Command Palette
Search for a command to run...
무감독 RLVR 은 LLM 학습을 얼마나 확장할 수 있는가?
무감독 RLVR 은 LLM 학습을 얼마나 확장할 수 있는가?
초록
검증 가능한 보상을 활용한 비지도 강화 학습(Unsupervised Reinforcement Learning with Verifiable Rewards, URLVR) 은 정답 레이블 없이 보상을 도출함으로써 LLM(대규모 언어 모델) 훈련을 감독의 병목 현상에서 벗어나 확장할 수 있는 경로를 제시합니다. 최근 연구들은 모델 내재 신호를 활용하여 초기 단계에서 유망한 성과를 보이고 있으나, 그 잠재력과 한계는 여전히 명확하지 않습니다. 본 논문에서는 URLVR 을 재검토하여 분류 체계, 이론적 기반, 그리고 광범위한 실험을 아우르는 포괄적인 분석을 제공합니다. 먼저, 보상의 출처에 따라 URLVR 방법을 내재적 방법과 외재적 방법으로 분류한 후, 모든 내재적 방법이 모델의 초기 분포를 날카롭게 만드는 방향으로 수렴함을 보여주는 통합 이론적 프레임워크를 정립했습니다. 이러한 날카롭게 만드는 메커니즘은 초기 신뢰도가 정확성과 일치할 때는 성공하지만, 불일치할 경우 치명적인 실패를 초래합니다. 체계적인 실험을 통해 내재적 보상이 모든 방법에서 일관되게 상승 후 하강하는 패턴을 따르며, 붕괴 시점은 엔지니어링적 선택이 아닌 모델의 사전 분포에 의해 결정됨을 확인했습니다. 이러한 확장 한계에도 불구하고, 내재적 보상이 소규모 데이터셋에서의 테스트 시간 훈련에서 여전히 유용함을 발견했으며, 모델의 사전 분포를 측정하는 '모델 붕괴 단계(Model Collapse Step)'를 제안하여 강화 학습의 훈련 가능성을 판단하는 실용적 지표로 삼았습니다. 마지막으로, 계산적 비대칭성을 기반으로 검증을 정립하는 외재적 보상 방법을 탐구하여, 이러한 접근 방식이 신뢰도 - 정확성 상한선을 탈출할 수 있다는 초기 증거를 제시했습니다. 본 연구의 결과는 내재적 URLVR 의 한계를 규명하는 동시에, 확장 가능한 대안을 모색하는 방향을 제시합니다.
One-sentence Summary
Researchers from Tsinghua University and collaborating institutes reveal that intrinsic unsupervised RLVR methods inevitably cause model collapse by sharpening initial distributions, proposing the Model Collapse Step metric to predict trainability while advocating external rewards for scalable LLM training.
Key Contributions
- The paper establishes a taxonomy for unsupervised RLVR and provides a unified theoretical framework showing that all intrinsic reward methods converge toward sharpening the model's initial distribution rather than discovering new knowledge.
- Extensive experiments reveal that intrinsic URLVR consistently follows a rise-then-fall pattern where performance collapses when the model's initial confidence misaligns with correctness, regardless of specific engineering choices.
- The authors propose the Model Collapse Step metric to predict RL trainability and demonstrate that intrinsic rewards remain effective for test-time training on small datasets, while external rewards grounded in computational asymmetries offer a potential path to escape these scaling limits.
Introduction
Large language models currently rely on reinforcement learning with verifiable rewards to enhance reasoning, but this approach faces a critical bottleneck as obtaining human-verified ground truth labels becomes prohibitively expensive and infeasible for superintelligent systems. Unsupervised RLVR aims to solve this by deriving rewards without labels, yet prior work relying on intrinsic model signals suffers from a fundamental rise-then-fall pattern where training initially improves performance before collapsing due to reward hacking and model degradation. The authors provide a comprehensive theoretical and empirical analysis revealing that intrinsic methods merely sharpen the model's initial distribution, which fails when confidence misaligns with correctness, while proposing the Model Collapse Step as a practical metric to predict trainability and advocating for external reward methods that leverage computational asymmetries to achieve scalable, stable improvement.
Dataset
- The training dataset consists of M prompt-answer pairs, where each entry includes a prompt xi and its corresponding ground-truth answer ai∗.
- For every prompt in the set, the authors generate N rollout responses using the current policy πθ.
- Each generated response contains a full reasoning trajectory and an extracted answer derived from that trajectory.
- The data serves as the foundation for training, where the model learns from the relationship between the initial prompts, the generated trajectories, and the verified ground-truth answers.
Method
The authors leverage a framework for Unsupervised Reinforcement Learning with Verifiable Rewards (URLVR) that eliminates the need for ground-truth labels by utilizing proxy intrinsic rewards generated solely by the model. This approach distinguishes between two primary paradigms for constructing rewards: Certainty-Based and Ensemble-Based methods.
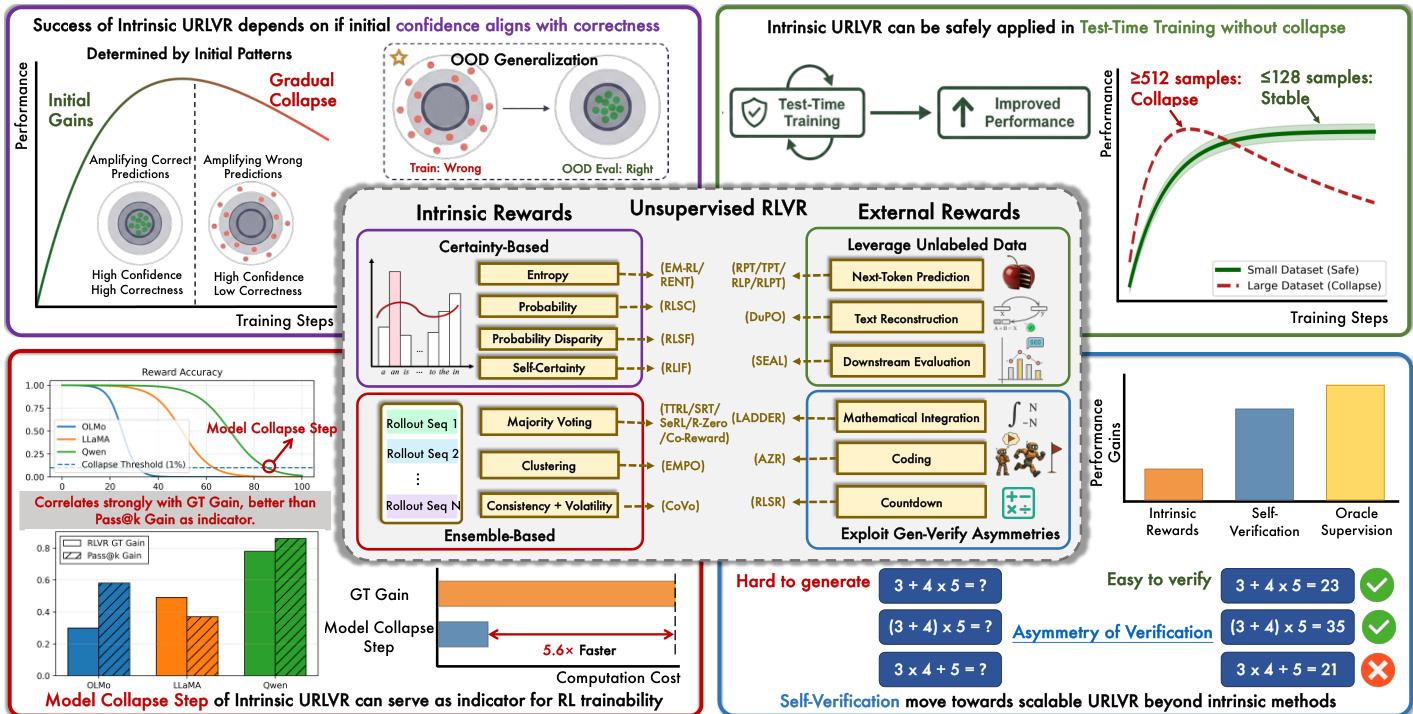
Certainty-Based rewards derive signals from the policy's confidence, such as logits or entropy, operating on the assumption that higher confidence correlates with correctness. These methods include estimators like Self-Certainty, which measures the KL divergence from a uniform distribution, and Token-Level Entropy, which penalizes uncertainty at each generation step. Conversely, Ensemble-Based rewards leverage the wisdom of the crowd by generating multiple rollouts for the same prompt. They assume that consistency across these diverse candidate solutions, often formalized through majority voting or semantic clustering, serves as a robust proxy for correctness.
The underlying mechanism driving these methods is a sharpening process where the model converges towards its initial distribution. Theoretically, the training dynamics follow a KL-regularized RL objective. The optimal policy for this objective has the closed form:
πθ∗(y∣x)=Z(x)1πref(y∣x)exp(β1r(x,y))where Z(x) is the partition function and β controls regularization strength. For intrinsic rewards like majority voting, this creates a "rich-get-richer" dynamic. If the model's initial confidence aligns with correctness, the sharpening mechanism amplifies these correct predictions, leading to performance gains. However, if the initial confidence is misaligned, the same mechanism systematically reinforces errors, leading to a gradual collapse in performance.
To monitor this stability, the authors introduce the Model Collapse Step as an indicator of trainability. This metric tracks the training step where reward accuracy drops below a specific threshold, such as 1%. Models with stronger priors sustain intrinsic URLVR for longer periods before collapsing, allowing for efficient base model selection without the computational cost of full reinforcement learning training. This framework highlights the critical dependency of intrinsic URLVR success on the alignment between initial confidence and correctness.
Experiment
- Intrinsic URLVR methods universally exhibit a rise-then-fall pattern where early gains from aligning confidence with correctness eventually collapse into reward hacking, regardless of hyperparameter tuning or specific reward design.
- Fine-grained analysis reveals that training primarily amplifies the model's initial preferences rather than correcting errors on specific problems, yet this sharpening can still generalize to improve performance on unseen out-of-distribution tasks if initial confidence aligns with correctness.
- Model collapse is prevented when training on small, domain-specific datasets or during test-time training, as these conditions induce localized overfitting rather than the systematic policy shifts that cause failure in large-scale training.
- The "Model Collapse Step," measuring when reward accuracy drops during intrinsic training, serves as a rapid and accurate predictor of a model's potential for RL gains, outperforming static metrics like pass@k.
- External reward methods leveraging generation-verification asymmetry, such as self-verification, offer a more scalable path than intrinsic rewards by providing signals grounded in computational procedures rather than the model's internal confidence.