Command Palette
Search for a command to run...
IndexCache: 교차 계층 인덱스 재사용을 통한 희소 어텐션 가속화
IndexCache: 교차 계층 인덱스 재사용을 통한 희소 어텐션 가속화
Yushi Bai Qian Dong Ting Jiang Xin Lv Zhengxiao Du Aohan Zeng Jie Tang Juanzi Li
초록
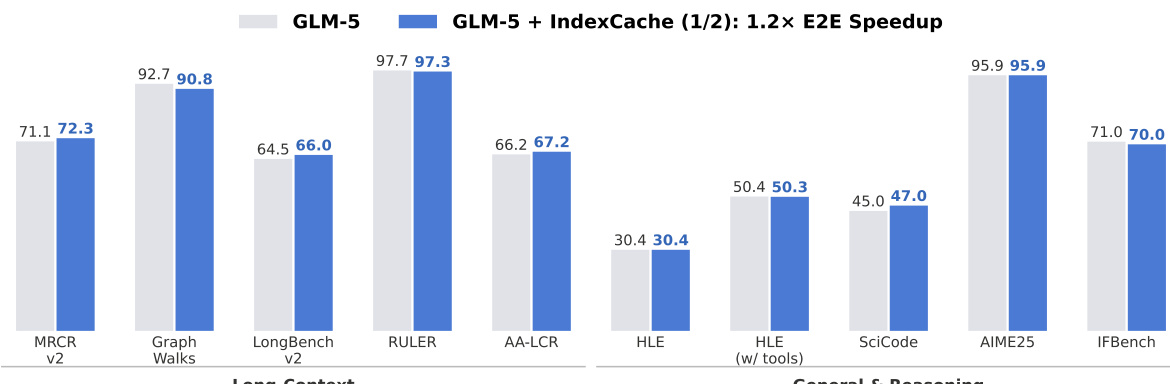
장문맥 에이전트 워크플로는 대규모 언어 모델의 핵심 사용 사례로 부상했으며, 이에 따라 추론 속도와 서비스 비용 모두를 고려할 때 어텐션 효율성이 매우 중요해졌습니다. 희소 어텐션 (Sparse Attention) 은 이러한 과제를 효과적으로 해결하며, DeepSeek Sparse Attention(DSA) 은 이를 구현한 대표적인 생산급 솔루션입니다. DSA 는 경량화된 라이트닝 인덱서를 통해 각 쿼리에 대해 가장 관련성이 높은 토큰 상위 k 개를 선별함으로써 핵심 어텐션 연산의 복잡도를 O(L2)에서 O(Lk)로 낮춥니다. 그러나 인덱서 자체는 여전히 O(L2)의 복잡도를 가지며, 연속된 레이어 간에 생성된 상위 k 개 선택 결과가 매우 유사함에도 불구하고 모든 레이어에서 독립적으로 실행되어야 합니다.본 논문에서는 이러한 레이어 간 중복성을 활용하는 IndexCache 를 제안합니다. IndexCache 는 레이어를 자체 인덱서를 실행하는 소수의 풀 (Full) 레이어와, 가장 가까운 풀 레이어의 상위 k 개 인덱스를 재사용하는 다수의 공유 (Shared) 레이어로 분할하여 구성합니다. 또한 이 구성을 결정하고 최적화하기 위한 두 가지 상보적 접근법을 제시합니다. 첫째, 훈련이 필요 없는 IndexCache 는 보정 데이터셋에서 언어 모델링 손실을 직접 최소화하는 그리드 탐색 알고리즘을 적용하여 인덱서를 유지할 레이어를 선정하며, 가중치 업데이트가 전혀 필요하지 않습니다. 둘째, 훈련을 고려한 IndexCache 는 각 유지된 인덱서가 담당하는 모든 레이어의 평균 어텐션 분포를 대상으로 하는 다중 레이어 증류 손실 함수를 도입함으로써, 단순한 인터리브 패턴을 사용하더라도 풀 인덱서 수준의 정확도를 달성할 수 있도록 합니다.30B 파라미터 규모의 DSA 모델을 대상으로 한 실험 결과, IndexCache 는 품질 저하를 거의 일으키지 않으면서 인덱서 연산의 75% 를 제거할 수 있었으며, 표준 DSA 대비 프리필 (prefill) 속도를 최대 1.82 배, 디코드 (decode) 속도를 최대 1.48 배 향상시켰습니다. 이러한 긍정적 결과는 대규모 생산 환경의 GLM-5 모델에 대한 예비 실험을 통해 추가적으로 입증되었습니다 (그림 1).
One-sentence Summary
Researchers from Tsinghua University and Z.ai introduce IndexCache, a technique that optimizes DeepSeek Sparse Attention by exploiting cross-layer redundancy to share token indices. This approach eliminates up to 75% of indexer computations in long-context workflows, delivering significant inference speedups without requiring model retraining or degrading output quality.
Key Contributions
- Long-context agentic workflows rely on DeepSeek Sparse Attention to reduce core attention complexity, yet the required lightning indexer still incurs quadratic O(L2) cost at every layer, creating a significant bottleneck for inference speed and serving costs.
- IndexCache addresses this redundancy by partitioning layers into Full layers that compute indices and Shared layers that reuse the nearest Full layer's top-k selections, utilizing either a training-free greedy search or a training-aware multi-layer distillation loss to optimize the configuration.
- Experiments on a 30B DSA model demonstrate that IndexCache removes 75% of indexer computations with negligible quality degradation, achieving up to 1.82x prefetch and 1.48x decode speedups while maintaining performance across nine long-context and reasoning benchmarks.
Introduction
Large language models face a critical bottleneck in long-context inference due to the quadratic complexity of self-attention, which sparse mechanisms like DeepSeek Sparse Attention (DSA) address by selecting only the most relevant tokens. While DSA reduces core attention costs, its reliance on a lightweight indexer at every layer still incurs quadratic overhead that dominates latency during the prefill stage. The authors leverage the observation that token selection patterns remain highly stable across consecutive layers to introduce IndexCache, a method that eliminates up to 75% of indexer computations by reusing indices from a small subset of retained layers. They propose both a training-free approach using greedy layer selection and a training-aware strategy with multi-layer distillation to maintain model quality while achieving significant speedups in long-context scenarios.
Method
The authors leverage the observation that sparse attention indexers exhibit significant redundancy across consecutive layers to reduce computational overhead. In standard DeepSeek Sparse Attention, a lightweight lightning indexer scores all preceding tokens at every layer to select the top-k positions. While this reduces core attention complexity from O(L2) to O(Lk), the indexer itself retains O(L2) complexity. IndexCache addresses this by partitioning the N transformer layers into two categories: Full layers and Shared layers. Full layers retain their indexers to compute fresh top-k sets, while Shared layers skip the indexer forward pass and reuse the index set from the nearest preceding Full layer. This design allows the system to eliminate a large fraction of the total indexer cost with minimal architectural changes.
To determine the optimal configuration of Full and Shared layers without retraining, the authors propose a training-free greedy search algorithm. The process begins with all layers designated as Full. The algorithm iteratively evaluates the language modeling loss on a calibration set for each candidate layer conversion. At each step, the layer whose conversion to Shared status results in the lowest loss increase is selected. This data-driven approach identifies which indexers are expendable based on their intrinsic importance to the model's performance rather than relying on uniform interleaving patterns.
For models trained from scratch or via continued pre-training, a training-aware approach further optimizes the indexer parameters for cross-layer sharing. Standard training distills the indexer against the attention distribution of its own layer. IndexCache generalizes this by introducing a multi-layer distillation loss. This objective encourages the retained indexer to predict a top-k set that is jointly useful for itself and all subsequent Shared layers it serves. The loss function is defined as:
LmultiI=j=0∑mm+11t∑DKL(pt(ℓ+j)qt(ℓ)),where pt(ℓ+j) represents the aggregated attention distribution at layer ℓ+j and qt(ℓ) is the indexer's output distribution. Theoretical analysis shows that this multi-layer loss produces gradients equivalent to distilling against the averaged attention distribution of all served layers. This ensures the indexer learns a consensus top-k selection that covers important tokens across the entire group of layers.
Experimental evaluations on a 30B parameter model demonstrate the efficiency gains achieved by removing indexer computations. The method successfully eliminates up to 75% of indexer costs while maintaining comparable quality. Performance metrics regarding prefill time and decode throughput are summarized below.
The results confirm that IndexCache delivers significant speedups in both prefill and decode phases without degrading model capabilities.
Experiment
- End-to-end inference experiments demonstrate that IndexCache significantly accelerates both prefill latency and decode throughput for long-context scenarios, with speedups increasing as context length grows, while maintaining comparable performance on general reasoning tasks.
- Training-free IndexCache evaluations reveal that greedy-searched sharing patterns are essential for preserving long-context accuracy at aggressive retention ratios, whereas uniform interleaving causes substantial degradation; however, general reasoning capabilities remain robust across most configurations.
- Training-aware IndexCache results show that retraining the model to adapt to index sharing eliminates the sensitivity to specific patterns, allowing simple uniform interleaving to match full-indexer performance and confirming the effectiveness of cross-layer distillation.
- Scaling experiments on a 744B-parameter model validate that the trends observed in smaller models hold true, with searched patterns providing stable quality recovery even at high sparsity levels.
- Analysis of cross-layer index overlap confirms high redundancy between adjacent layers but reveals that local similarity metrics fail to identify optimal sharing patterns, necessitating end-to-end loss-based search to prevent cascading errors in deep networks.