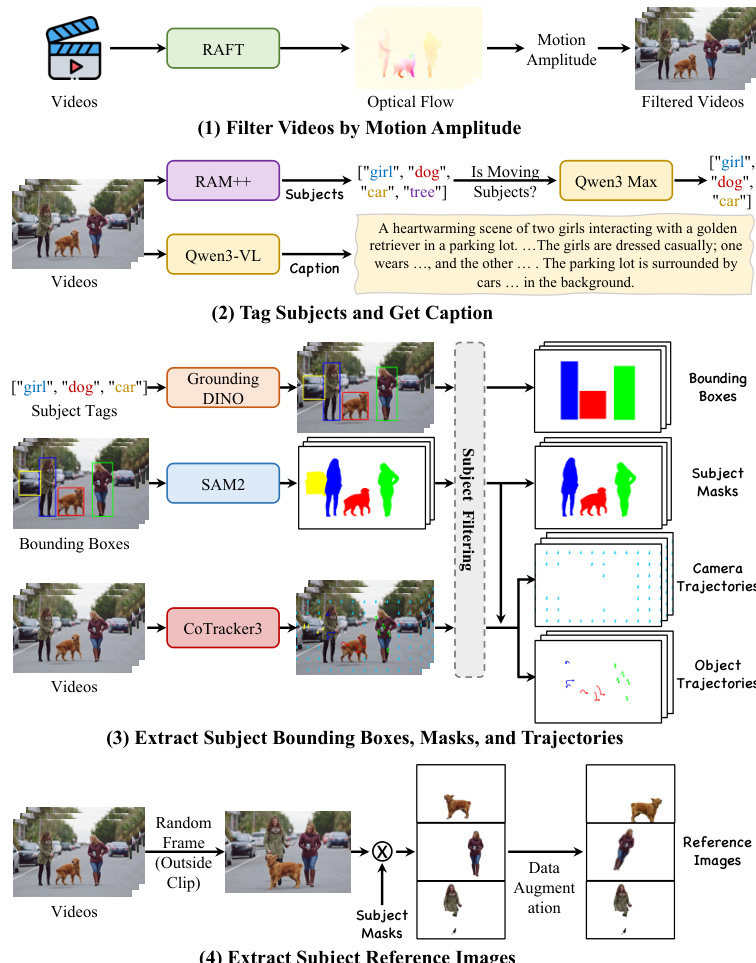
This pipeline filters videos by motion amplitude, tags subjects, and extracts bounding boxes, masks, and trajectories. The resulting comprehensive annotations provide detailed captions, bounding boxes, trajectories, and subject masks for training.

The model architecture employs a condition-aware 3D Rotary Positional Embedding (RoPE) to process heterogeneous inputs. Video frame tokens receive sequential temporal indices, while reference image tokens are assigned a shared distinct time index to decouple them from the video sequence. Trajectory tokens inherit the video frame indices to ensure spatiotemporal alignment. To mitigate control ambiguity, the authors introduce group and role embeddings. A unique group embedding binds a reference subject to its corresponding bounding box and trajectories, while role embeddings distinguish between visual appearance assets and motion control guidance.
For conditioning signal injection, the authors implement a hierarchical motion injection strategy for bounding boxes. The bounding box latents are added to both the noisy input latents and the output of each DiT block via learnable, layer-specific zero-convolutions, formulated as:
h0=zt+Zin(zbox),hl+1=Blockl(hl)+Zl(zbox).where zt and zbox are the input noisy video latents and bounding box latents, respectively. Local object motion and camera movement are controlled via point-wise trajectories using a hybrid sampling strategy that alternates between random grid sampling and object-aware sampling. The training objective utilizes a reweighted diffusion loss that amplifies contributions within bounding boxes to enhance subject learning:
Lsft=Ez,ϵ,C,t[(1+λ1M)⋅∣∣ϵ−ϵθ(zt,C,t)∣∣22],where C represents the comprehensive conditioning set and M denotes the binary bounding box masks.
The second stage, Latent Identity Reinforcement Learning, addresses the insufficiency of low-level reconstruction losses for preserving fine-grained appearance details. The authors introduce a Latent Identity Reward Model (LIRM) that operates directly in latent space to mitigate computational overhead. The LIRM architecture comprises a video diffusion model backbone, an identity cross-attention layer, and a reward prediction head. The identity features from the reference image serve as the query Q to attend to the video's spatiotemporal features acting as key K and value V:
hattn=Attention(Q,K,V)=Softmax(dQK⊤)V,The resulting representation is passed through a lightweight MLP head to predict the scalar reward rt:
rt=H(hattn+Q).Leveraging this model, the authors perform Latent Identity Reward Feedback Learning (LIReFL). This approach bypasses the expensive VAE decoder by performing reward feedback directly on intermediate noisy latents. The model executes a single gradient-enabled denoising step to derive the predicted latent ztm, which is evaluated by the frozen LIRM. The reinforcement loss is formulated to maximize the expected identity fidelity:
LLIReFL=−Etm,cixt,zref[rtm].To prevent reward hacking, the final training objective combines the supervised SFT objective with the reward feedback loss:
L=Lsft+λ2LLIReFL,where λ2 controls the strength of the reward feedback. This balanced strategy ensures the model aligns with human identity preferences while preserving precise motion control.
Experiment
- Joint subject customization and motion control experiments validate that the proposed framework successfully balances high-fidelity identity preservation with precise trajectory adherence, outperforming baselines that struggle with identity degradation or motion drift.
- Pure subject customization evaluations confirm the method's ability to prevent identity mixing and leakage in multi-subject scenarios while maintaining superior text alignment and facial details compared to existing approaches.
- Motion control benchmarks demonstrate that the model achieves significantly higher spatial layout accuracy and trajectory precision than larger parameter models, proving its efficiency and robustness in complex movement tasks.
- Emergent capability tests reveal that the unified training paradigm enables zero-shot Image-to-Video generation and first-frame-conditioned trajectory control without requiring task-specific fine-tuning.
- Ablation studies establish that condition-aware 3D RoPE, group and role embeddings, and hierarchical bounding box injection are critical components, while the latent identity reinforcement learning stage is essential for refining identity details and avoiding reward hacking.