Command Palette
Search for a command to run...
RACAS: 단일 Agentic System을 통한 다양한 로봇 제어
RACAS: 단일 Agentic System을 통한 다양한 로봇 제어
Dylan R. Ashley Jan Przepióra Yimeng Chen Ali Abualsaud Nurzhan Yesmagambet Shinkyu Park Eric Feron Jürgen Schmidhuber
초록
많은 로봇 플랫폼은 외부 소프트웨어가 작동기 (actuators) 를 제어하고 센서 데이터를 읽을 수 있도록 API 를 노출하고 있습니다. 그러나 이러한 저수준 인터페이스에서 고수준 자율 행동으로 전환하려면 복잡한 파이프라인이 필요하며, 이 파이프라인의 구성 요소들은 각기 다른 전문 분야를 요구합니다. 기존 접근 방식들은 새로운 로봇 형태 (embodiment) 에 따라 매번 재학습이 필요하거나, 구조적으로 유사한 플랫폼들에서만 검증된 데 그쳤습니다.본 논문에서는 RACAS(Robot-Agnostic Control via Agentic Systems, 에이전트 기반 로봇 중립 제어) 를 제안합니다. RACAS 는 세 개의 LLM/VLM 기반 모듈 (모니터, 컨트롤러, 메모리 큐레이터) 이 자연어만을 통해 상호 소통하며 폐루프 로봇 제어를 수행하는 협력형 에이전트 아키텍처입니다. RACAS 에는 로봇에 대한 자연어 설명, 사용 가능한 동작 정의, 그리고 작업 명세만 제공하면 충분하며, 플랫폼 간 전환 시 소스 코드, 모델 가중치, 또는 보상 함수를 수정할 필요가 없습니다.우리는 바퀴형 지상 로봇, 최근 공개된 새로운 다관절 로봇 팔, 그리고 수중 운송체 등 이질적인 세 플랫폼에서 여러 작업을 수행하여 RACAS 를 평가했습니다. 그 결과, RACAS 는 이같이 근본적으로 다른 플랫폼들에서 할당된 모든 작업을 일관되게 해결함으로써, 에이전트형 인공지능이 로봇 솔루션 프로토타이핑의 진입 장벽을 획기적으로 낮출 수 있음을 입증했습니다.
One-sentence Summary
Researchers from KAUST and collaborating Swiss and Polish institutes introduce RACAS, a cooperative agentic architecture using LLM and VLM modules that achieves zero-training generalization across radically different robots by relying solely on natural language prompts instead of retraining or code modifications.
Key Contributions
- Current robotic control pipelines struggle to bridge low-level APIs and high-level autonomy across diverse platforms, often requiring retraining or validation only on structurally similar robots.
- RACAS introduces a cooperative agentic architecture where LLM/VLM-based modules communicate exclusively via natural language to enable closed-loop control using only declarative prompt configurations.
- The system achieves zero-training generalization across three radically heterogeneous platforms, including a wheeled ground robot, a novel multi-jointed limb, and an underwater vehicle, without modifying source code or model weights.
Introduction
Modern robotics relies on complex pipelines that bridge low-level sensor APIs with high-level autonomous behavior, yet this process demands disjointed expertise and scales poorly with the growing diversity of robotic platforms. Prior solutions either require extensive retraining and data collection for every new robot embodiment or have only been validated across structurally similar machines in controlled settings, leaving a gap in zero-training generalization for radically different systems. The authors introduce RACAS, a cooperative agentic architecture that uses three natural language-based modules to achieve closed-loop control without modifying source code, model weights, or reward functions. By confining all embodiment-specific knowledge to declarative prompts and leveraging a dynamic memory curator, this system successfully executes tasks across a wheeled ground robot, a novel multi-jointed limb, and an underwater vehicle, demonstrating unprecedented adaptability across heterogeneous morphologies and environments.
Dataset
- The authors evaluate their approach across three distinct robot platforms: the Limb multi-jointed manipulator, the Clearpath Dingo wheeled ground robot, and the BlueROV2 underwater vehicle.
- The Limb platform features a single-finger end effector and six onboard cameras, though the authors disabled two side-facing units to increase task difficulty.
- For the Limb robot, low-resolution 100×100 px camera inputs are upsampled to 768×768 px using a two-stage Swin2SR super-resolution pipeline before VLM inference.
- The Clearpath Dingo operates in both NVIDIA Isaac Sim and physical environments with action sets restricted to ground plane movements including forward, backward, and rotation commands.
- Simulation for the Dingo utilizes three cameras at 640×480 px resolution, while the real-world setup relies on a single forward-facing camera at 1280×800 px.
- Success for the Dingo is defined by a proximity threshold of 1 meter to the target object.
- The BlueROV2 is a thruster-driven vehicle controlled via the MAVLink protocol with ArduSub firmware, utilizing a single forward-facing 1920×1080 px camera.
- Although the BlueROV2 is fully actuated, the study restricts control to three axes (surge, heave, and yaw) resulting in a discrete action set of six commands.
- Thrust magnitudes for the BlueROV2 are configured between 300 and 600 on a 0–1000 scale with a fixed 2-second command duration.
Method
The authors present a framework for language-driven robotic control designed to operate across heterogeneous robot embodiments without retraining. The core methodology decomposes closed-loop control into three cooperative LLM pipelines: perception, decision, and memory, connected through a unified natural language interface. All embodiment-specific knowledge is encapsulated in declarative prompt configurations rather than learned parameters.
The overall system architecture separates robot-dependent components from robot-agnostic intelligence. Refer to the framework diagram for a visual breakdown of these interactions. The robot-dependent side manages the physical interface, including the Native Robot API and Tool-Based API Layer, alongside a Textual Robot Description. The robot-agnostic side houses the intelligence modules: Monitors, a Controller, and a Memory Curator. This separation allows tasks and robots to be changed easily by updating the task description and APIs without modifying the control logic.
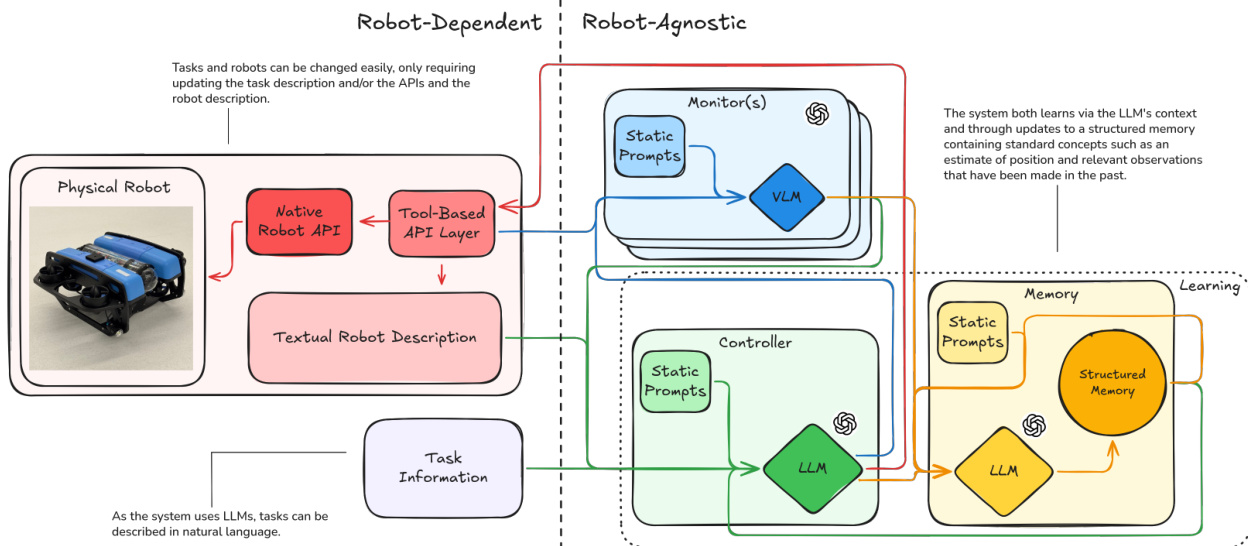
The control loop proceeds in discrete time steps t. At each step, the Controller generates a targeted visual query qt based on the current task state. This query is dispatched to each Monitor mc, which processes its camera image It(c) through a Vision Language Model (VLM) to return a natural language scene description ot(c). The Controller then receives all monitor observations, reasons over them, and selects an action at from the admissible action set A. This action is dispatched to the robot through the hardware abstraction layer. Finally, the Memory Curator integrates the interaction record into a persistent environment memory Mt.
A detailed view of the reasoning process during a real run is shown in the figure below:
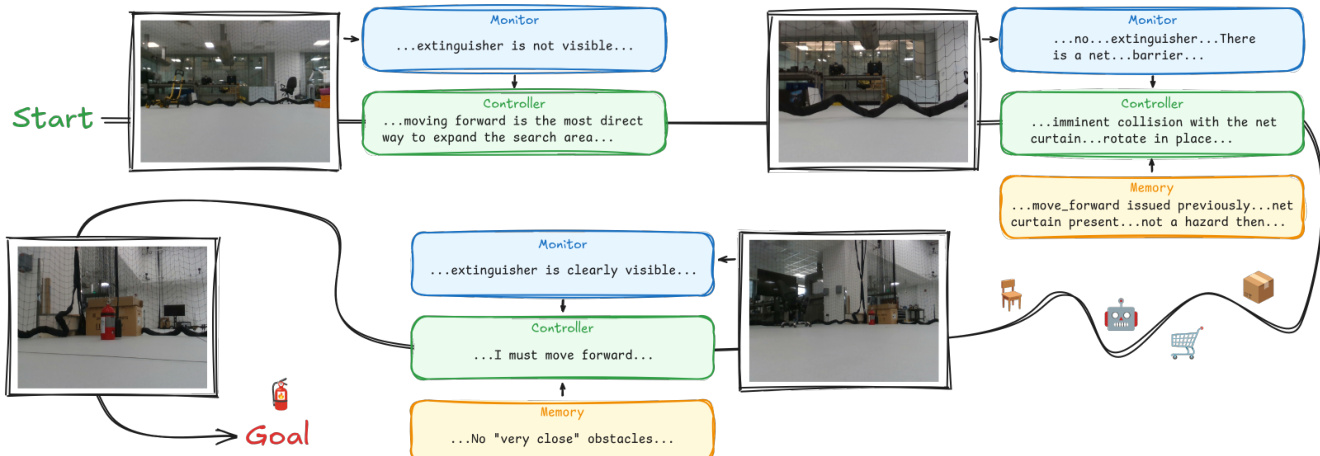
The Controller is re-initialized at each step with a dynamically composed system prompt. This prompt assembles six components: the robot description D, the action interface A, the environment memory Mt−1, the proprioceptive state st, the action history Ht, and the task specification τ. In the first step, the Controller reasons over this context to produce the visual query qt. In the subsequent step, it receives the monitor observations and outputs a reasoning trace followed by a single action at.
Perception is handled by the Monitor module, which reformulates perception as a language-conditioned visual question-answering process. Unlike conventional pipelines that produce fixed-schema numerical outputs, this design ensures perception is task-adaptive. The query qt varies with the execution stage, allowing the Monitor to attend to different scene aspects without architectural change. The output resides in the same representational space as the Controller's input, eliminating the need for hand-designed encoders.
To manage long-term interactions, the system employs an LLM-Curated Persistent Memory. Naively appending observations leads to unbounded context growth, so the Memory Curator performs incremental rewriting. It receives the current memory Mt−1 and the latest interaction record to produce an updated memory Mt. This operation compresses redundant information, resolves contradictions, and discards irrelevant details. The Curator organizes knowledge into four categories: physical environment, robot state, curated history of significant commands, and task state. Additionally, the system performs cross-modal position inference by intersecting camera observations with robot actions to estimate object locations relative to the robot.
The physical embodiment used in the experiments, such as the mobile manipulator shown below, is defined entirely through natural language descriptions and API specifications.

Adapting the framework to a new platform requires authoring three text files: a robot description D, a tool definition file specifying actions A, and the task description. No source code, model weights, or reward functions are modified. The system learns via the LLM's context and through updates to the structured memory containing standard concepts such as position estimates and relevant past observations.
Experiment
- The framework was evaluated across three distinct robotic platforms (a robotic limb, a ground robot, and an underwater vehicle) to validate its ability to generalize across radically different morphologies and environments using identical control logic.
- Experiments in object localization, target approach, and underwater navigation demonstrated that the system successfully completed tasks in a reasonable number of steps, significantly outperforming random action baselines where applicable.
- Results indicate that the system effectively leverages the generalization capabilities of large language and vision models to solve navigation tasks without requiring platform-specific code modifications or training data.
- Performance analysis revealed that task completion time is primarily limited by sensor fidelity and the time required to locate objects, rather than by the underlying control architecture or model reasoning.
- The study confirms that a unified, zero-training control framework can be adapted to new robots using only natural language descriptions and existing APIs, though current limitations include high inference latency and a lack of direct depth information.