Command Palette
Search for a command to run...
생각을 통해 회상하기: LLMs 에서 추론이 매개변수 지식을 해금하는 방식
생각을 통해 회상하기: LLMs 에서 추론이 매개변수 지식을 해금하는 방식
Zorik Gekhman Roee Aharoni Eran Ofek Mor Geva Roi Reichart Jonathan Herzig
초록
대규모 언어 모델(LLM)에서의 추론은 수학, 코드 생성, 다중 홉(multi-hop) 사실 기반 질문과 같은 영역에서 자연스러운 역할을 수행해 왔으나, 단순한 단일 홉(simple single-hop) 사실 기반 질문에 대한 그 효과는 여전히 불분명합니다. 이러한 질문들은 단계별 논리적 분해가 필요하지 않으므로, 추론의 유용성은 직관적으로 이해하기 어렵습니다. 그럼에도 불구하고, 우리는 추론 기능을 활성화함으로써 모델의 매개변수적 지식 회상(parametric knowledge recall) 능력의 경계를 크게 확장할 수 있으며, 그렇지 않으면 사실상 도달 불가능했던 정답을 도출할 수 있음을 발견했습니다. 복잡한 추론 단계가 존재하지 않는 상황에서 왜 추론이 매개변수적 지식 회상을 돕는 것일까요? 이에 대한 답변을 찾기 위해 우리는 가설 기반의 통제 실험 일련을 설계하고 두 가지 핵심 작동 기제를 규명했습니다: (1) 계산적 버퍼 효과(computational buffer effect)로, 모델이 생성된 추론 토큰을 그 의미적 내용과 무관하게 잠재적 계산(latent computation) 수행을 위한 버퍼로 활용하는 현상; (2) 사실적 프라이밍(factual priming)으로, 주제와 관련된 사실을 생성함으로써 정답 회상을 촉진하는 의미적 다리 역할을 수행하는 메커니즘입니다. 특히 후자인 생성적 자기 회상(generative self-retrieval) 메커니즘은 내재적 위험을 수반합니다. 우리는 추론 과정에서 중간 사실을 환각(hallucination)으로 생성할 경우 최종 답변에서의 환각 발생 확률이 증가함을 입증했습니다. 마지막으로, 우리는 이러한 통찰력을 환각이 없는 사실적 진술을 포함하는 추론 궤적에 우선순위를 부여함으로써 모델의 정확도를 직접적으로 향상시키는 데 활용할 수 있음을 보여줍니다.
One-sentence Summary
Researchers from Google Research, Technion, and Tel Aviv University demonstrate that enabling reasoning in large language models expands parametric knowledge recall for simple questions through computational buffering and factual priming, while revealing that hallucinated intermediate facts significantly degrade final answer accuracy.
Key Contributions
- Enabling reasoning substantially expands the parametric knowledge recall boundary of large language models, unlocking correct answers for simple single-hop questions that are otherwise unreachable.
- Controlled experiments identify two driving mechanisms: a content-independent computational buffer effect and a content-dependent factual priming process where generating related facts acts as a semantic bridge for retrieval.
- A large-scale audit reveals that hallucinated intermediate facts increase the likelihood of final answer errors, while prioritizing hallucination-free reasoning trajectories at inference time significantly improves model accuracy.
Introduction
Reasoning in Large Language Models is well-established for complex tasks like math and coding, yet its value for simple, single-hop factual questions remains counterintuitive since these queries do not require logical decomposition. Prior research has largely focused on how reasoning aids multi-step problem solving or improves probability sharpening for already accessible answers, leaving a gap in understanding how it expands the model's fundamental parametric knowledge boundary. The authors demonstrate that enabling reasoning significantly unlocks correct answers that are otherwise unreachable by leveraging two distinct mechanisms: a content-independent computational buffer effect and a content-dependent factual priming process where the model generates related facts to bridge retrieval gaps. They further reveal that while this generative self-retrieval boosts accuracy, it introduces a risk where hallucinated intermediate facts increase the likelihood of final answer errors, a finding they use to propose inference strategies that prioritize hallucination-free reasoning trajectories.
Dataset
- Dataset Composition and Sources: The authors utilize a subset of the EntityQuestions dataset (Sciavolino et al., 2021), specifically focusing on 24 relations originally categorized by Gekhman et al. (2025).
- Subset Selection Criteria: From the original 24 relations, the team selected only 4 that meet two strict criteria: they must be "Hard to Guess" (where the answer space is large, such as person names) and "Well Defined" (where entity types and answer granularity are unambiguous).
- Data Structure and Processing: Each input sample consists of a question generated from a specific relation template paired with original facts provided as a summary.
- Model Usage: These curated relations serve as the foundation for evaluating the model's ability to handle complex, unambiguous entity queries rather than relying on common defaults.
Method
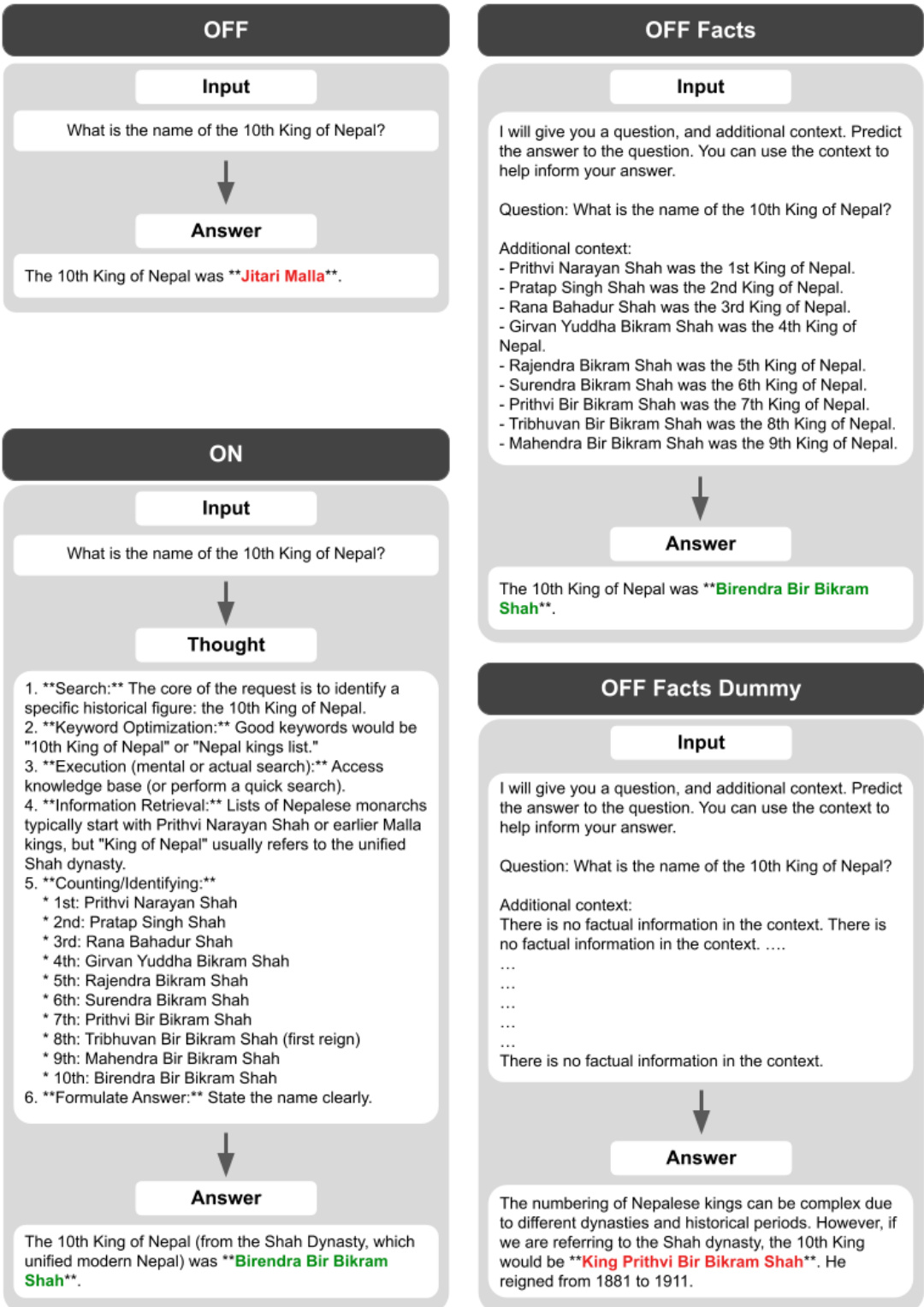
The proposed framework distinguishes between direct answer generation and reasoning-augmented generation. As illustrated in the first figure, the system operates in several modes: "OFF" (direct input to answer), "ON" (input to detailed thought process to answer), and variations involving "Dummy" thoughts which serve as placeholders or control conditions. In the "ON" mode, the model explicitly decomposes the query into steps such as identifying key entities, formulating search queries, and executing a search (simulated or actual) before stating the final answer.

The framework also incorporates scenarios where additional factual context is provided alongside the input question. The second figure demonstrates these variations, including "OFF Facts" where context is given but no thought process is generated, and "ON" where the model performs a detailed retrieval and counting process even when context is available. In the "ON" mode with facts, the reasoning trace includes steps for keyword optimization, information retrieval, and specific counting or identifying of entities (e.g., listing the 1st through 10th King of Nepal) to derive the answer.
Following the generation of these reasoning traces, a specific data processing module is employed to refine the extracted facts. Since reasoning traces often restate information already present in the question, the authors implement an LLM-based filtering step to remove such redundancies. This process utilizes a model (e.g., Gemini-2.5-Flash) to analyze the "Original Facts" against the input question. The filtering logic dictates that a fact is removed only if all the information it contains is explicitly stated in the question. Conversely, a fact is retained if it provides any new information, details, or context not found in the question, even if it partially repeats the question content.
Furthermore, specific rules are applied to prevent the model from simply memorizing the answer. A fact is removed if it states or implies that the target answer is the solution to the specific question. However, facts that mention the answer in an unrelated context or do not mention the answer at all are preserved. This ensures that the training data captures the reasoning path and external knowledge retrieval rather than just the final answer mapping.
Experiment
- Experiments using hybrid models with reasoning toggled ON or OFF on closed-book QA benchmarks demonstrate that reasoning consistently expands the model's parametric knowledge boundary, unlocking correct answers that remain unreachable without it, particularly at higher sampling depths.
- Analysis reveals that these gains are not primarily driven by decomposing complex multi-hop questions, as reasoning effectiveness remains similar for simple and complex question types, indicating the mechanism facilitates direct factual recall rather than task decomposition.
- Controlled tests validate two complementary mechanisms: a computational buffer effect where generating extra tokens enables latent computation independent of semantic content, and factual priming where recalling related facts creates a semantic bridge to the correct answer.
- Investigations into reasoning traces show that hallucinated intermediate facts systematically reduce the likelihood of a correct final answer, whereas traces containing verified factual statements significantly improve accuracy.
- Practical application of these findings through test-time selection strategies that prioritize traces with factual content and avoid hallucinations yields measurable improvements in model accuracy.